2. Les graphiques
L’interaction avec les graphiques dans un navigateur web nécessite l’utilisation du langage JavaScript. plotly.js est la bibliothèque de base développée dans ce langage. Elle est open source (cf le dépôt GitHub). Les graphiques sont générés dans un format JSON.
Un éditeur en ligne permet de générer des figures à partir de données que l’on peut uploader. C’est un outil intéressant qui permet une interaction dynamique avec les graphiques.
La communauté Data Science utilise essentiellement R et Python, et un wrapper a été développé pour ces deux langages. Nous nous focaliserons ici sur le wrapper Python. Mais l’utilisation d’une seule et même bibliothèque graphique dans les deux langages présente un très grand intérêt, et est une alternative sérieuse à R/ggplot2/shiny.
2.1. Installation de Plotly
Plotly s’installe classiquement avec pip:
$ python -m pip install plotly
Si une version antérieure est déjà installée:
$ python -m pip install plotly --upgrade
Les exemples ci dessous utilisent la version 5.10.0.
2.2. Dataset
Le dataset Gapminder est un grand classique pour illustrer les principes des bibliothèques graphiques. Le fichier gapminder.csv compile plusieurs données utilisées dans la vidéo de Hans Rosling :
pays
année
population globale
continent
espérance de vie à la naissance
le PIB par habitant
la mortalité infantile (pour mille naissances)
le nombre d’enfant par femme
Le dataset est transformé en une dataframe pandas:
>>> import pandas as pd
>>> df = pd.read_csv('gapminder.csv')
>>> type(df)
<class 'pandas.core.frame.DataFrame'>
Pour vérifier la validité de l’opération, on affiche la data frame :
>>> df country year pop continent lifeExp gdpPercap mortality fertility 0 Afghanistan 1952 8425333.0 Asia 28.801 779.445 NaN 7.671 1 Afghanistan 1957 9240934.0 Asia 30.332 820.853 NaN 7.671 2 Afghanistan 1962 10267083.0 Asia 31.997 853.101 236.3 7.671 3 Afghanistan 1967 11537966.0 Asia 34.020 836.197 217.0 7.671 4 Afghanistan 1972 13079460.0 Asia 36.088 739.981 198.2 7.671 ... ... ... ... ... ... ... ... ... 1675 Zimbabwe 1987 9216418.0 Africa 62.351 706.157 50.4 5.784 1676 Zimbabwe 1992 10704340.0 Africa 60.377 693.421 54.5 4.840 1677 Zimbabwe 1997 11404948.0 Africa 46.809 792.450 62.7 4.240 1678 Zimbabwe 2002 11926563.0 Africa 39.989 672.039 62.7 4.018 1679 Zimbabwe 2007 12311143.0 Africa 43.487 469.709 59.9 3.903[1680 rows x 8 columns]
La méthode describe() donne un aperçu statistique du contenu.
>>> df.describe()
year pop lifeExp gdpPercap mortality fertility
count 1680.000000 1.680000e+03 1680.000000 1680.000000 1458.000000 1680.000000
mean 1979.500000 2.998615e+07 59.323095 7167.495338 68.506107 4.641047
std 17.265402 1.068643e+08 12.910554 9846.073969 54.043530 2.078144
min 1952.000000 6.001100e+04 23.599000 241.166000 2.200000 1.100000
25% 1965.750000 2.829359e+06 48.077250 1189.067750 21.225000 2.570750
50% 1979.500000 7.271770e+06 60.386500 3474.232000 57.350000 5.069500
75% 1993.250000 1.994372e+07 70.796250 9316.721250 105.750000 6.536750
max 2007.000000 1.318683e+09 82.603000 113523.133000 273.200000 9.185000
On extrait la colonne des années, qui est une Series :
>>> years = df['year']
>>> type(years)
<class 'pandas.core.series.Series'>
On en extrait les valeurs uniques avec la méthode unique(). Elles sont stockées dans un numpy.array:
>>> years = years.unique()
>>> type(years)
<class 'numpy.ndarray'>
On effectue la même opération avec les continents:
>>> continents = df['continent']
>>> type(continents)
<class 'pandas.core.series.Series'>
>>> continents = continents.unique()
>>> type(continents)
<class 'numpy.ndarray'>
On crée un sous ensemble de données:
>>> year = 1992
>>> continent = 'Asia'
>>> asia1992 = df.query("continent=='Asia' and year==1992")
>>> type(asia1992)
<class 'pandas.core.frame.DataFrame'>
Jetons un oeil aux données pour vérifier que l’opération de sélection est valide:
>>> asia1992
country year pop continent lifeExp gdpPercap mortality fertility
8 Afghanistan 1992 1.631792e+07 Asia 41.674 649.341 114.4 7.725
92 Bahrain 1992 5.294910e+05 Asia 72.601 19035.579 18.7 3.466
104 Bangladesh 1992 1.137046e+08 Asia 56.018 837.810 92.1 4.197
224 Cambodia 1992 1.015009e+07 Asia 55.803 682.303 85.7 5.240
296 China 1992 1.164970e+09 Asia 68.690 1655.784 41.2 2.171
692 India 1992 8.720000e+08 Asia 60.223 1164.407 83.9 3.709
704 Indonesia 1992 1.848160e+08 Asia 62.681 2383.141 57.4 2.931
716 Iran 1992 6.039797e+07 Asia 65.742 7235.653 40.8 4.137
728 Iraq 1992 1.786190e+07 Asia 59.461 3745.641 40.8 5.699
752 Israel 1992 4.936550e+06 Asia 76.930 18051.523 8.7 2.952
788 Japan 1992 1.243293e+08 Asia 79.360 26824.895 4.4 1.499
800 Jordan 1992 3.867409e+06 Asia 68.015 3431.594 28.3 5.169
824 Korea Dem. Rep. 1992 2.071138e+07 Asia 69.978 3726.064 41.1 2.235
836 Korea Rep. 1992 4.380545e+07 Asia 72.244 12104.279 5.5 1.650
848 Kuwait 1992 1.418095e+06 Asia 75.190 34932.920 14.0 2.144
860 Lebanon 1992 3.219994e+06 Asia 69.292 6890.807 24.7 2.841
932 Malaysia 1992 1.831950e+07 Asia 70.693 7277.913 13.0 3.454
992 Mongolia 1992 2.312802e+06 Asia 61.271 1785.402 70.7 3.451
1040 Myanmar 1992 4.054654e+07 Asia 59.320 347.000 74.6 3.158
1064 Nepal 1992 2.032621e+07 Asia 55.727 897.740 88.9 5.004
1148 Oman 1992 1.915208e+06 Asia 71.197 18616.707 26.8 6.472
1160 Pakistan 1992 1.200650e+08 Asia 60.838 1971.829 102.5 5.767
1208 Philippines 1992 6.718577e+07 Asia 66.458 2279.324 37.3 4.177
1292 Saudi Arabia 1992 1.694586e+07 Asia 68.768 24841.618 30.3 5.522
1340 Singapore 1992 3.235865e+06 Asia 75.788 24769.891 5.0 1.720
1412 Sri Lanka 1992 1.758706e+07 Asia 70.379 2153.739 18.2 2.390
1472 Syria 1992 1.321906e+07 Asia 69.249 3340.543 28.0 4.925
1484 Taiwan 1992 2.068692e+07 Asia 74.260 15215.658 5.0 1.730
1508 Thailand 1992 5.666710e+07 Asia 67.298 4616.897 27.3 2.003
1628 Vietnam 1992 6.994073e+07 Asia 67.662 989.023 34.3 3.255
1640 West Bank and Gaza 1992 2.104779e+06 Asia 69.718 6017.655 32.7 6.539
1652 Yemen Rep. 1992 1.336800e+07 Asia 55.599 1879.497 84.4 8.311
La première colonne est l’index correspondant au dataset original.
2.3. Création d’un graphique élémentaire
Un graphique plotly est un objet Figure comprenant a minima deux attributs:
data: une séquence de traces contenant les données à afficher. Ex : [Scatter(...),Bar(...)]layout: un dictionnaire de paires clé/valeur déterminant titre, légende, axes, etc…
Construire un graphique consiste donc à construire ces deux attributs. On choisit ici d’afficher les données sous la forme d’un scatter plot.
Pour alléger le code, on importe la sous bibliothèque nécessaire avec un alias
import plotly.graph_objects as go
On construit la trace avec l’objet Scatter. Ici seuls 3 paramètres sont passés au constructeur:
trace = go.Scatter( x=asia1992['mortality'],
y=asia1992['fertility'],
mode='markers' )
Tip
D’après la documentation, “the ‘mode’ property is a flaglist and may be specified as a string containing any combination of [‘lines’, ‘markers’, ‘text’] joined with ‘+’ characters (e.g. ‘lines+markers’)”.
Toujours conformément à la documentation, la propriété data doit être une séquence de traces. Ici la séquence est une liste composée d’un seul élément:
data = [trace]
L’aspect général du graphique est géré par l’objet Layout, pour lequel on précise:
La forme générale (simplifiée) d’un objet Layout est la suivante
layout = go.Layout( title=Title(),
xaxis=XAxis(),
yaxis=YAxis() )
La figure est construite avec
fig = go.Figure(data=data, layout=layout)
puis exportée sur le disque local avec
from plotly.io import write_html
write_html(fig, file='fig.html', auto_open=False, include_plotlyjs='cdn')
Tip
Le paramètre include_plotlyjs='cdn' permet de faire un lien dynamique avec la bibliothèque plotly.js. Par défaut, celle ci est insérée localement dans chaque fichier généré, ce qui augmente considérablement la taille des figures (+ 3Mb ~).
Elle est ensuite visible dans un navigateur web standard.
