Construire et optimiser un réseau d’espions - partie 2 : arbre de poids minimum¶
Présentation du problème fil rouge et règles du jeu¶
Fil rouge¶
Les services secrets doivent établir un réseau d’espionnage. Plus précisément, il s’agit d’établir un plan de routage des messages secrets afin qu’un individu donné puisse faire parvenir des informations à un groupe de \(N\) autres individus. Parmi cet ensemble d’individus, certains ont la possibilité de se contacter et d’échanger directement des informations alors que d’autres ne le peuvent pas. Lorsque deux individus s’échangent un message, le message peut être intercepté avec une certaine probabilité connue. Dans ce cours, nous allons répondre aux questions suivantes :
Comment transmette un message à tous les membres du réseaux ?
Comment effectuer cette transmission en minimisant la probabilité que le message soit intercepté ?
Afin de réaliser cette étude, nous devons répondre aux questions suivantes :
Comment modéliser les données du problème ?
Comment modéliser l’ensemble des solutions possibles pour router le message (sans redondance) ?
Comment trouver parmi toutes les solutions possibles, une solution optimale, (c’est-à-dire pour laquelle la probabilité d’interception est minimale) ?
Pour répondre à ces questions,
nous avons introduit dans la partie 1 la notion de graphe (à arêtes) pondérées ; et
nous avons étudié les notions d’arbres et d’arborescences ;
dans cette partie, nous considérerons le problème de recherche d’un arbre de poids minimum et nous étudierons l’algorithme de Kruskal pour le résoudre.
Organisation du cours¶
Toutes les sections dont le titre est étiqueté “Exo” font référence à des exercices relevant du problème fil rouge. Vous devez répondre à ces questions individuellement et consigner vos réponses dans un rapport. Pour cela vous devez
créer un document google doc personnel ; et
le partager dès le début de la séance avec l’enseignant.
Pour les questions qui demandent du code, il vous sera demandé de copier le code que vous avez produit dans votre rapport. Pour ce type de question, on ne vous demandera pas d’écrire l’intégralité d’un programme par vous même mais de compléter une bibliothèque de graphes écrite en C. Ainsi, vous ne devriez jamais avoir à produire plus d’une vingtaine de lignes de code par question.
Le rapport produit sera utilisé pour votre évaluation dans le cours “Graphes et algorithmes”.
En général, chaque section étiquetée “Exo” est suivie d’une section étiquetée “Cours” qui présente les notions nécessaires pour répondre aux questions posées en fil rouge.
A l’intérieur des sections de cours, vous trouverez également des petits quizz qui ont pour objectif de tester votre compréhension du cours. Pour vérifier ses réponses, il suffit de cliquer sur le bouton corriger situé à la fin de l’exercice. Il n’est pas demandé d’inclure vos réponses aux quiz dans votre rapport.
Ce cours n’est pas un mooc ! Un enseignant est à présent pour vous aider : solliciter le au moindre doute ou pour vérifier vos réponses. L’enseignant pourra également inscrire des remarques directement dans votre rapport. Prenez ces remarques en compte pour améliorer vos réponses.
Un exemple “jouet”¶
Soient 9 individus numérotés de (00)0 à (00)9, l’individu 007 doit transmettre des messages aux neuf autres. Pour cela, les échanges suivants sont possibles :
entre les individus 0 et 9 avec une probabilité d’interception de 0,3%
entre les individus 0 et 3 avec une probabilité d’interception de 0,6%
entre les individus 0 et 2 avec une probabilité d’interception de 0,2%
entre les individus 1 et 3 avec une probabilité d’interception de 0,3%
entre les individus 1 et 4 avec une probabilité d’interception de 0,4%
entre les individus 1 et 6 avec une probabilité d’interception de 0,3%
entre les individus 1 et 9 avec une probabilité d’interception de 0,4%
entre les individus 2 et 5 avec une probabilité d’interception de 0,6%
entre les individus 2 et 7 avec une probabilité d’interception de 0,5%
entre les individus 3 et 7 avec une probabilité d’interception de 0,2%
entre les individus 4 et 6 avec une probabilité d’interception de 0,2%
entre les individus 4 et 8 avec une probabilité d’interception de 0,4%
entre les individus 5 et 7 avec une probabilité d’interception de 0,1%
entre les individus 5 et 8 avec une probabilité d’interception de 0,2%
Exo - Solution optimale pour l’exemple jouet¶
Dans tous les exercices de cette partie, on suppose que les interceptions de messages sont des événements indépendants.
Proposez pour le cas de l’exemple jouet, un schéma de transmission d’un message secret qui minimise la probabilité que le message soit interceptée. Vous n’avez pas besoin ici de justifier que votre proposition est optimale (ce sera l’objet d’une question suivante) ni comment vous avez fait pour arriver à cette solution. On peut donc se contenter d’une solution avec une probabilité d’interception faible (c’est-à-dire pour laquelle on ne trouve pas facilement d’amélioration).
S’il on voulait vérifier naïvement (avec une méthode force brute) que la solution donnée précédemment est optimale, combien de graphes devraient-on considérer ?
En utilisant le vocabulaire de la théorie des graphes, formulez une solution valide quel que soit l’ensemble des espions et l’ensemble des échanges possibles.
Justifiez la proposition formulée dans l’exemple précédent. Pour vous aider, vous pouvez vous appuyer sur les rappels suivants :
si \(A\) et \(B\) sont des événements indépendants de probabilités \(p_A\) et \(p_B\) alors la probabilité de l’événement (\(A\) et \(B\)) est égale à \(p_A.p_b\)
si \(A\) est un événement de probabilité \(p_A\), l’événement \((non~A)\) est de probabilité \(1-p_A\)
la fonction logarithme \(ln\) est une fonction telle que pour tous réels \(a\) et \(b\), nous avons \(ln(a.b) = ln(a) + ln(b)\)
la fonction logarithme \(ln\) est une fonction croissante, ce qui signifie que pour tout couples de réels \(a\) et \(b\) si \(a\) est inférieur à \(b\) alors \(ln(a)\) est inférieur à \(ln(b)\).
