FAQ
Développement et tests
Comment corriger une erreur « TabError: inconsistent use of tabs and spaces in indentation » ?
Cette erreur est plus subtile car la plupart du temps invisible avec les paramètres standard des éditeurs de texte.
Considérons l’exemple ci dessous:
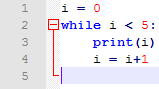
Ce code a l’air visuellement correct, cependant à l’exécution une erreur se produit:
> python indent.py
File "indent.py", line 4
i = i+1
^
TabError: inconsistent use of tabs and spaces in indentation
Il faut modifier les paramètres de l’éditeur de façon à visualiser les espaces/tabulations. Dans Notepad++, ça se passe dans le menu View > Show Symbol > Show White Space and TAB.
Il apparait alors clairement que même si visuellement les deux lignes du bloc while sont alignées, les symboles utilisés pour cet alignement ne sont pas identiques:
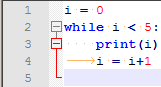
Le plus efficace est de paramétrer l’éditeur de texte pour qu’il remplace chaque caractère de tabulation par des espaces. Dans Notepad++, ça se passe dans le menu Settings > Preferences... > Tab Settings > Replace by space.
Il faut s’assurer que les caractères utilisés pour l’indentation sont tous identiques
Les chaînes de caractère
Comment remplacer les caractères accentués d’une chaîne de caractères par leurs équivalents non accentués ?
Lors de certaines manipulations de chaînes de caractères, il peut être nécessaire de remplacer les caractères accentués à, é, è, ê, ... par leur équivalent non accentués a, e, e, e,....
L’utilisation de la méthode de chaîne translate() apporte une réponse élégante à ce problème. Il suffit de lui passer une table de conversion créée avec la méthode statique str.maketrans() qui prend ici en argument deux chaînes de caractères:
>>> before = 'àéèêîôù'
>>> after = 'aeeeiou'
>>> translation_table = str.maketrans(before, after)
>>> "la maîtresse d'école est à l'hôpital".translate(translation_table)
"la maitresse d'ecole est a l'hopital"
Comment supprimer tous les signes de ponctuation d’une chaîne de caractères ?
Lors de certaines manipulations de chaînes de caractères, il peut être nécessaire de supprimer les signes de ponctuation : , ; : . etc.
On peut utiliser la méthode de chaîne translate() à laquelle on passe une table de conversion créée avec la méthode statique str.maketrans() qui prend ici en argument un dictionnaire:
>>> translation_table = str.maketrans({',':None, ';':None, '.':None})
>>> "Demain, dès l'aube, à l'heure où blanchit la campagne, je partirai.".translate(translation_table)
"Demain dès l'aube à l'heure où blanchit la campagne je partirai"
La liste des signes de ponctuation est stockée dans string.punctuation:
>>> import string
>>> print(string.punctuation)
!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
On peut donc construire facilement un dictionnaire de translation pour l’ensemble des signes de ponctuation:
>>> import string
>>> d = {key: None for key in string.punctuation}
>>> translation_table = str.maketrans(d)
>>> s = "Demain, dès l'aube, à l'heure où blanchit la campagne, je partirai."
>>> s.translate(translation_table)
'Demain dès laube à lheure où blanchit la campagne je partirai'
Les listes
Comment récupérer l’indice des éléments lorsqu’on itère sur une liste ?
Contrairement à des langages plus bas niveau, Python itère sur les éléments de la liste, pas sur les indices. C’est le plus souvent suffisant mais lorsque l’accès à l’indice s’avère nécessaire, la fonction enumerate() est utilisée:
>>> l = [1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144]
>>> for indice, elt in enumerate(l):
... print(indice, elt)
...
0 1
1 1
2 2
3 3
4 5
5 8
6 13
7 21
8 34
9 55
10 89
11 144
Les fichiers
Comment lire de façon structurée un fichier csv ?
L’utilisation de la méthode statique csv.reader() permet de lire le fichier en stockant chaque ligne dans une liste de chaînes de caractère. Considérons le fichier Data/RolandGarros2016.csv contenant les résultats des derniers tours du tournoi ATP Roland Garros 2016:
>>> import csv
>>> with open('RolandGarros2016.csv', 'r') as f:
... r = csv.reader(f, delimiter=';')
... l = list(r)
...