2.3.1. Le graphique à obtenir
Le graphique est présenté ci dessous :
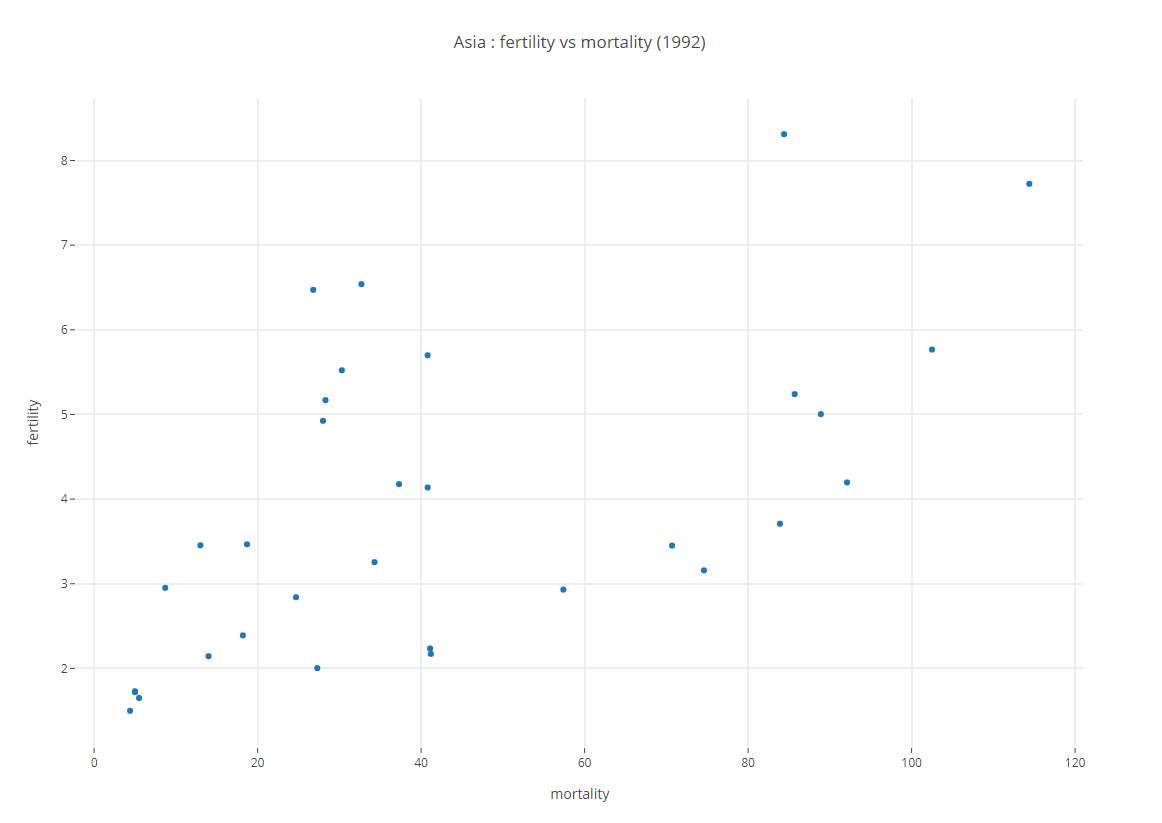
Exercice
Explorer les interactions possibles (zoom, labels, …).
2.4. Améliorations
Ce premier graphique est intéressant car il permet en quelques lignes de code de faire un affichage basique d’un jeu de données. Il souffre cependant de quelques défauts:
les labels ne sont pas très explicites ;
les données représentées sont restreintes.
2.4.1. Ajouter des labels
L’objet Scatter dispose d’un attribut text permettant d’associer une séquence de labels aux données représentées sur le graphe.
Exercice
Renseigner ce paramètre pour afficher le nom du pays au survol des points. Le résultat doit être semblable au graphique ci dessous.
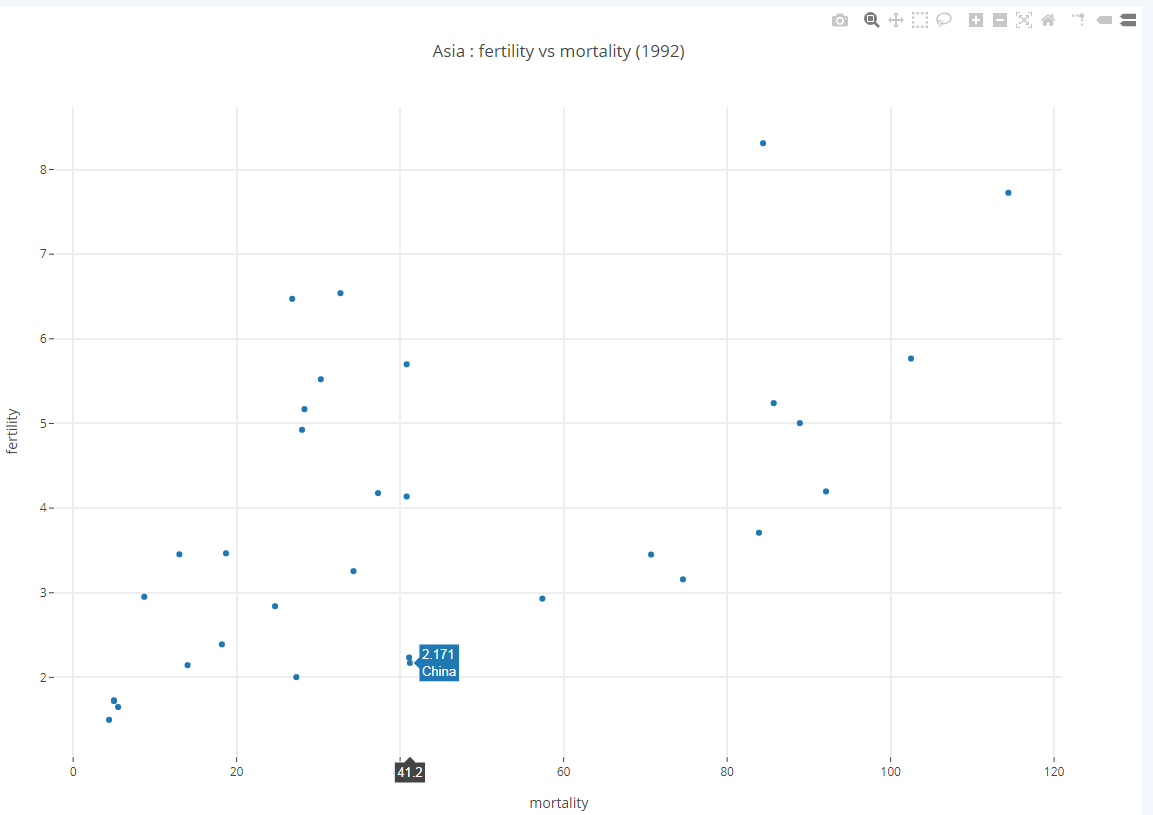
Tip
On trouvera plus d’information sur le contrôle des labels dans le document Hover Text and Formatting in Python.
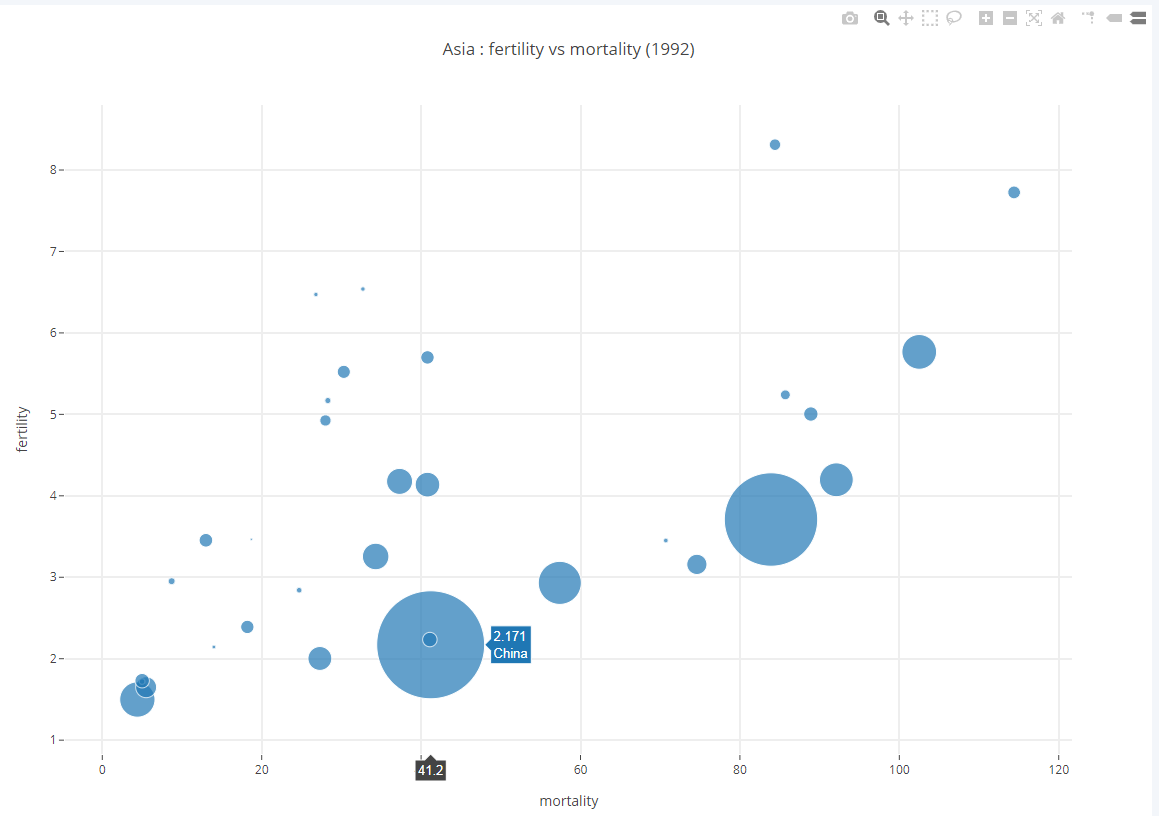
2.4.2. Plus de données
Un scatter plot permet d’inclure des données supplémentaires en paramétrant la taille des points.
Exercice
L’objet Scatter possède un attribut marker auquel on peut affecter un objet Marker qui permet de contrôler finement l’apparence des points utilisés pour matérialiser les données sur le graphique.
En particulier on peut initialiser l’attribut size de l’objet Marker avec une séquence de façon à ce que la taille du point soit une indication de la population totale du pays.
La difficulté ici est de représenter des données aussi différentes que la population de la Chine (1.16 milliards d’habitants) et celle de Bahrein (530.000 habitants).
La solution est de ne pas utiliser la séquence des populations directement mais une séquence de la transformée de chacune des populations p par une fonction f() à déterminer. La fonction log() est souvent utilisée mais ce n’est pas la seule.
Le résultat doit être semblable au graphique ci dessous.