Dans le schéma que vous avez proposé à la question 1, indiquez la probabilité que le message soit intercepté.
Cours - Arbre de poids minimum¶
La recherche d’un arbre de poids minimum est l’un des problèmes les plus typiques et les plus connus du domaine de l’optimisation combinatoire. Dans cette section, nous allons commencer par formuler ce problème à travers une mise en situation pratique, puis nous le formaliserons en termes de graphes et terminerons avec la présentation du problème dual de l’arbre couvrant de poids maximum. Dans la section de cours suivante, nous étudierons un algorithme efficace pour résoudre ce problème.
Mise en situation¶
On souhaite construire un réseau de communication (ultra-rapide) pour connecter à grande vitesse les principales villes française. On connait le coût de construction des liaisons suivantes :
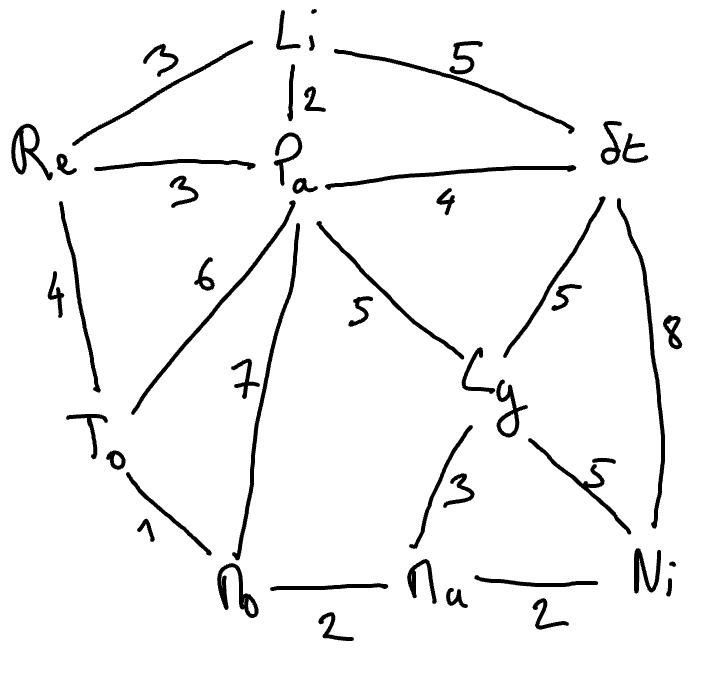
- Problème.
Comment construire un tel réseau de communication à moindre coût en s’assurant que l’on puisse transmettre de l’information de n’importe quelle ville à n’importe quelle autre ?
Les solutions de ce problème s’appellent les arbres de poids minimum du graphe pondéré dessiné ci-avant.
Formalisation avec les graphes¶
Intuitivement, une solution au problème posé précédemment doit satisfaire les conditions suivantes :
être un sous-graphe du graphe de départ car seules les arêtes de ce graphe correspondent à des liaisons que l’on peut construire ;
dans ce sous-graphe, il doit y avoir un chemin de n’importe quelle ville à n’importe quelle autre pour pouvoir acheminer l’information : ce sous-graphe doit donc être connexe et doit comprendre tous les sommets du graphe de départ ;
parmi tous les sous-graphes qui satisfont les conditions (1) et (2) ci-dessus, nous devons retenir une solution de coût le plus faible.
Les quatre définitions présentées ci-après permettent de formaliser les quatre conditions en gras ci-dessus.
Remarque liminaire. Dans cette partie du cours, nous ne considérons que des graphes connexes et des pondérations à valeurs (strictement) positives, c’est-à-dire que le poids d’une arête est toujours supérieur à 0. Afin d’alléger la lecture, nous omettrons volontairement cette précision lorsque nous parlerons d’un graphe pondéré dans la suite de cette partie.
Définition (sous-graphe couvrant)
Soit \(G = (S,A)\) un graphe non orienté. Un sous-graphe couvrant de \(G\) est un graphe \(G' = (S',A')\) dont l’ensemble des sommets est le même que celui de \(G\) et dont chaque arête est aussi une arête de \(G\), c’est-à-dire que \(G'\) est tel que :
\(S' = S\) ; et
\(A' \subseteq A\).
Soient les graphes \(G, G_1, G_2, G_3\) suivants.
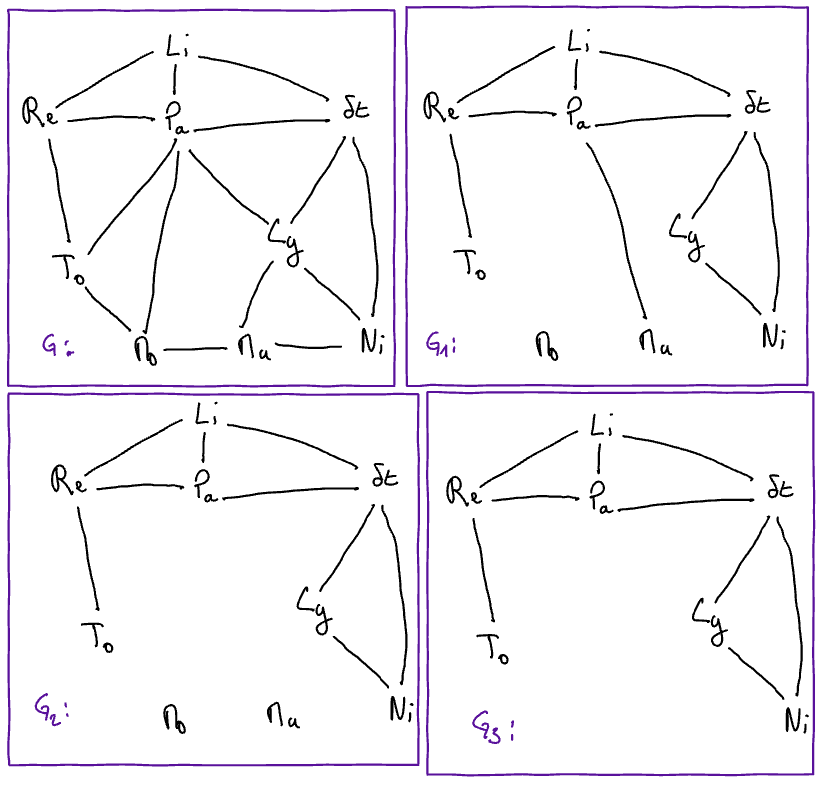
Soient également les graphes :
\(G_4 = (S_4, A_4)\) avec \(S4 = \{ Li, Pa, Ly, St, Re, Mo, Ma,\}\) et \(A_4 = \{ \{Li, Pa\}, \{ Pa, St\}, \{Pa, Re\} \}\); et
\(G_5 = (S_5, A_5)\) avec \(S4 = \{ Li, Pa, Ly, To, St, Re, Mo, Ma, Ni\}\) et \(A_4 = \{ \{Li, Pa\}, \{ Pa, St\}, \{Pa, Re\} \}\); et
Indiquez, pour chacune des affirmations ci-dessous, si elle est vraie ou fausse.