>>> print(l[0])
['Round', 'Winner', 'Loser', 'WRank', 'LRank', 'Wsets', 'Lsets']
>>> print(l[-1])
['The Final', 'Djokovic N.', 'Murray A.', '1', '2', '3', '1']
Structurer l’information demande une étape supplémentaire. On peut alors préférer utiliser la classe DictReader qui lit chaque ligne du fichier et la stocke dans un dictionnaire en une seule opération. Les clés du dictionnaire sont fournies par l’en tête du fichier.
>>> with open('RolandGarros2016.csv', 'r') as f:
... r = csv.DictReader(f, delimiter=';')
... l = list(r)
...
>>> print(l[-1])
{'Winner': 'Djokovic N.', 'LRank': '2', 'Round': 'The Final', 'Loser': 'Murray A.', 'WRank': '1', 'Lsets': '1', 'Wsets': '3'}
Les dictionnaires
Comment créer un dictionnaire dont les valeurs sont des listes ?
Si on veut construire un dictionnaire en utilisant une liste comme valeur, se pose le problème du 1er accès. Si la clé n’existe pas, il faut créer une liste vide, si la clé existe déjà il faut ajouter une valeur à la liste existante. Considérons l’exemple suivant qui s’intéresse aux 40 villes les plus peuplées du monde. L’objectif est de construire un dictionnaire qui regroupe ces villes par pays :
1# source : https://www.populationdata.net/palmares/villes/
2
3data = [ ("Delta de la Rivière des Perles","Hong Kong"),
4 ("Tokyo","Japon"),
5 # données supprimées pour l'affichage...
6 ("Shenzhen","Chine")]
7
8d1 = dict()
9for value, key in data:
10 if key not in d1.keys():
11 d1[key] = list()
12 d1[key].append(value)
13
14key = 'Chine'
15print(key, d1[key])
Les lignes surlignées gèrent le cas particulier du premier accès, lorsque la clé n’existe pas encore. Ce code produit bien un dictionnaire dont les valeurs sont des listes
Chine ['Shanghai', 'Beijing', 'Chongqing', 'Chengdu', 'Guangzhou', 'Tianjin', 'Shenzhen']
Le module collections apporte une réponse plus compacte avec la classe defaultdict qui comporte une default_factory que l’on passe en paramètre au moment de l’instanciation. Lorsqu’on fait un appel à une clé qui n’existe pas, plutôt que de lever une exception, la default_factory est alors invoquée:
from collections import defaultdict
d2 = defaultdict(list)
for value, key in data:
d2[key].append(value)
La default_factory est une fonction qui retourne un objet. Cette fonction est passée en argument d’une autre fonction. Ceci est un (tout) petit aperçu de la programmation fonctionnelle.
L’exemple ci dessus utilise la classe list dans la default_factory. On peut également utiliser str, int, … comme le montre l’exemple ci dessous:
>>> dds = defaultdict(str)
>>> dds
defaultdict(<class 'str'>, {})
>>> dds['une_cle']
''
>>> dds['une_cle'] = 'hello'
>>> dds
defaultdict(<class 'str'>, {'une_cle': 'hello'})
>>> ddi = defaultdict(int)
>>> ddi['une_cle']
0
>>> ddi['une_cle'] += 1
>>> ddi
defaultdict(<class 'int'>, {'une_cle': 1})
L’utilisation de defaultdict doit être envisagée dès lors qu’il s’agit de manipuler des clés dont on ignore si elles existent ou non. Au moment du traitement, si la clé n’existe pas, elle est créée. Si elle existe, elle est modifiée.
D’un point de vue programmation objet, defaultdict est une sous classe de dict et hérite donc de son comportement (le concept est détaillé dans le chapitre sur les classes). Concrètement, toutes les opérations sur les dictionnaires sont applicables indifféremment aux dict et aux defaultdict.
Comment corriger une erreur « IndentationError: unexpected indent » ?
Contrairement à Java pour lequel l’indentation n’a pas d’autre utilité que la lisibilité du code, Python fait d’une pierre deux coups et utilise d’abord l’indentation pour la structuration du langage ce qui rend le code lisible de facto. La contrepartie est qu’une erreur dans l’indentation provoque l’arrêt du programme.
Une telle erreur est provoquée lorsque les lignes de code appartenant à un même bloc logique ne sont pas indentées avec les mêmes caractères. Dans le code ci dessous, les deux lignes du bloc
whilene sont pas alignées…Un exemple dans l’interpréteur Python:
Le même code exécuté à partir d’un fichier provoque évidemment la même erreur:
Il faut s’assurer que toutes les lignes appartenant à un même bloc logique soit indentées de façon identique