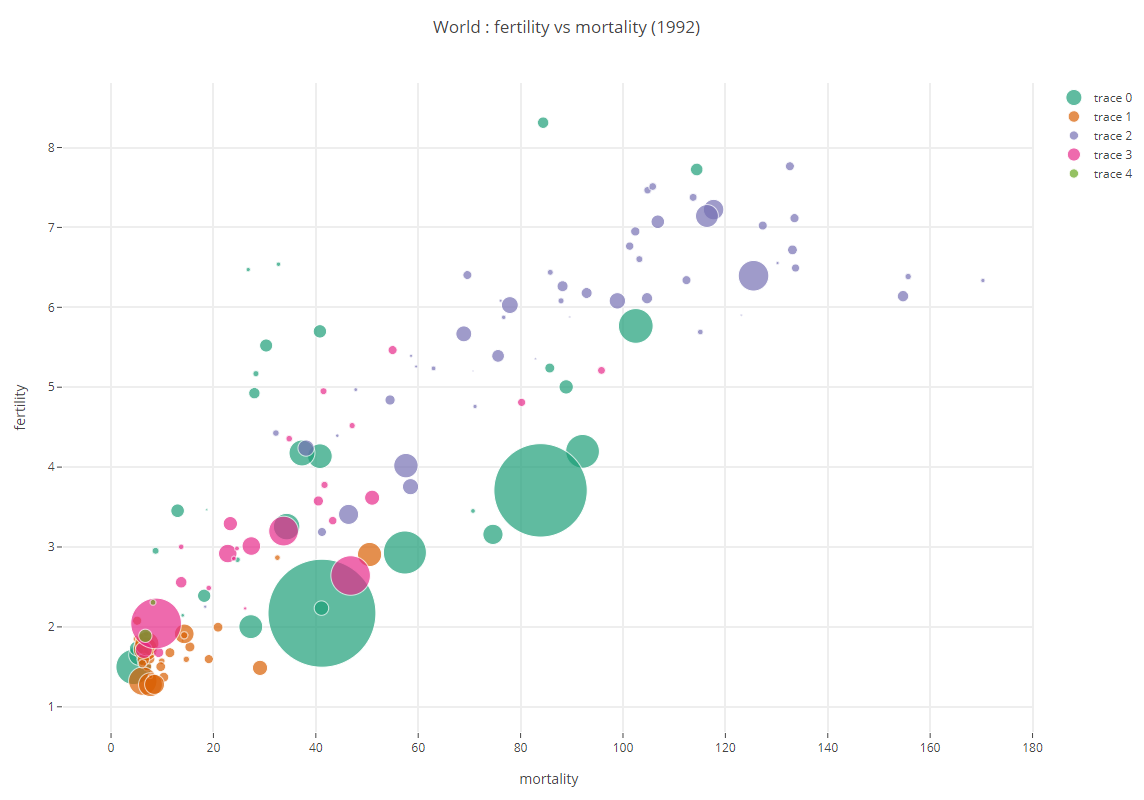
On souhaite à présent, afficher les données pour chacun des 5 continents.
Exercice
Le graphique initial ne contenait qu’une seule trace. Construire à présent une liste de traces (une trace pour chacun des cinq continents) et passer cette liste au constructeur de Figure. Vérifier la validité de l’opération en affichant le graphique correspondant.
Tip
On peut passer une variable de l’environnement à la fonction query() avec l’opérateur @. Plus de détails dans la documentation.
Pour distinguer chacun des cinq continents, il est intéressant d’utiliser une couleur permettant d’identifier ceux ci. Par défaut Plotly attribue une couleur différente à chaque trace de la séquence affectée à l’attribut data de l’objet Figure.
On peut cependant contrôler cette couleur. Utiliser Colorbrewer (ou un autre outil en ligne) pour choisir une palette de 5 couleurs permettant de représenter chacun des 5 continents. Créer un dictionnaire, permettant d’associer chaque couleur à un continent. Par exemple:
COLORS = {'Asia':'#1b9e77', 'Europe':'#d95f02', 'Africa':'#7570b3', 'Americas':'#e7298a', 'Oceania':'#66a61e' }
Modifier le code pour associer chaque continent à la couleur ci dessus.
Modifier le titre pour qu’il reflète la nature des données présentées.
Votre graphique doit être similaire à celui présenté ci dessous.
Si on observe attentivement la légende, elle présente deux défauts:
le continent n’est pas correctement identifié
la taille des symboles est inégale
Exercice
Utiliser la documentation de l’objet Legend pour identifier les propriétés de la légende mises en jeu
Modifier le code python en conséquence pour corriger l’affichage.
La figure doit ressembler à celle ci dessous
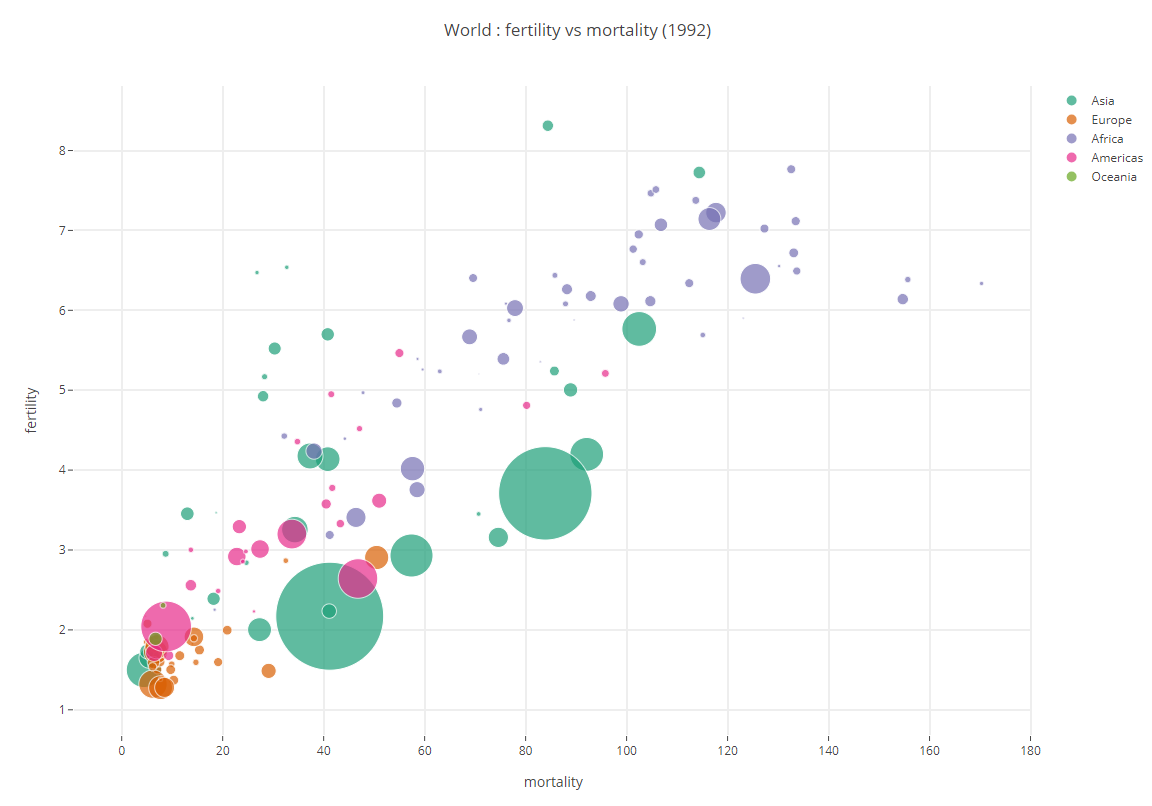
Pour aller plus loin, on peut modifier l’apparence des axes, les couleurs, etc…
2.5. Plotly Express
Le wrapper Python permet de générer les graphiques sous forme de document Javascript mais reste assez bas niveau dans le sens où il faut construire chaque partie du graphique (les clés data et layout du dictionnaire Figure).
Plotly Express est un wrapper autour de Plotly.py permettant de générer rapidement des graphiques dans une philosophie proche de R/ggplot2. Quelques ressources :
2.5.1. Les données
Plotly Express est fourni avec quelques datasets stockés sous forme de DataFrame Pandas. Pour illustrer quelques unes de ses capacités, nous allons également utiliser les données de Gapminder, la société créée par Hans Rosling qui a popularisé l’analyse de données dans cette vidéo.
>>> gapminder = px.data.gapminder()
>>> type(gapminder)
<class 'pandas.core.frame.DataFrame'>
Avant de manipuler un dataset, il est indispensable d’analyser sa structure:
>>> gapminder.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1704 entries, 0 to 1703
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 country 1704 non-null object
1 continent 1704 non-null object
2 year 1704 non-null int64
3 lifeExp 1704 non-null float64
4 pop 1704 non-null int64
5 gdpPercap 1704 non-null float64
6 iso_alpha 1704 non-null object
7 iso_num 1704 non-null int64
dtypes: float64(2), int64(3), object(3)
memory usage: 106.6+ KB
quelques statistiques sur son contenu :
>>> gapminder.describe()
year lifeExp pop gdpPercap iso_num
count 1704.00000 1704.000000 1.704000e+03 1704.000000 1704.000000
mean 1979.50000 59.474439 2.960121e+07 7215.327081 425.880282
std 17.26533 12.917107 1.061579e+08 9857.454543 248.305709
min 1952.00000 23.599000 6.001100e+04 241.165877 4.000000
25% 1965.75000 48.198000 2.793664e+06 1202.060309 208.000000
50% 1979.50000 60.712500 7.023596e+06 3531.846989 410.000000
75% 1993.25000 70.845500 1.958522e+07 9325.462346 638.000000
max 2007.00000 82.603000 1.318683e+09 113523.132900 894.000000
ainsi que l’allure générale (les premières lignes suffisent):
>>> gapminder.head() country continent year ... gdpPercap iso_alpha iso_num 0 Afghanistan Asia 1952 ... 779.445314 AFG 4 1 Afghanistan Asia 1957 ... 820.853030 AFG 4 2 Afghanistan Asia 1962 ... 853.100710 AFG 4 3 Afghanistan Asia 1967 ... 836.197138 AFG 4 4 Afghanistan Asia 1972 ... 739.981106 AFG 4[5 rows x 8 columns]
Le dataset contient les données socio économiques de 142 pays pour les années 1952, 1957, 1962, 1967, 1972, 1977, 1982, 1987, 1992, 1997, 2002 et 2007.