\(G_1\) est un sous-graphe couvrant de \(G\)
\(G_2\) est un sous-graphe couvrant de \(G\)
\(G_3\) est un sous-graphe couvrant de \(G\)
\(G_4\) est un sous-graphe couvrant de \(G\)
\(G_5\) est un sous-graphe couvrant de \(G\)
Définition (rappel): connexité
Soit \(G = (S,A)\) un graphe non-orienté. Le graphe \(G\) est connexe, si le graphe orienté \((S, \Gamma_G)\) associé à \(G\) est connexe, c’est à dire si, pour tout couple de sommets \(x\) et \(y\) de \(G\), il existe une chaîne de \(x\) à \(y\) dans \((S, \Gamma_G)\).
Définition poids (d’un graphe pondéré)
Soit \((G,p)\) un graphe pondéré tel que \(G = (S,A)\). Le poids de \(G\), désigné par \(P(G)\), est la somme des poids des arêtes de \(G\), c’est à dire
\(P(G) = \sum_{u \in A} p(u)\).
Soit le graphe pondéré \((G,p)\) et soient les sous-graphes \(G_1, G_2\), et \(G_3\) de \(G\) déssinés ci-dessous :
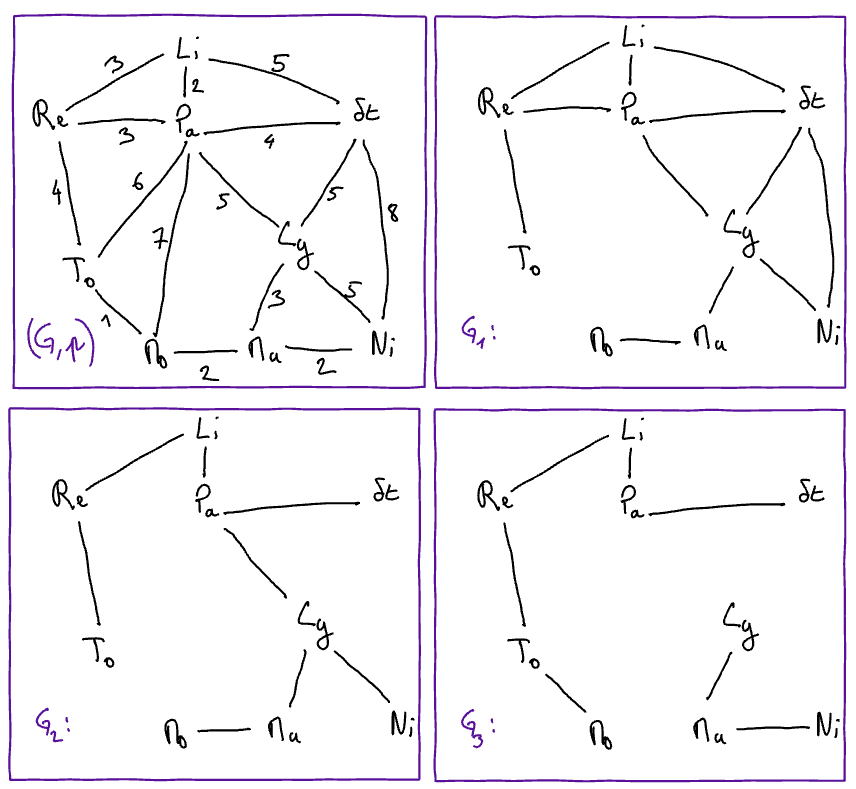
Complétez les égalités suivantes pour qu’elles soient vraies.
\(P(G_1)=\)
\(P(G_2)=\)
\(P(G_3)=\)
Définition arbre de poids minimum
Soit \((G,p)\) un graphe pondéré. Un arbre de poids minimum (de \((G,p)\)) est un graphe \(G'\) tel que :
\(G'\) est un sous-graphe couvrant de \(G\) ;
\(G'\) est connexe ;
le poids de \(G'\) est minimum parmi tous les poids des graphes satisfaisant les conditions 1 et 2 ci-dessus, c’est-à dire
pour tout sous-graphe \(G''\) connexe et couvant de \(G\), on a \(P(G') \leq P(G'')\).
Soit le graphe pondéré \((G,p)\) et soient les sous-graphes \(G_1, G_2, G_3, G_4\), et \(G_5\) de \(G\) déssinés ci-dessous.
