4. Architecture de données
4.1. Introduction
De nos jours, les données sont devenues l’un des actifs les plus précieux des organisations. Elles jouent un rôle crucial dans la prise de décisions stratégiques, l’optimisation des opérations et l’obtention d’un avantage concurrentiel. Dans ce contexte, l’ingénierie des données est une discipline clé qui supervise l’ensemble du processus, depuis la collecte jusqu’à la transformation, le stockage et la mise à disposition des données.
À l’ère du Big Data, les entreprises ne doivent pas seulement posséder des données, elles doivent aussi les interpréter, les rendre accessibles et les intégrer dans des systèmes d’aide à la décision. À mesure que le volume, la diversité et les cas d’usage des données augmentent, les organisations se tournent vers des architectures capables de répondre à divers besoins. Dans ce cadre, des stratégies de gestion des données telles que le Data Warehouse, le Data Lake, le Data Lakehouse et le Data Mesh jouent un rôle important.
Chaque approche propose des solutions différentes en matière de type de données, de modèle d’accès, d’exigences de performance, de structure organisationnelle et de politiques de gouvernance. Les Data Warehouses sont centrés sur les données structurées, tandis que les Data Lakes offrent une structure plus souple pour le stockage de gros volumes de données. Le Data Lakehouse, quant à lui, combine les avantages des deux, en créant un environnement optimisé pour l’analyse de données. Le Data Mesh, de son côté, vise à décentraliser la gestion des données à l’aide d’architectures microservices, permettant une répartition plus efficace des responsabilités liées aux données dans les grandes organisations.
Cependant, les fondations d’une architecture de données réussie doivent être posées dès le début du processus de conception. Il ne s’agit pas seulement de construire une structure technique, mais aussi de l’aligner sur les objectifs organisationnels et les stratégies de gestion des données.
4.2. Choix de l’architecture
La conception de l’architecture de données est une étape cruciale. Elle définit comment les données seront traitées. Une architecture adaptée facilite le flux, l’intégration, le stockage et l’accès aux données.
Le choix de l’approche en matière d’architecture de données dépend des objectifs du projet, des types de données et de leur usage prévu. Chaque approche présente ses avantages et ses inconvénients. Il est donc essentiel d’examiner les caractéristiques fondamentales de chaque méthode et de comprendre dans quelles conditions elles sont les plus pertinentes.

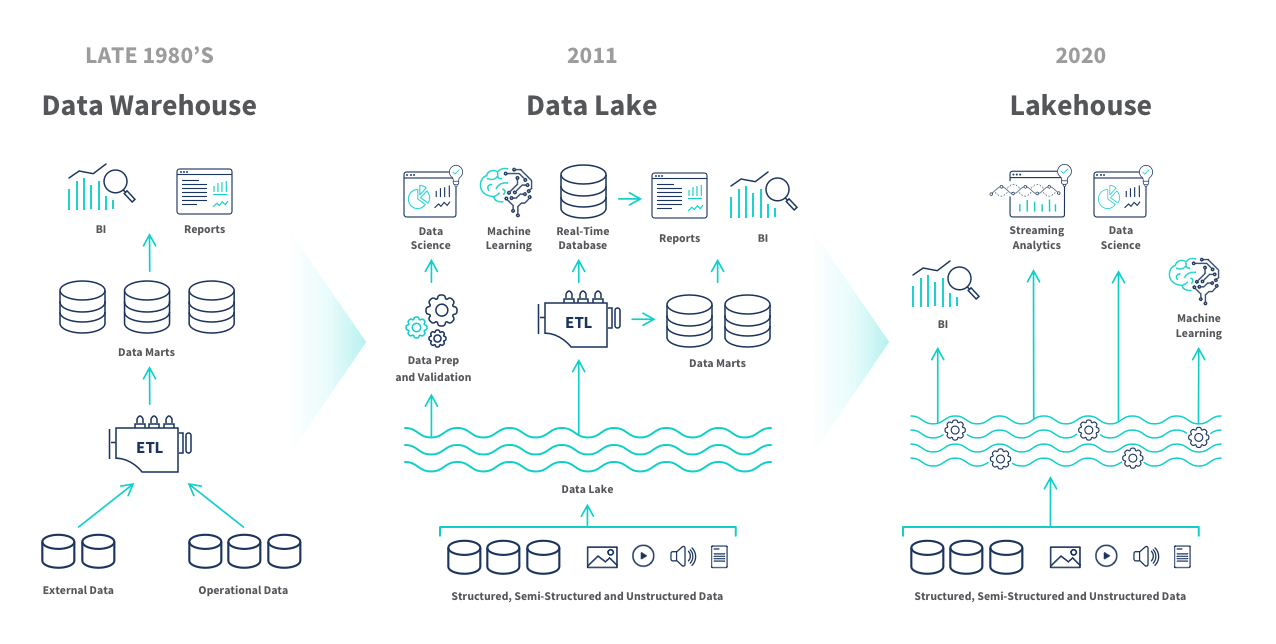
4.2.1. Data Warehouse
Le Data Warehouse est une architecture centralisée conçue pour stocker des données structurées, généralement issues de différentes sources opérationnelles. Ces données sont nettoyées, transformées et intégrées dans un modèle cohérent qui permet de réaliser des analyses rapides et précises.
Avantages :
Idéal pour les rapports BI et les tableaux de bord.