>>> gapminder["year"].unique()
array([1952, 1957, 1962, 1967, 1972, 1977, 1982, 1987, 1992, 1997, 2002,
2007], dtype=int64)
Pour débuter l’exploration, on va travailler sur un sous ensemble de données, que l’on extrait avec la méthode query():
>>> gapminder2007 = gapminder.query("year == 2007")
>>> gapminder2007.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 142 entries, 11 to 1703
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 country 142 non-null object
1 continent 142 non-null object
2 year 142 non-null int64
3 lifeExp 142 non-null float64
4 pop 142 non-null int64
5 gdpPercap 142 non-null float64
6 iso_alpha 142 non-null object
7 iso_num 142 non-null int64
dtypes: float64(2), int64(3), object(3)
memory usage: 10.0+ KB
2.5.2. Une première figure
Tout l’intérêt de Plotly Express réside dans le fait de générer très simplement une figure Plotly. Dans sa version actuelle, le wrapper permet de construire plusieurs dizaines de graphiques. Par exemple, un scatter plot :
>>> fig = px.scatter(gapminder2007, x="gdpPercap", y="lifeExp")
>>> fig.show()
Le graphique s’ouvre dans un navigateur:
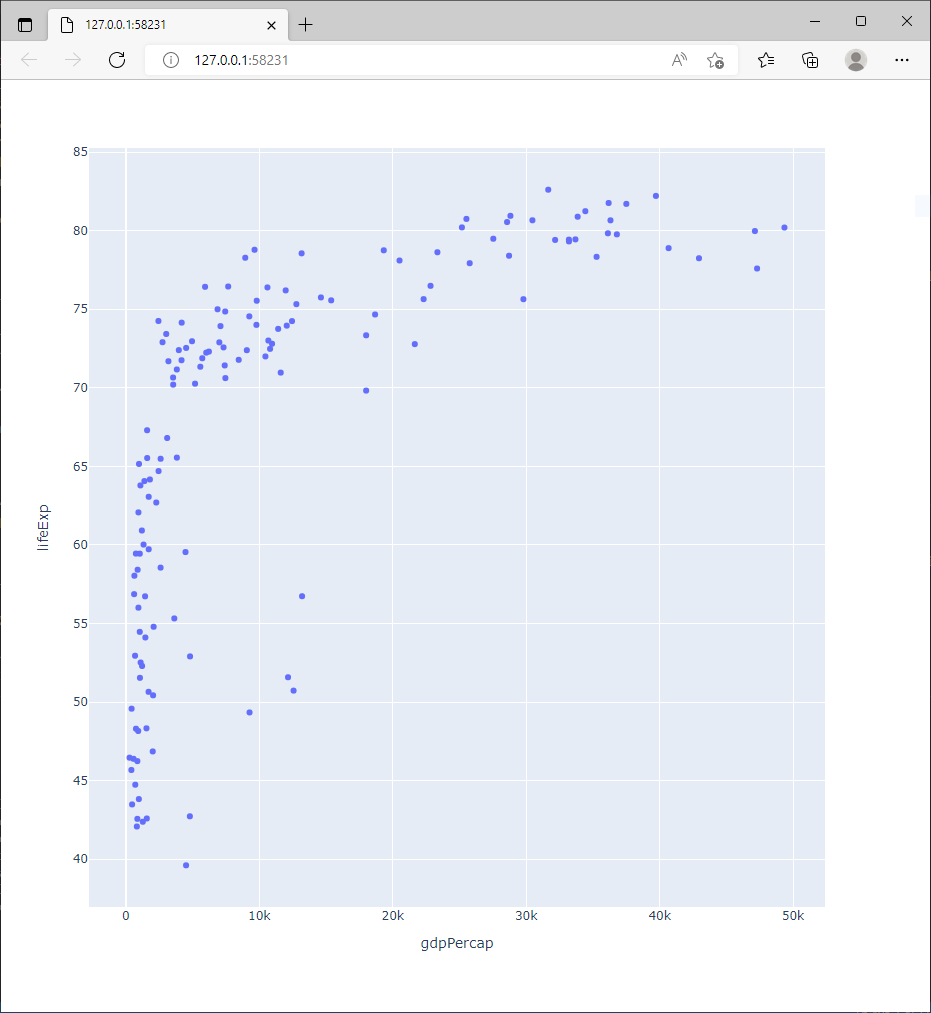
Le graphique ci dessus possède toutes les propriétés dynamiques des graphiques Plotly. En particulier, le survol de la souris permet d’accéder aux coordonnées des points, les outils de sélection et de zoom sont disponibles, etc…
Dans l’exemple ci dessus, on a choisi de stocker la référence de la figure dans la variable fig, ce qui n’est pas nécessaire ici mais est une bonne pratique en vue de leur manipulation ultérieure ou de la construction de dashboards.
Les graphiques produits par les fonctions de Plotly Express retournent des objets de type Figure:
>>> type(fig)
<class 'plotly.graph_objs._figure.Figure'>
que l’on peut encapsuler dans un fichier HTML pour affichage dans un navigateur local:
>>> import plotly
>>> plotly.io.write_html(fig, file='fig.html', auto_open=True, include_plotlyjs='cdn')
Avec les paramètres utilisés, le fichier fig.html est créé sur le disque local et s’ouvre automatiquement dans le navigateur. Le paramètre include_plotlyjs permet d’alléger le fichier en chargeant dynamiquement la bibliothèque JavaScript Plotly.js.
2.5.3. Utiliser la couleur
Dans le premier graphique, la position était utilisée pour coder la relation entre l’espérance de vie et le revenu moyen par habitant. On peut utiliser la couleur des symboles pour identifier le continent.
>>> fig = px.scatter(gapminder2007, x="gdpPercap", y="lifeExp", color="continent")
>>> fig.show()
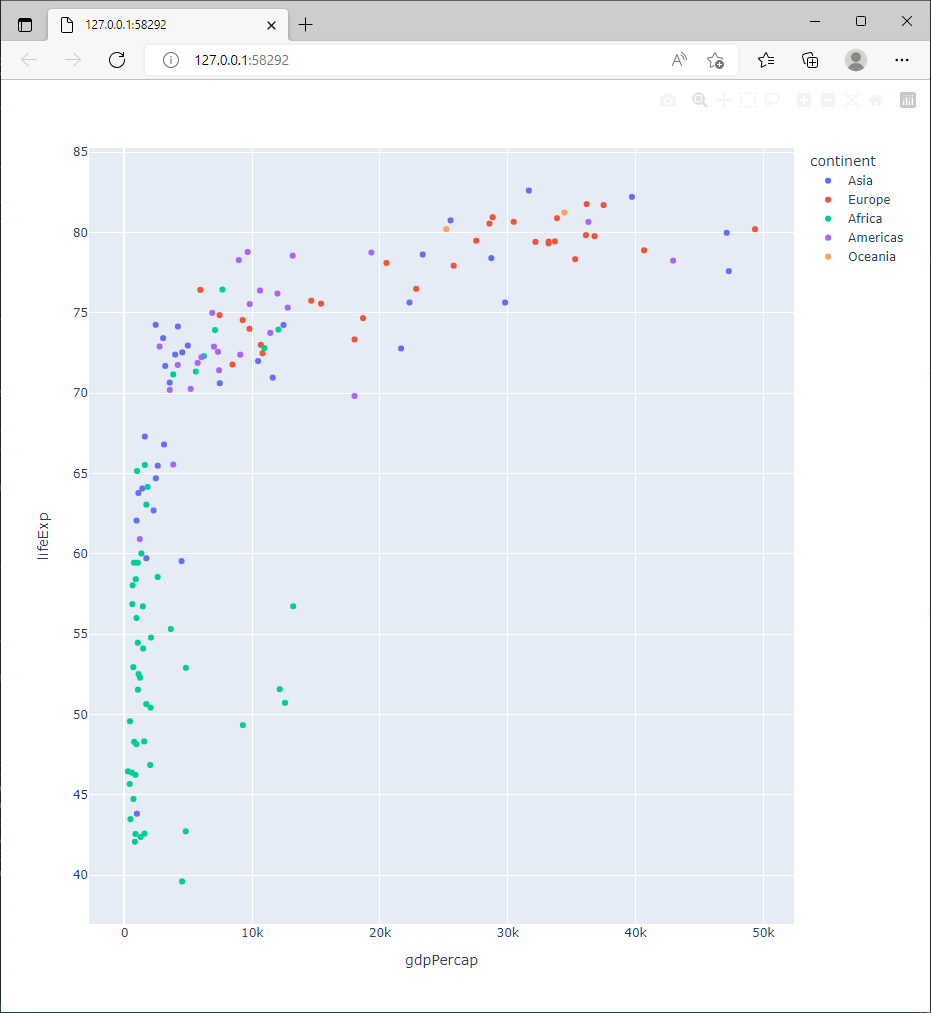
2.5.4. Utiliser la forme des symboles
Dans le second graphique, la couleur des symboles a été utilisée pour identifier le continent. On peut également utiliser la forme des symboles (ce qui est moins lisible dans ce cas !)
Exercice
Explorer la documentation de px.scatter pour coder le continent avec un symbole.
Le résultat doit être similaire à la figure ci dessous.
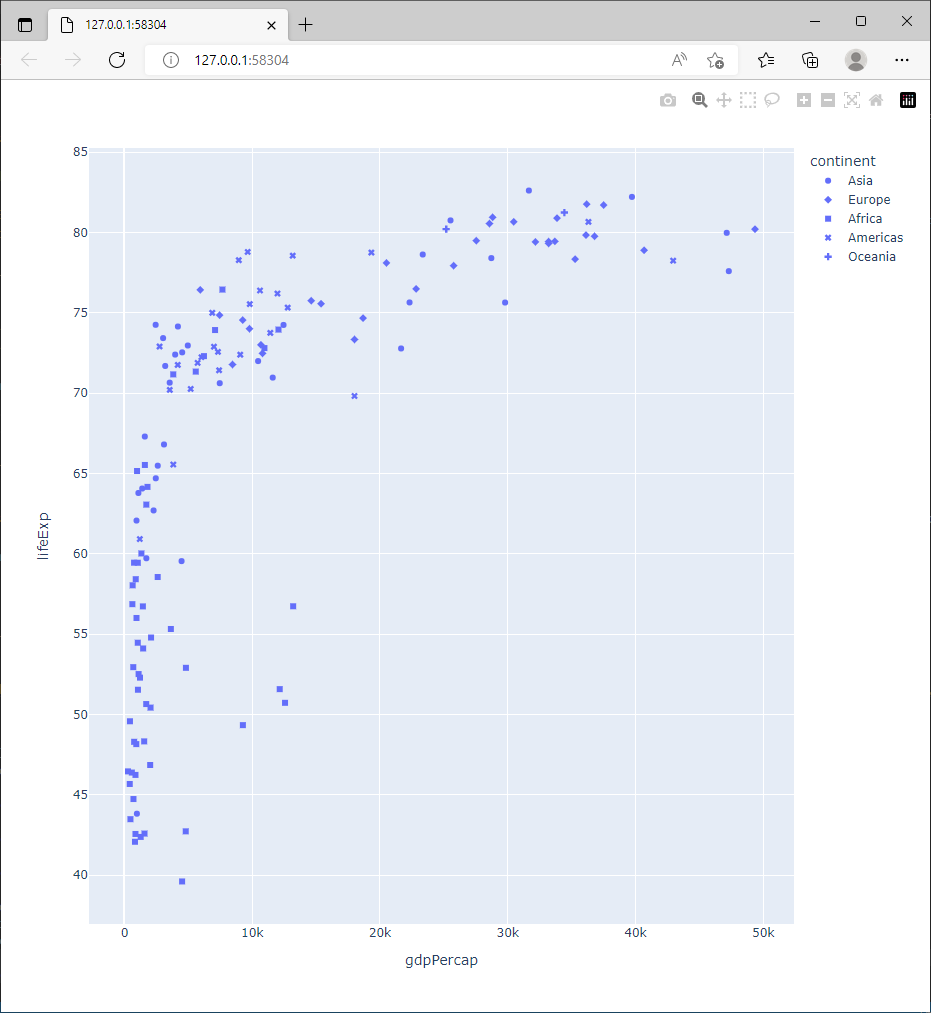
2.5.5. Utiliser la taille des symboles
Après la position, la couleur et la forme des symboles, on peut utiliser leur taille pour coder une autre variable (ici la population).