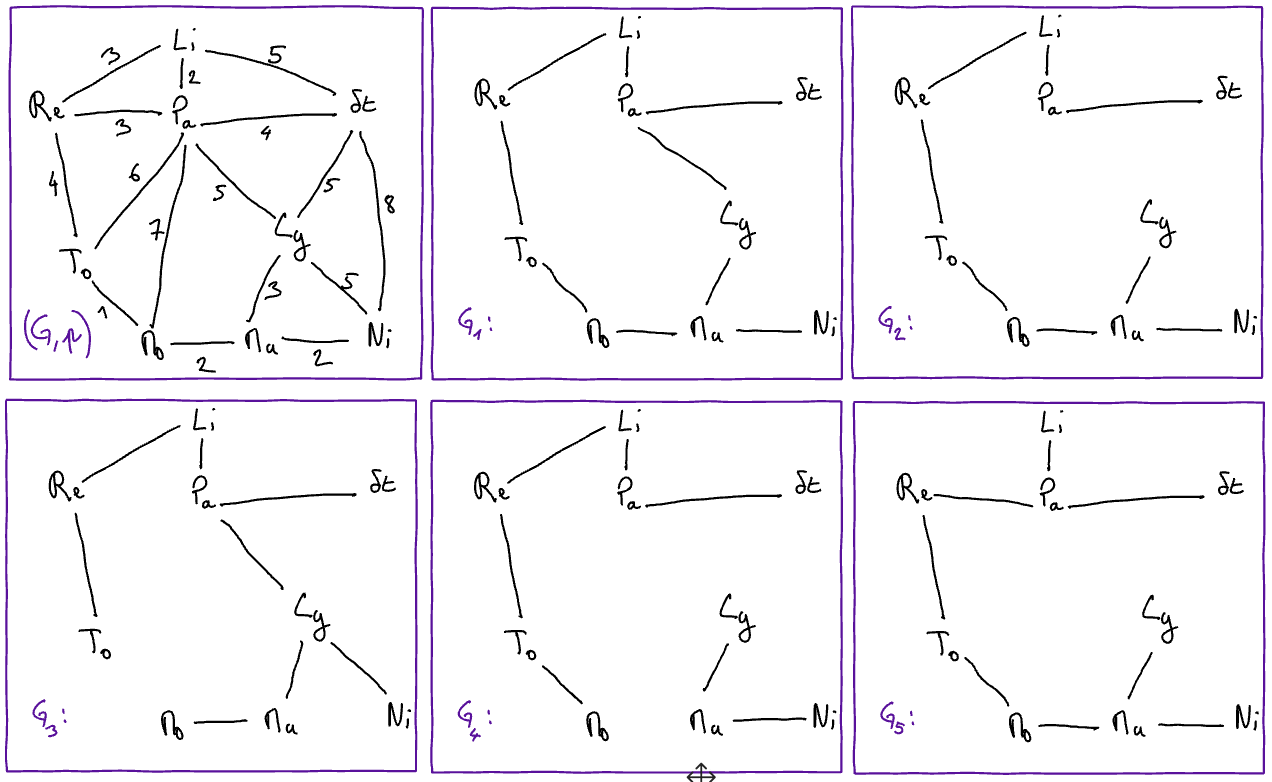
Indiquez, pour chacune des affirmations ci-dessous, si elle est vraie ou fausse (aide : il y a au moins une affirmation qui est vraie).
\(G_1\) est un arbre de poids minimum de \((G,p)\)
\(G_2\) est un arbre de poids minimum de \((G,p)\)
\(G_3\) est un arbre de poids minimum de \((G,p)\)
\(G_4\) est un arbre de poids minimum de \((G,p)\)
\(G_5\) est un arbre de poids minimum de \((G,p)\)
La définition précédente n’impose pas explicitement qu’un arbre de poids minimum soit un arbre. Cependant, on peut observer qu’un graphe \(G'\) connexe qui n’est pas un arbre ne peut pas être un arbre de poids minimum. En effet, un tel graphe contient nécessairement une arête qui n’est pas un isthme (sinon ce serait un arbre) et dont la suppression conduit à un graphe connexe de poids strictement inférieur à celui de \(G'\), démontrant ainsi que \(G'\) n’est pas un arbre de poids minimum. Nous pouvons donc déduire la propriété suivante.
Propriété
Soit \((G,p)\) un graphe pondéré. Tout arbre de poids minimum de \(G\) est un arbre.
Remarque
Etant donné un graphe pondéré \((G,p)\), il peut exister plusieurs arbres de poids minimum distincts. Par exemple, dans le cas d’un graphe où tous les poids sont égaux (et valent 1), chaque sous-graphe couvrant qui est un arbre est également un arbre de poids minimum (de poids \(n-1\) si \(n\) est le nombre de sommets de \(G\)) .
S’il existe plusieurs arbres de poids minimum de \((G,p)\), le poids de chacun de ces arbres est le même.
Dans le domaine de l’optimisation combinatoire, pour un graphe pondéré \((G,p)\) donné,
l’ensemble \(\mathcal{R}\) contenant les sous graphes connexes et couvrants de \(G\) est appelé l’ensemble des solutions réalisables (du problème) ;
la fonction \(P\) qui associe son poids à chaque graphe dans \(\mathcal{R}\) est appelée la fonction objectif ; et
le problème en lui même consiste à déterminer la valeur
\(\min \{ P(G')~|~ G' \in \mathcal{R}\}\).
Pour résoudre ce problème, une solution naïve (“méthode force brute”) consiste à :
énumérer tous les sous-graphes couvrants de \(G\) ;
vérifier, pour chacun d’eux, s’il est connexe (et donc s’il appartient à l’ensemble \(\mathcal{R}\)) ; et, si c’est le cas,
calculer son poids ; et
retenir le poids le plus faible.
Cet algorithme naïf n’est pas très efficace puisqu’il existe un très grand nombre de sous-graphes de \(G\) et donc les énumérer tous prendrait beaucoup de temps. Plus précisément, si \(G\) comporte \(m\) arêtes, ce nombre est égal à \(2^m\). En effet, chaque arête de \(G\) pouvant être incluse ou exclus d’un sous graphe, énumérer tous les sous-graphes de \(G\) revient à énumérer tous les mots binaires à \(m\) bits (1 bit par arête). Ainsi, la compelexité de l’algorithme naïf est au moins exponentielle en \(O(2^m)\). En pratique, il n’est pas envisageable d’utiliser un tel algorithme pour un graphe de plus de quelques dizaines de sommets. Dans une section suivante, nous verrons un algorithme très efficace pour résoudre ce problème en temps \(O(nm)\).
Arbres de poids maximum¶
Définition arbre de poids maximum
Soit \((G,p)\) un graphe pondéré. Un arbre de poids maximum (de \((G,p)\)) est graphe \(G'\) tel que
\(G'\) est un sous-graphe couvrant de \(G\) ;
\(G'\) est un arbre ;
le poids de \(G'\) est maximum parmi tous les poids des graphes satisfaisant les conditions 1 et 2 ci-dessus, c’est-à dire
pour tout sous-graphe \(G''\) couvant de \(G\) qui est un arbre, on a \(P(G') \geq P(G'')\).