Structure bien définie (modèle en étoile ou en flocon).
Haute performance pour les requêtes analytiques.
Inconvénients :
Moins adapté aux données non structurées ou semi-structurées.
Moins flexible lors de changements de schéma.
Coût et temps de mise en oeuvre potentiellement élevés.
Principales plateformes :
4.2.2. Data Lake
Le Data Lake est un réservoir de données qui stocke de grandes quantités d’informations dans leur format brut, y compris des données structurées, semi-structurées et non structurées.
Avantages :
Très flexible.
Capable de stocker tout type de données.
Idéal pour l’analyse exploratoire, le Machine Learning et les cas d’usage de Big Data.
Inconvénients :
Structure de données plus difficile à gérer (risque de « data swamp »).
Nécessite des compétences avancées pour l’analyse.
Moins adapté pour les utilisateurs métier non techniques.
Principales plateformes :
4.2.3. Data Lakehouse
Le Data Lakehouse combine les atouts du Data Lake (stockage de données hétérogènes à bas coût) et ceux du Data Warehouse (structuration et performance pour l’analyse).
Avantages :
Flexibilité du Data Lake avec performance d’analyse proche du Data Warehouse.
Gestion des données structurées et semi-structurées dans un même environnement.
Réduction des redondances et meilleure cohérence.
Inconvénients :
Technologie relativement récente, pas encore totalement mature dans tous les environnements.
Complexité de mise en oeuvre intermédiaire.
Principales plateformes
4.2.4. Comparaison
Attributes |
Data Warehouse |
Data Lake |
Data Lakehouse |
|---|---|---|---|
Overview |
Données transformées et structurées |
Données brutes |
Un compromis des deux précédents. |
Data Format |
Closed proprietary format |
Open format |
Open format |
Type of Data |
Données structurées |
Données non, semi, ou pleinement structurées |
Données non, semi, ou pleinement structurées |
Data Access |
SQL only |
SQL, R, Python, … |
SQL, API extensions |
Reliability |
High quality (ACID) |
Low quality |
High quality (ACID) |
Governance and Security |
at the row/column level |
at the row/column level |
at the row/column level |
Scalability |
coût exponentiel |
coût réduit |
coût réduit |
Streaming |
Limité |
Oui |
Oui |
Query Engine |
Oui |
Non |
Non |
4.2.5. Data Mesh
Le Data Mesh est une approche décentralisée qui vise à répartir la responsabilité de la gestion des données à travers des équipes orientées « produits ». Chaque domaine gère ses propres données en tant que produit, dans une logique de microservices.
Avantages :
Scalabilité organisationnelle.
Autonomie des équipes.
Données proches des besoins métiers.
Inconvénients :
Complexité de gouvernance.
Besoin d’une forte culture data au sein de chaque domaine.
Nécessite une coordination solide entre équipes.
4.2.6. Mise en oeuvre de l’architecture de données
Une fois l’architecture choisie et conçue, la phase suivante est sa mise en oeuvre. Cela implique la création des structures physiques et logiques nécessaires pour intégrer, stocker, transformer et exploiter les données.
Étapes clés de la mise en oeuvre
définir le modèle de données
création des schémas, tables, clés primaires et étrangères.
conception selon un modèle en étoile ou en flocon (star/snowflake schema), adapté à la BI.
Créer les scripts ETL
définir les étapes d’extraction des fichiers CSV provenant de l’ERP et du CRM.
nettoyer les données : gestion des valeurs manquantes, des doublons, et des erreurs de format.
transformer les données pour correspondre au modèle défini (formats de dates, clés de jointure, normalisation…).
charger les données nettoyées dans l’architecture choisie
Automatiser les processus
utiliser des outils de pipeline ETL/ELT (Python/SQL)
mettre en place une exécution automatique
Optimiser les performances
indexer les colonnes utilisées pour les jointures et les filtres.
mettre en place des partitions si les volumes de données sont élevés.
vérifier les plans d’exécution SQL pour détecter les requêtes lentes.
Documentation technique et fonctionnelle
décrire chaque table, champ, règle de transformation et logique métier.
fournir un guide d’utilisation pour les analystes, les utilisateurs métier et les développeurs.
Cette documentation garantit la pérennité du système et facilite la formation des nouveaux arrivants.
Tests et validation
vérifier l’exactitude des données chargées : total des ventes, correspondance des identifiants client/produit, etc.
réaliser des tests de non-régression à chaque changement du pipeline.
obtenir la validation des parties prenantes métier avant mise en production.
4.3. Conclusion
Une bonne architecture de données commence par une bonne compréhension des besoins. La mise en place d’une architecture de données efficace ne repose pas uniquement sur des choix technologiques ou des compétences en ingénierie. Elle repose avant tout sur une analyse approfondie des besoins métier, une collaboration étroite avec les parties prenantes, et une vision claire des objectifs à atteindre.
Les entreprises qui réussissent leurs projets data sont celles qui prennent le temps de :
comprendre la nature de leurs données et leurs usages,
choisir une architecture adaptée (Data Warehouse, Data Lake, Lakehouse, ou Data Mesh),
concevoir un modèle logique et robuste,
documenter et maintenir leur système dans la durée.
Dans un environnement où les données sont de plus en plus nombreuses, hétérogènes et stratégiques, une architecture bien pensée permet non seulement de gagner en efficacité opérationnelle, mais aussi de créer un avantage concurrentiel durable.