Exercice
Quel est le paramétrage de px.scatter permettant d’obtenir un graphique similaire à la figure ci dessous.
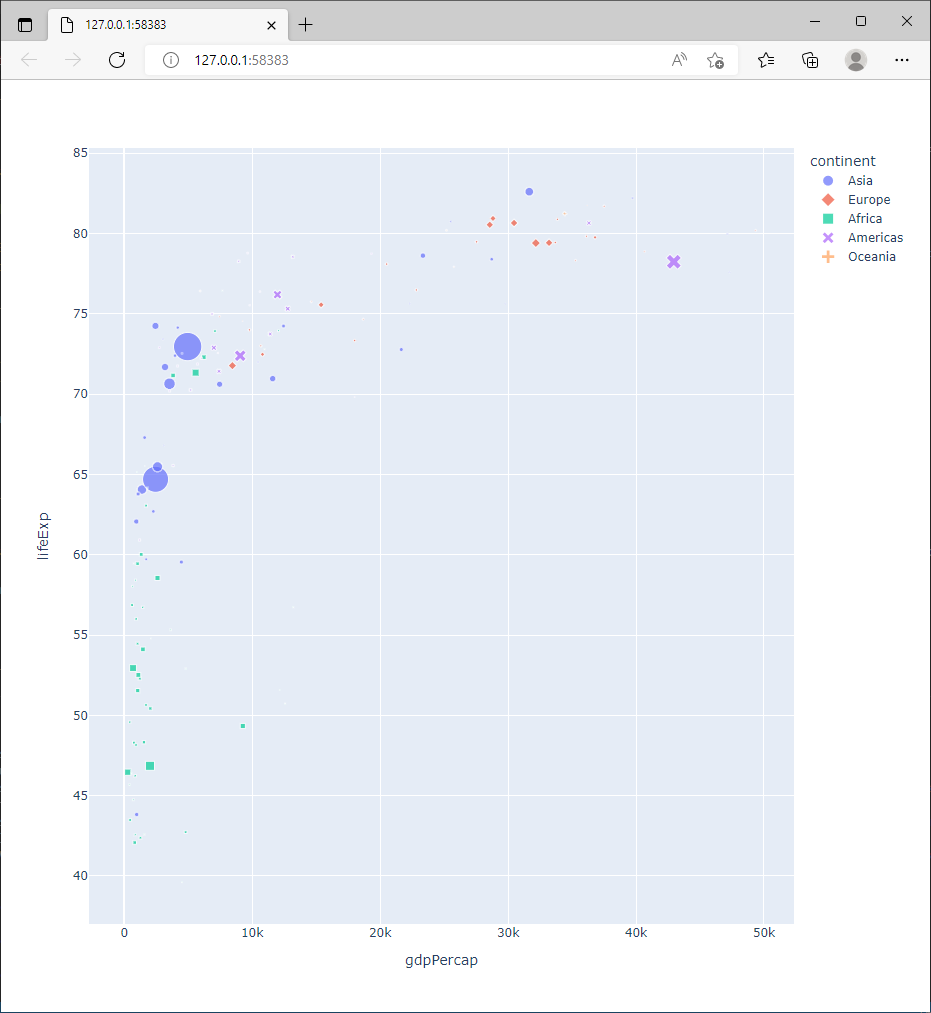
2.5.6. Les informations de survol
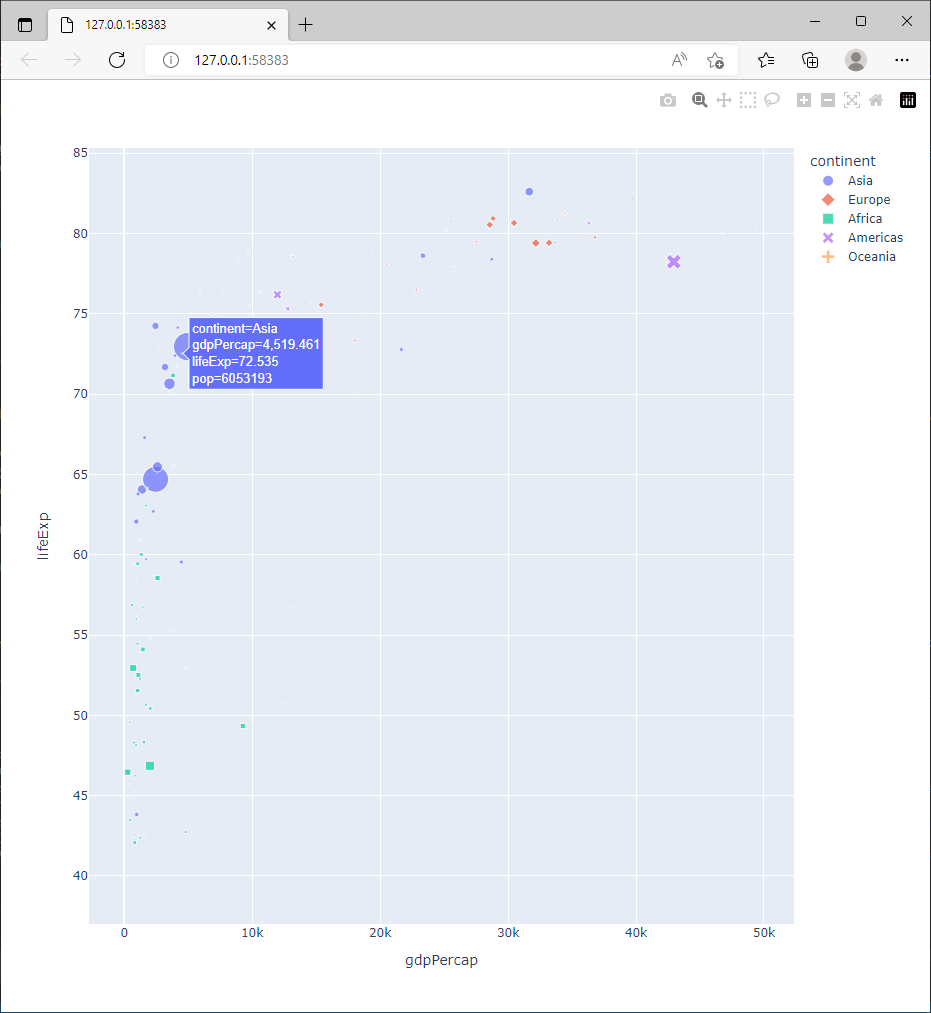
Par défaut, le survol d’un symbole fait apparaître l’ensemble des variables codées par le symbole. Sur le graphique ci dessus, il s’agit de :
continent : la couleur
(gdpPercap, lifeExp) : la position
pop : la taille
comme le montre la figure ci dessous.
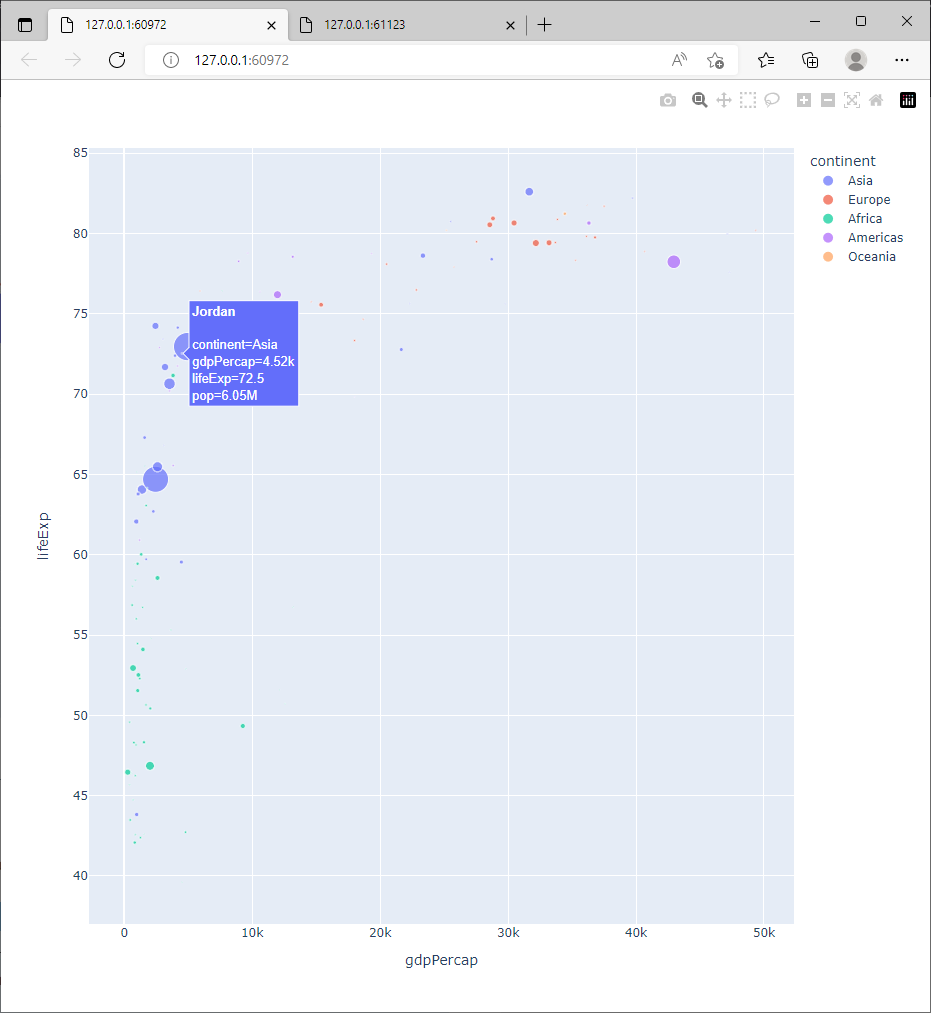
Exercice
On peut modifier le comportement par défaut en utilisant les paramètres hover_name et hover_data pour modifier les pop-ups.
A partir des exemples présentés dans le document Hover Text and Formatting in Python, modifier les paramètres de px.scatter pour produire les informations de survol présentes dans la figure ci dessous.