Nous remarquons que la définition d’un arbre de poids maximum est similaire de celle d’un arbre de poids minimum, à deux différences près :
la condition de connexité est remplacée par la condition plus forte “etre un arbre” ;
on considère le poids le plus élevé possible au lieu du poids le plus faible.
La propriété suivante indique qu’arbres de poids minimum et de poids maximum sont équivalents à une inversion près des poids des arcs (et plus généralement à toute fonction décroissante des poids). Cela signifie que pour obtenir un arbre de poids maximum, on peut
commencer par inverser les poids du graphe ; et
considérer un arbre de poids minimum dans le graphe aux poids inversés.
Réciproquement, pour obtenir un arbre de poids minimum, on peut inverser les poids du graphes et chercher un arbre de poids maximum dans le graphe au poids inversés.
Propriété
Soit \((G,p)\) un graphe pondéré et soit \(G'\) un graphe. Les deux propositions suivantes sont équivalentes :
\(G'\) est un arbre de poids minimum de \((G,p)\) ; et
\(G'\) est un arbre de poids maximum de \((G, 1/p)\),
où pour chaque arête \(u\) de \(G\), on a \([1/p] (u) = 1 / (p(u))\).
Preuves (en exercice, pour les curieux).
Exo - Calculer des arbres de poids minimum¶
Exécutez à la main l’algorithme de Kruskal sur le graphe de l’exemple “jouet”. Pour cela, vous expliciterez l’état des variables à chaque itération de la boucle principale de l’algorithme (conseil : inspirez vous de la présentation du cours ci-dessous).
Indiquez si la proposition que vous aviez faites précédemment (c’est-à-dire dans la section Exo précédente) pour le réseau d’espions était correcte.
Implémentez l’algorithme de Kruskal. Si vous voulez de l’aide, il vous suffit de
Téléchargez les nouvelles versions de fichiers sources
graphes.hetgraphes.c(qui contiennent maintenant une structure et des fonctions de manipulation des graphes pondérés)Complétez le code de la fonction
algoKruskaldans le fichierarbrePoidsMin.c(toutes les fonctions annexes les arêtes et calculer les composantes connexes ont été implémentées pour vous :-) )Testez votre implémentation de l’algorithme de Kruskal sur
le fichier
espions.graphecorrespondant au graphe pondéré de l’exemple “jouet” ; etsur ces fichier
aleaPondere_1000_8000.grapheetaleaPondere_10000_80000.graphequi comprennent 1000 sommets et 8000 arêtes pour le premier et 10000 et 80000 arêtes pour le second.Utilisez vos implémentations de l’algorithme de Kruskal et de l’algorithme d’arborescence vu en partie 1 pour donner la liste des “communications” à établir entre les agents pour faire circuler le message secret depuis l’agent 007 en minimisant la probabilité que le message soit intercepté.
Pour chaque communication, vous afficherez l’émetteur et le récepteur du message.
Incluez dans votre rapport une trace d’exécution de votre programme.
Cours - Algorithme de Kruskal¶
Il existe plusieurs algorithmes efficaces pour calculer un arbre de poids minimum d’un graphe pondéré. Parmi les plus connus, on peut citer :
l’algorithme de Borůvka (le premier en date, proposé en 1926)
l’algorithme de Chazel (meilleure compexité connue à ce jour, proposé en 2000)
Nous commençons par présenter un principe genérique (dit glouton) pour obtenir un arbre de poids minimum avant de décrire pécisément l’algorithme de Kruskal qui suit ce principe générique. Nous analysons ensuite la correction et la complexité de l’algorithme de Kruskal.
Schéma générique pour calculer des arbres de poids minimum¶
L’algorithme de Kruskal construit progressivement un arbre de poids minimum
en ajoutant les arêtes une par une ;
en partant d’un graphe qui ne contient aucune arête.
L’algorithme se termine lorsque l’ensemble des arêtes ajoutées forme un arbre de poids minimum. Si le graphe \(G\) contient \(n\) sommets, l’algorithme doit donc s’arreter après avoir ajouté \(n-1\) arêtes. Le schéma en pseudo-langage de cet algorithme générique est donc le suivant.
Algorithme ApMin-generique
Données : Un graphe pondéré \((G,p)\) à \(n\) sommets avec \(G=(S,A)\)
Résultat : Un ensemble d’arêtes \(T\) tel que le couple \((S,T)\) est un arbre de poids minimum de \(G\)
\(T := \emptyset\)
\(k := 0\)
// variable utilisée pour compter le nombre d'arêtes dans TTant que \(k < n-1\) Faire
Sélectionner une arête sûre 1 \(u\) pour \(T\) et \((G,p)\)
\(T := T \cup \{u\}\)
// on ajoute u à T\(k := k + 1\)
// on met à jour le décompte k du nombre d'arêtes dans TNotes
- 1
La notion d’arête sûre employée dans le pseudo-code est définie juste après.
Intuitivement, lorsque l’on est dans les conditions de l’algorithme, une arête sûre est une arête qui peut être ajoutée à \(T\) pour construire un arbre de poids minimum. En d’autre termes, si \(T\) est une “partie” d’un arbre de poids minimum alors \(T \cup \{u\}\) doit également être une partie d’un arbre de poids minimum, cette partie étant un peu plus grande puisqu’elle contient une arête supplémentaire. La définition suivante formalise la notion d’arête sûre.
Définition: arête sure
Soit un graphe pondéré \((G,p)\) tel que \(G=(S,A)\).
Soit \(T\) un sous-ensemble de \(A\) tel que \((S,T)\) est un sous-graphe d’un arbre de poids minimum de \((G,p)\).
Soit \(u\) une arête de \(G\) qui n’appartient pas à \(T\).
On dit que l’arête \(u\) est sûre (pour \(T\) et \(G\) ) si le graphe \((S, T \cup \{u\} )\) est un sous-graphe d’un arbre de poids minimum de \((G,p)\).