2.5.7. Ajouter une étiquette
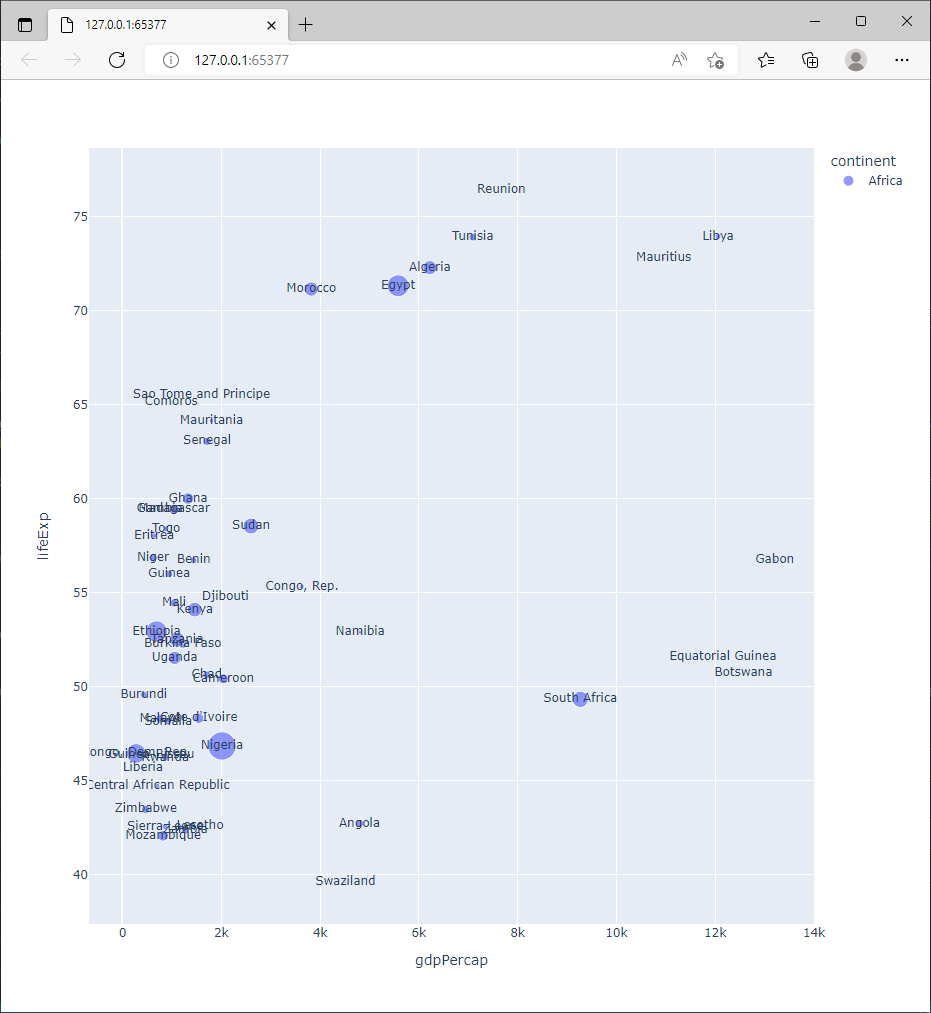
Dans certains cas, l’ajout d’une étiquette de texte directement sur le graphique peut être pertinent. En particulier ça permet de localiser des observations que les caractéristiques graphiques rendent peu lisibles (par exemple à cause d’une taille réduite). Il faut cependant s’assurer de ne pas dégrader la qualité informationnelle du graphique.
Exercice
Quel est le paramètre de px.scatter permettant d’ajouter une étiquette de texte directement sur le graphique ?
Renseigner ce paramètre pour produire un graphique similaire à celui ci dessous (il concerne les pays d’Afrique pour l’année 2007).
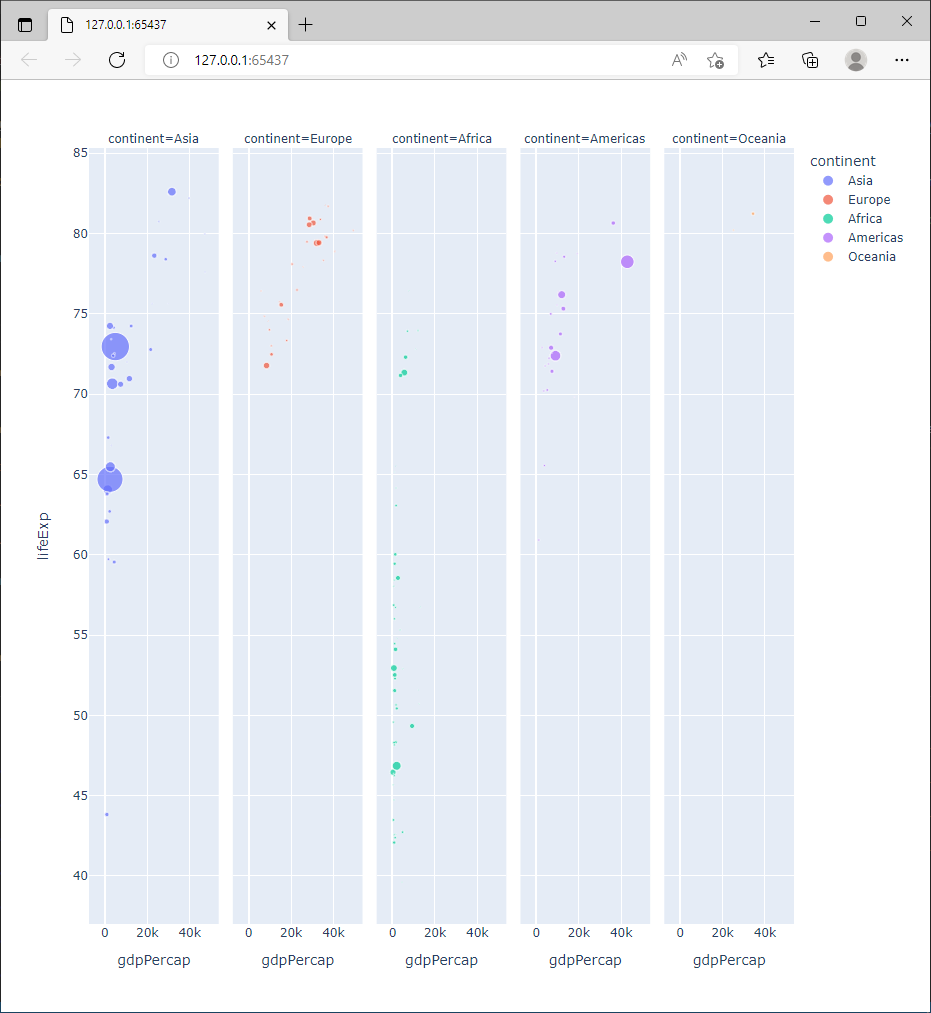
2.5.8. Le facetting
Le facetting permet de construire des sous groupes de données, basés sur une des variables de l’observation et de les présenter avec un même système d’axes pour faciliter les comparaisons.
Pour ce faire, on utilise les paramètres facet_col et facet_row de px.scatter.
Exercice
Tracer, pour chaque pays, et en groupant les pays par continent, la distribution espérance de vie vs revenu moyen sur un même système d’axes.
Le résultat doit être similaire au graphique ci dessous.
2.5.9. Animation
Construire une représentation graphique fortement interactive, nécessite la création de dashboards. Cependant, Plotly permet de produire des animations élémentaires.
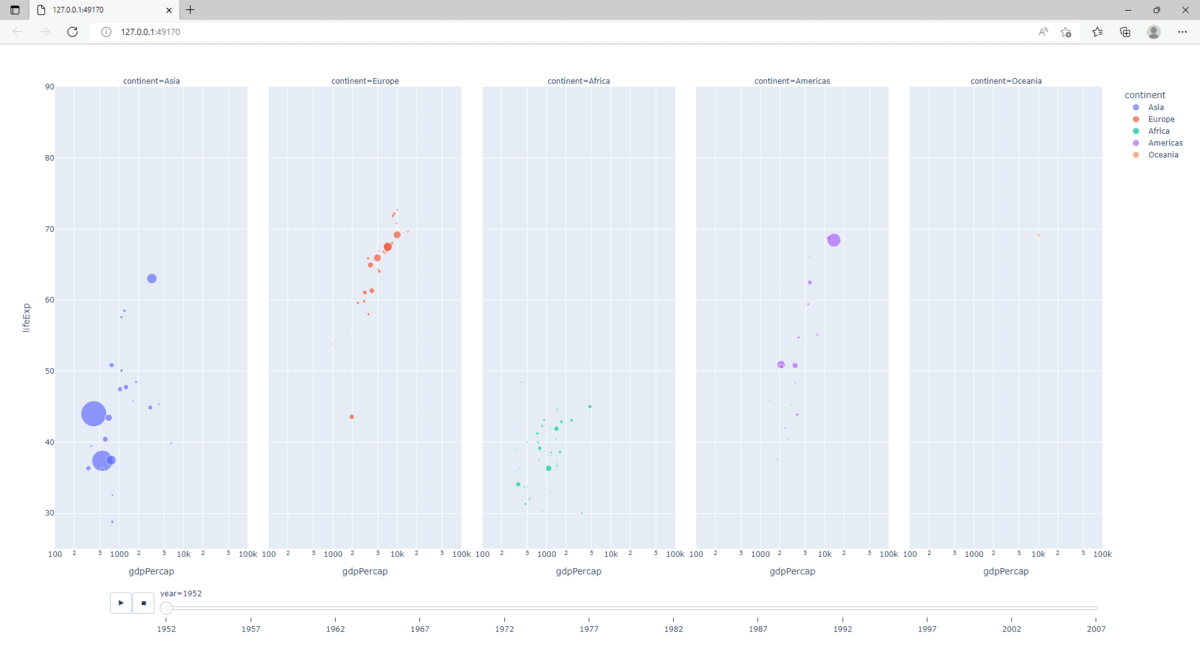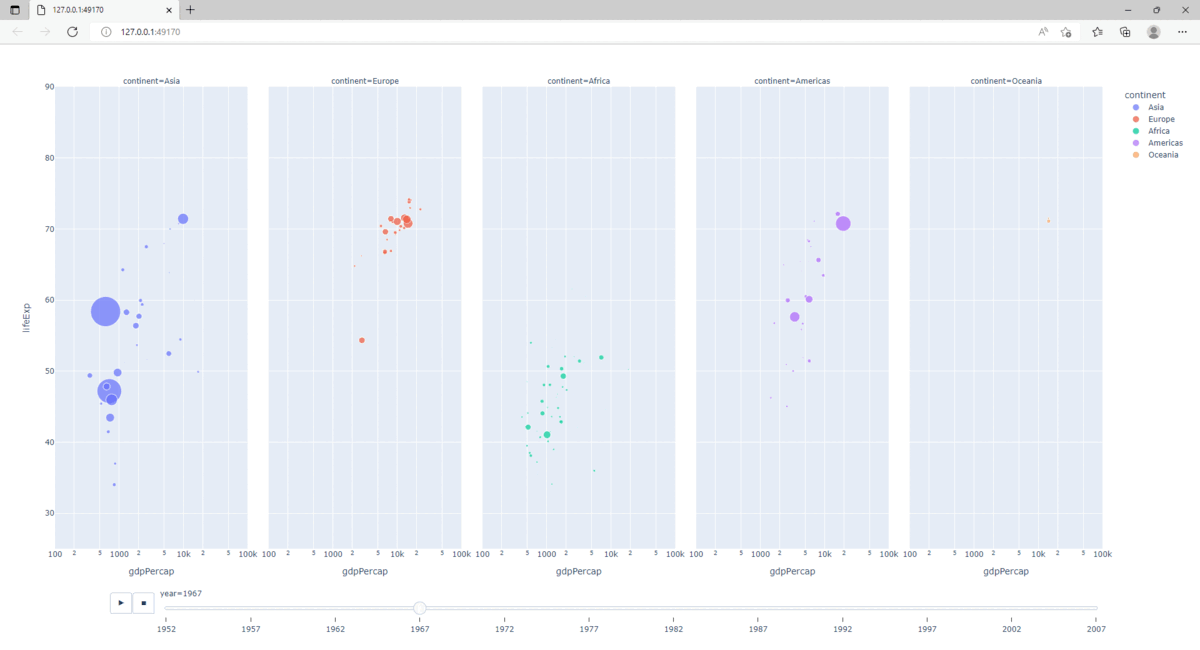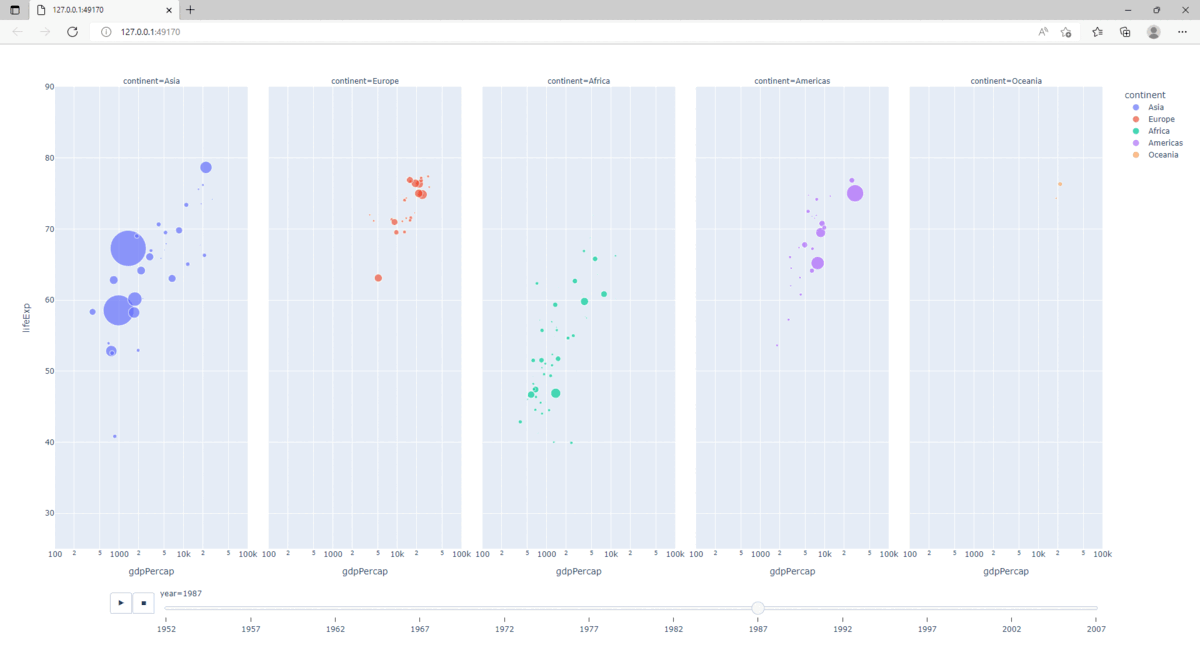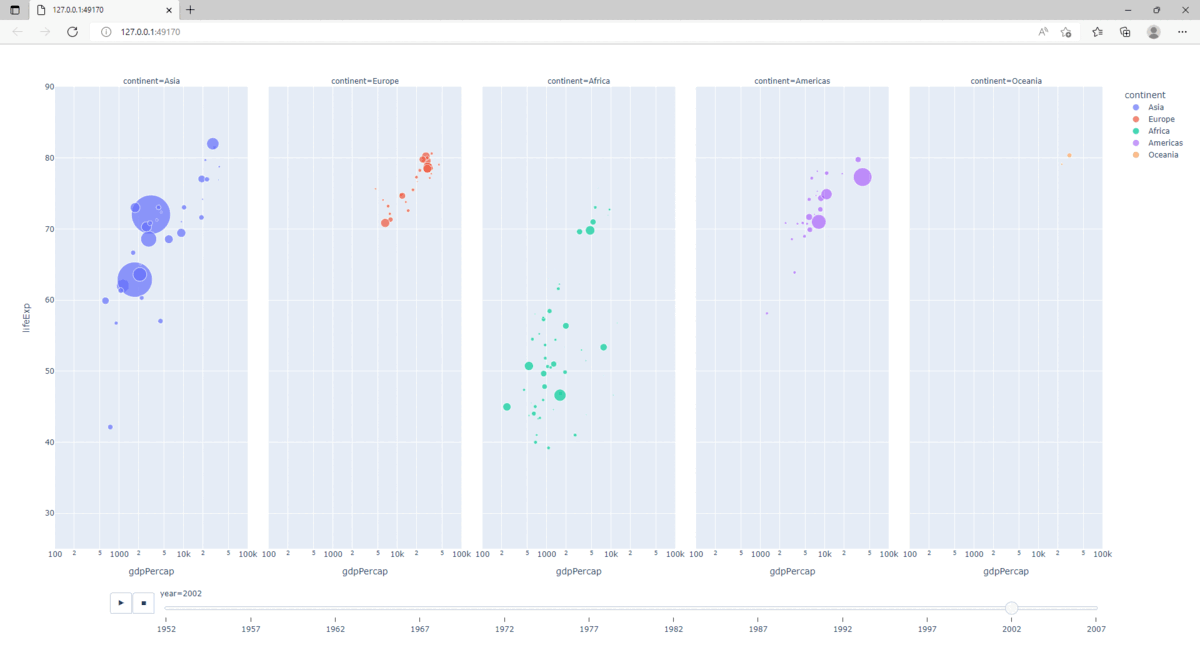
Les paramètres animation_frame et animation_group sont utilisés :
>>> fig = px.scatter(gapminder, x="gdpPercap", y="lifeExp", animation_frame="year", animation_group="country",
... size="pop", color="continent", hover_name="country", facet_col="continent",
... log_x=True, size_max=45, range_x=[100,100000], range_y=[25,90])
>>> fig.show()
2.5.10. Les couleurs
On peut choisir de représenter les données par des couleurs, et selon la nature des données à représenter on choisira :
une palette de couleurs continues : Built-in Continuous Color Scales in Python pour représenter des variables numériques. L’interpolation est possible pour représenter les valeurs intermédiaires.
ou une palette de couleurs discrètes : Discrete Colors in Python pour représenter des variables catégorielles. Aucune interpolation n’est possible.
Dans notre cas on est intéressé par le choix de 5 couleurs discrètes, pour représenter chacun des 5 variables catégorielles que sont les continents. La palette utilisée par défaut est px.colors.qualitative.Plotly. On peut modifier ce choix avec le paramètre color_discrete_sequence.
>>> fig = px.scatter(gapminder2007, x="gdpPercap", y="lifeExp", color="continent", size="pop", hover_name="country",
... labels={'gdpPercap':'GDP per Capita', 'lifeExp':'Life Expectancy'},
... color_discrete_sequence = px.colors.qualitative.Safe,
... title="L'espérance de vie dépend des revenus")
>>> fig.show()
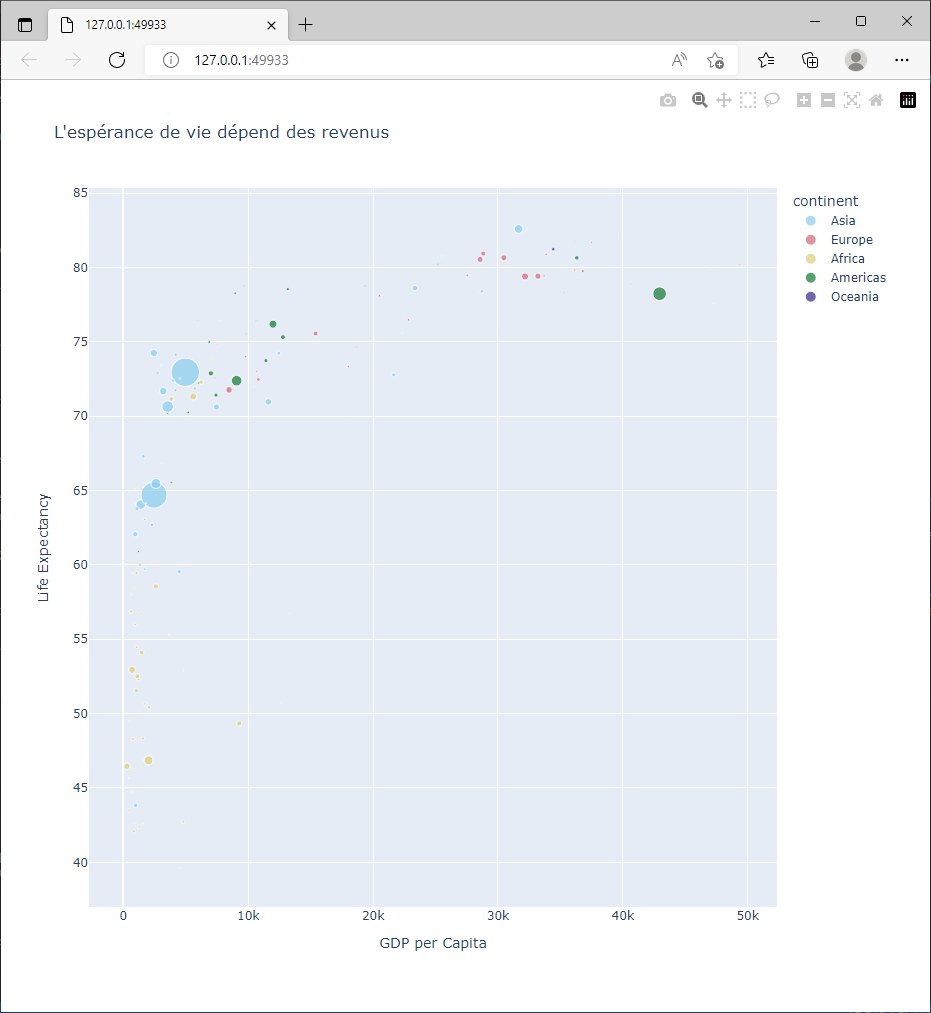
2.5.11. Plotly Express vs Plotly
Plotly Express est une interface “haut niveau” vers les objets Plotly qui permet une construction facilitée de graphiques. Pour atteindre cette simplicité, les fonctions Plotly Express ne donnent accès qu’à un nombre réduit de paramètres. Il y a donc un compromis à trouver entre la simplicité et le degré de contrôle que l’on peut avoir sur le graphique.