D’après cette définition, il peut être observé que l’algorithme ApMin-generique produit bien un arbre de poids minimum du graphe de départ. En effet,
après l’initialisation (ligne 1 et 2), l’ensemble \(T\) est vide, ce qui implique que le couple \((S,T)\) est bien un sous-graphe d’un arbre de poids minimum de \((G,p)\) ;
à chaque itératon de la boucle Tant que (ligne 3) on ajoute une arête sûre dans \(T\), ce qui implique qu’à chaque itéarion le couple \((S,T)\) est bien un sous-graphe d’un arbre de poids minimum de \((G,p)\) ; et
lorsque l’algorithme se termine la condition de la boucle Tant que est fausse ce qui implique que \(k\) vaut \(n-1\) et donc que \(T\) est un sous-graphe à \(n-1\) arêtes d’un arbre de poids minimum. Comme tout arbre de poids minimum contient exactement \(n-1\) arêtes, on déduit que \(T\) est bien nécessairement un arbre de poids minimum lorsque l’algorithme se termine.
Afin de proposer un algorithme utilisable en pratique pour calculer un arbre de poids minimum, il reste à proposer un moyen efficace de détecter des arêtes qui sont sûres. C’est précisément l’objet de la prochaine section.
Algorithme de Kruskal¶
L’algorithme de Kruskal est une particularisation de l’algorithme ApMin-generique. A chaque itération, une arête sûre est détectée et ajoutée à l’arbre de poids minimum en construction. Pour détecter une arête sûre, l’idée consiste à rechercher une arête de poids le plus faible possible parmi les arêtes qui relient deux composantes connexes distinctes de l’arbre de poids minimum partiel en construction (désigné par \(T\)). Pour réaliser cela,
on initialise au début de l’algorithme un tableau des arêtes du graphe triées par ordre croissant de poids ; et
à chaque itération, on recherche dans ce tableau l’arête de plus petit indice qui relie deux composantes connexes distinctes de \(T\). On peut observer qu’il n’est pas nécessaire de reparcourir le tableau trié depuis le début à chaque itération. En effet, il suffit de recommencer le parcours à l’indice de la précédente arête ajoutée à \(T\) car les arêtes aux indices inférieurs ont déjà été considérées et sont donc soit déjà dans \(T\), soit sont formées des deux sommets appartenant à la même composante connexe de \(T\).
La description en pseudo-langage de l’algorithme de Kruskal est donnée ci-dessous.
Algorithme de Kruskal
Données : Un graphe pondéré connexe \((G,p)\) à \(n\) sommets et \(m\) arêtes, avec \(G=(S,A)\)