Ainsi l’instruction ci dessous fabrique un objet Figure.
>>> fig = px.scatter(gapminder2007, x="gdpPercap", y="lifeExp")
L’inspection de cette Figure fait apparaitre les clés data et layout présentées au début de ce chapitre
>>> fig
Figure({
'data': [{'hovertemplate': 'gdpPercap=%{x}<br>lifeExp=%{y}<extra></extra>',
'legendgroup': '',
'marker': {'color': '#636efa', 'symbol': 'circle'},
'mode': 'markers',
'name': '',
'orientation': 'v',
'showlegend': False,
'type': 'scatter',
'x': array([ 974.5803384, 5937.029526 , 6223.367465 , 4797.231267 ,
12779.37964 , 34435.36744 , 36126.4927 , 29796.04834 ,
1391.253792 , 33692.60508 , 1441.284873 , 3822.137084 ,
7446.298803 , 12569.85177 , 9065.800825 , 10680.79282 ,
1217.032994 , 430.0706916, 1713.778686 , 2042.09524 ,
36319.23501 , 706.016537 , 1704.063724 , 13171.63885 ,
4959.114854 , 7006.580419 , 986.1478792, 277.5518587,
3632.557798 , 9645.06142 , 1544.750112 , 14619.22272 ,
8948.102923 , 22833.30851 , 35278.41874 , 2082.481567 ,
6025.374752 , 6873.262326 , 5581.180998 , 5728.353514 ,
12154.08975 , 641.3695236, 690.8055759, 33207.0844 ,
30470.0167 , 13206.48452 , 752.7497265, 32170.37442 ,
1327.60891 , 27538.41188 , 5186.050003 , 942.6542111,
579.231743 , 1201.637154 , 3548.330846 , 39724.97867 ,
18008.94444 , 36180.78919 , 2452.210407 , 3540.651564 ,
11605.71449 , 4471.061906 , 40675.99635 , 25523.2771 ,
28569.7197 , 7320.880262 , 31656.06806 , 4519.461171 ,
1463.249282 , 1593.06548 , 23348.13973 , 47306.98978 ,
10461.05868 , 1569.331442 , 414.5073415, 12057.49928 ,
1044.770126 , 759.3499101, 12451.6558 , 1042.581557 ,
1803.151496 , 10956.99112 , 11977.57496 , 3095.772271 ,
9253.896111 , 3820.17523 , 823.6856205, 944. ,
4811.060429 , 1091.359778 , 36797.93332 , 25185.00911 ,
2749.320965 , 619.6768924, 2013.977305 , 49357.19017 ,
22316.19287 , 2605.94758 , 9809.185636 , 4172.838464 ,
7408.905561 , 3190.481016 , 15389.92468 , 20509.64777 ,
19328.70901 , 7670.122558 , 10808.47561 , 863.0884639,
1598.435089 , 21654.83194 , 1712.472136 , 9786.534714 ,
862.5407561, 47143.17964 , 18678.31435 , 25768.25759 ,
926.1410683, 9269.657808 , 28821.0637 , 3970.095407 ,
2602.394995 , 4513.480643 , 33859.74835 , 37506.41907 ,
4184.548089 , 28718.27684 , 1107.482182 , 7458.396327 ,
882.9699438, 18008.50924 , 7092.923025 , 8458.276384 ,
1056.380121 , 33203.26128 , 42951.65309 , 10611.46299 ,
11415.80569 , 2441.576404 , 3025.349798 , 2280.769906 ,
1271.211593 , 469.7092981]),
'xaxis': 'x',
'y': array([43.828, 76.423, 72.301, 42.731, 75.32 , 81.235, 79.829, 75.635, 64.062,
79.441, 56.728, 65.554, 74.852, 50.728, 72.39 , 73.005, 52.295, 49.58 ,
59.723, 50.43 , 80.653, 44.741, 50.651, 78.553, 72.961, 72.889, 65.152,
46.462, 55.322, 78.782, 48.328, 75.748, 78.273, 76.486, 78.332, 54.791,
72.235, 74.994, 71.338, 71.878, 51.579, 58.04 , 52.947, 79.313, 80.657,
56.735, 59.448, 79.406, 60.022, 79.483, 70.259, 56.007, 46.388, 60.916,
70.198, 82.208, 73.338, 81.757, 64.698, 70.65 , 70.964, 59.545, 78.885,
80.745, 80.546, 72.567, 82.603, 72.535, 54.11 , 67.297, 78.623, 77.588,
71.993, 42.592, 45.678, 73.952, 59.443, 48.303, 74.241, 54.467, 64.164,
72.801, 76.195, 66.803, 74.543, 71.164, 42.082, 62.069, 52.906, 63.785,
79.762, 80.204, 72.899, 56.867, 46.859, 80.196, 75.64 , 65.483, 75.537,
71.752, 71.421, 71.688, 75.563, 78.098, 78.746, 76.442, 72.476, 46.242,
65.528, 72.777, 63.062, 74.002, 42.568, 79.972, 74.663, 77.926, 48.159,
49.339, 80.941, 72.396, 58.556, 39.613, 80.884, 81.701, 74.143, 78.4 ,
52.517, 70.616, 58.42 , 69.819, 73.923, 71.777, 51.542, 79.425, 78.242,
76.384, 73.747, 74.249, 73.422, 62.698, 42.384, 43.487]),
'yaxis': 'y'}],
'layout': {'legend': {'tracegroupgap': 0},
'margin': {'t': 60},
'template': '...',
'xaxis': {'anchor': 'y', 'domain': [0.0, 1.0], 'title': {'text': 'gdpPercap'}},
'yaxis': {'anchor': 'x', 'domain': [0.0, 1.0], 'title': {'text': 'lifeExp'}}}
})
Après construction, on peut modifier “manuellement” les propriétés de la figure. Par exemple, le symbole utilisé pour l’affichage est disponible dans la clé data:
>>> fig['data'][0]['marker']['symbol'] = "diamond"
De la même façon, la clé layout contient les propriétés du graphique et on peut ajouter manuellement un titre qui n’est pas présent par défaut:
>>> fig['layout']['title']['text'] = 'Espérance de vie vs Revenu par habitant'
et modifier ses propriétés :
>>> fig['layout']['title']['font']['size'] = 24
>>> fig['layout']['title']['font']['color'] = 'red'
Le résultat doit être proche du graphique ci dessous.
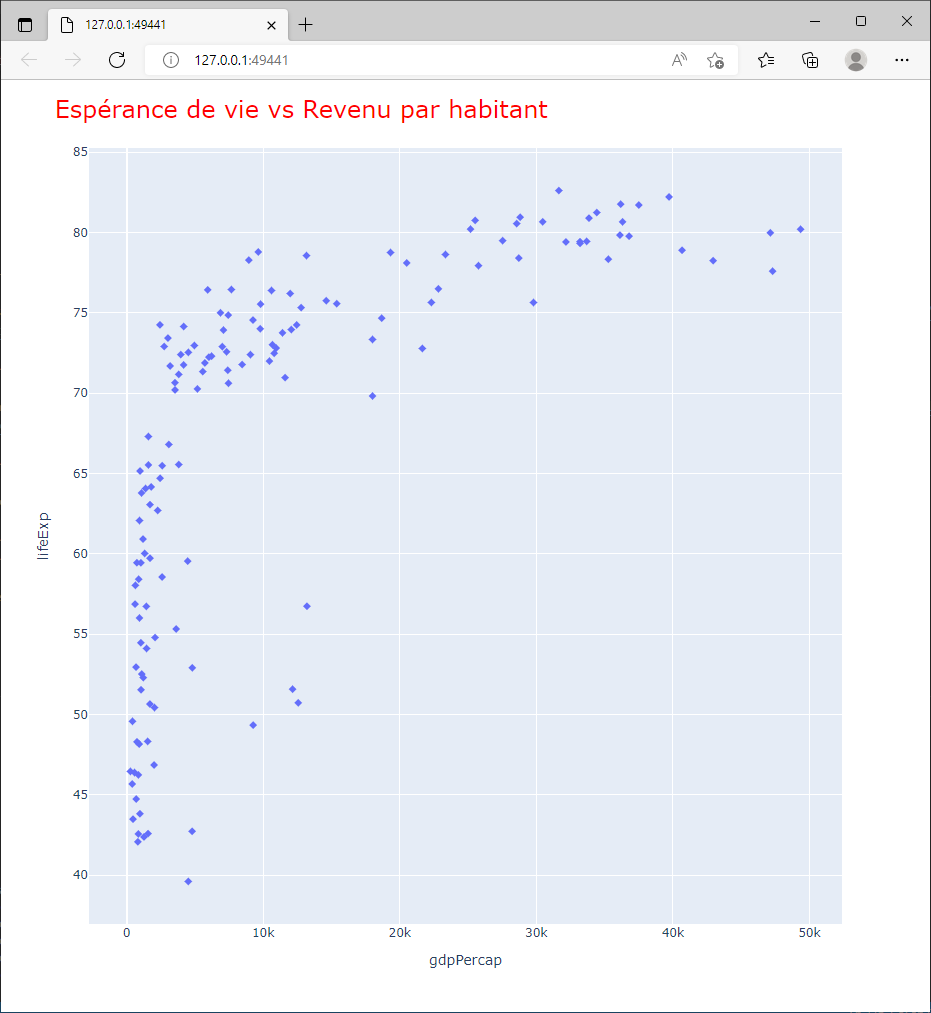
Le descriptif complet des propriétés graphiques est décrit dans cette référence.