Résultat : Un ensemble d’arêtes \(T\) tel que le couple \((S,T)\) est un arbre de poids minimum de \(G\)
\(T := \emptyset\)
\(k := 0\)
// variable utilisée pour compter le nombre d'arêtes dans T\(i := 0\)
// variable utilisée pour parcourir les arêtes par poids croisssantTrier les aretes de \(A\) par ordre de poids croissant, c’est-à-dire
Déterminer le tableau \(O\) composé des \(m\) arêtes de \(G\) tel que
\(A = \{O[0], \ldots, O[m-1]\}\) ; et
\(p(O[i]) \geq p(O[i-1])\) pour tout \(i\) dans \(\{1, \ldots, m-1\}\)
Tant que \(k < n-1\) Faire
\(\{x,y\} = O[i]\)
// selectionner pour x et y les extrémités de la i-ème arête du tableau trié
- Si \(y\) n’appartient pas à \(CC( (S,T) ,x)\) 2 Alors
// l'arête {x,y} est sûre
\(T := T \cup \{\{x,y\}\}\)
\(k := k+1\)
\(i := i+1\)
Notes
- 2
Nous rappelons que \(CC((S,T), x)\) désigne la composante connexe du graphe \((S,T)\) qui contient \(x\) et que celle ci peut être obtenue en temps linéaire avec l’algorithme CC.
Exemple d’exécution (graphe des villes)
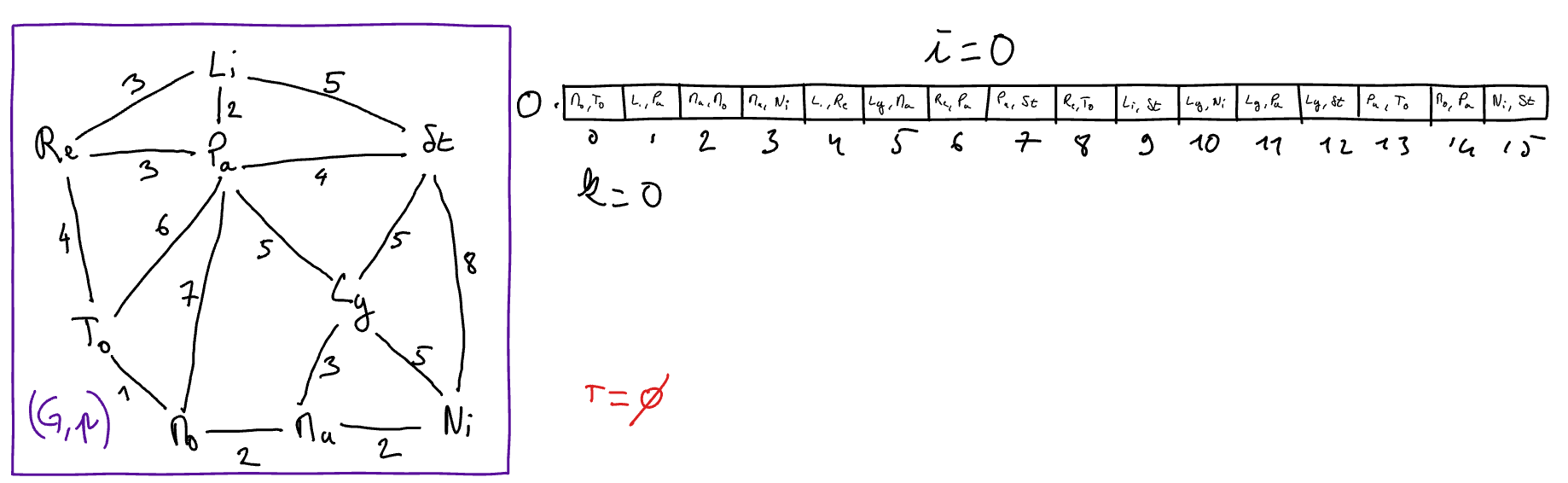
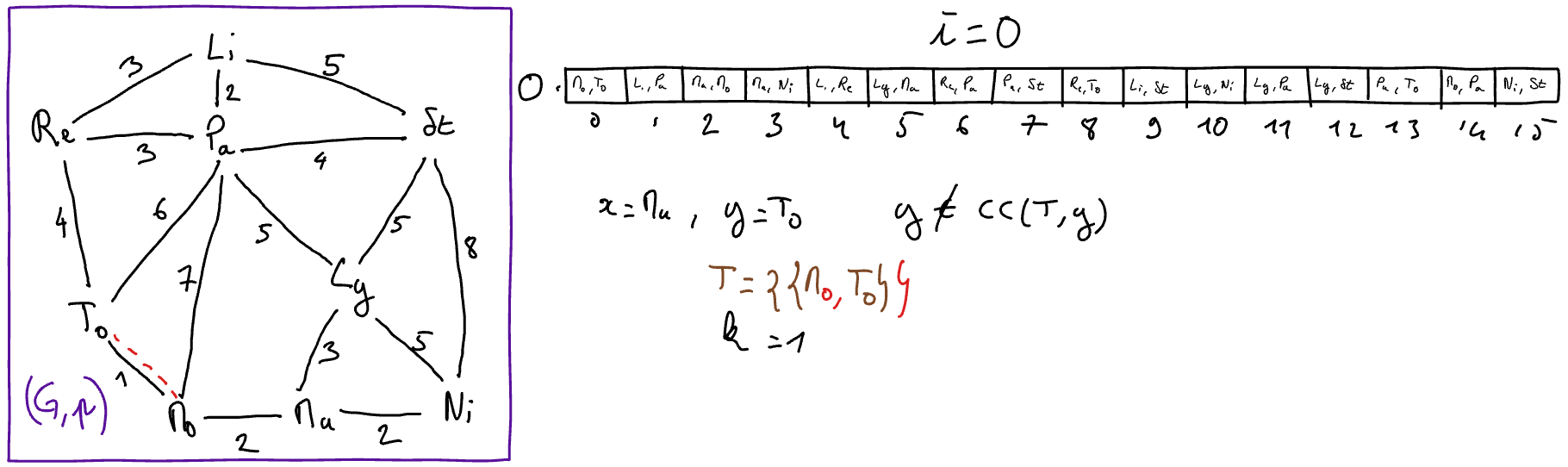
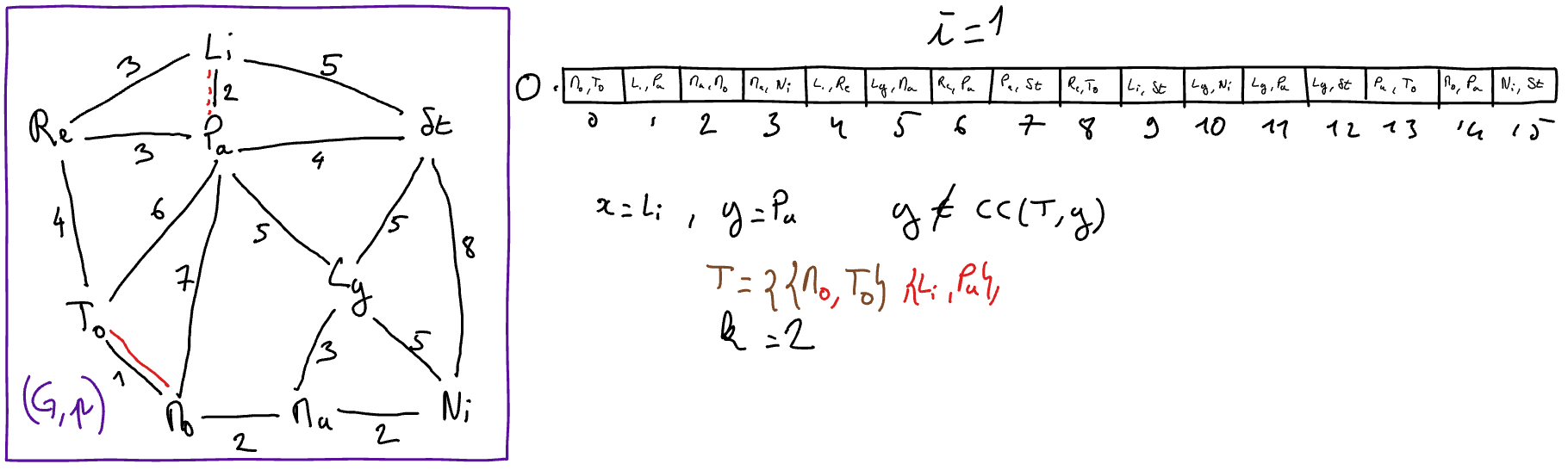
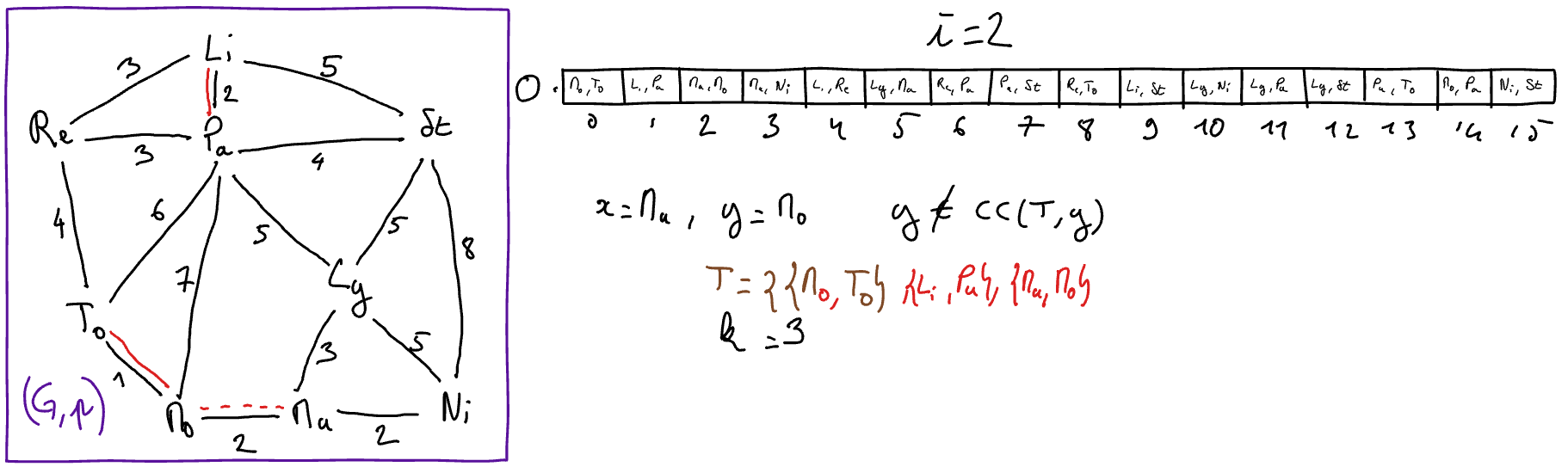

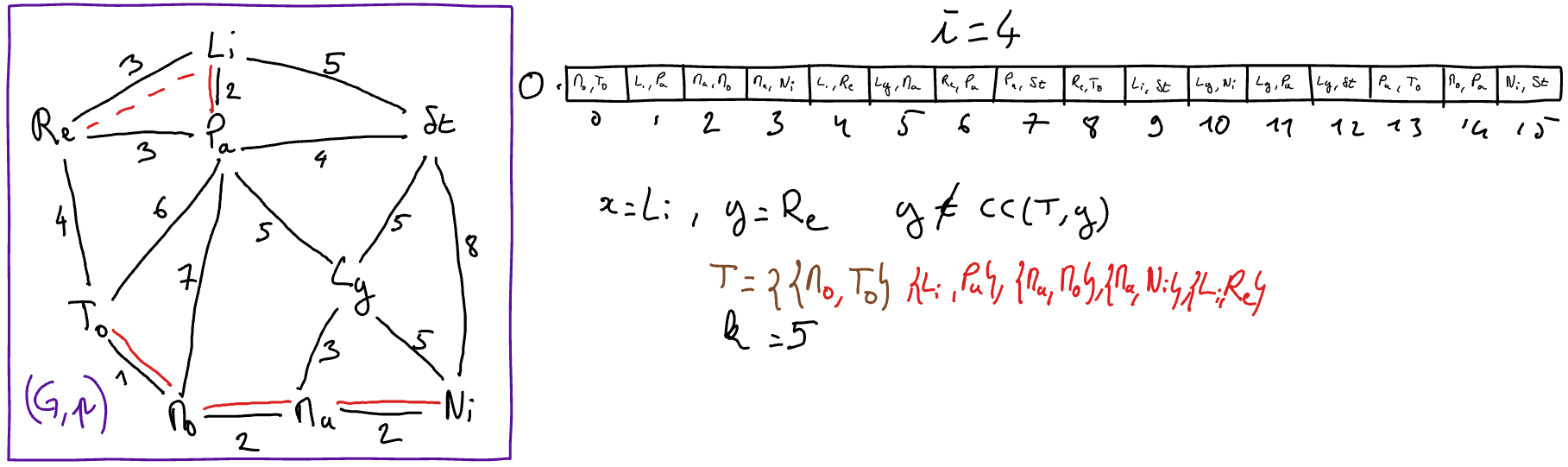
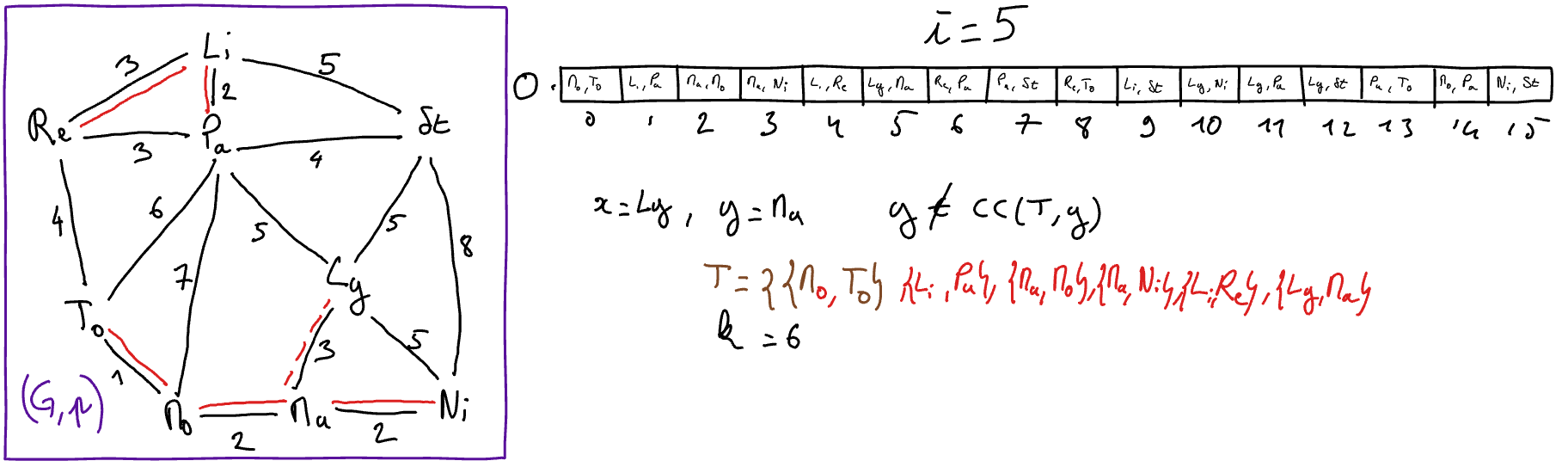
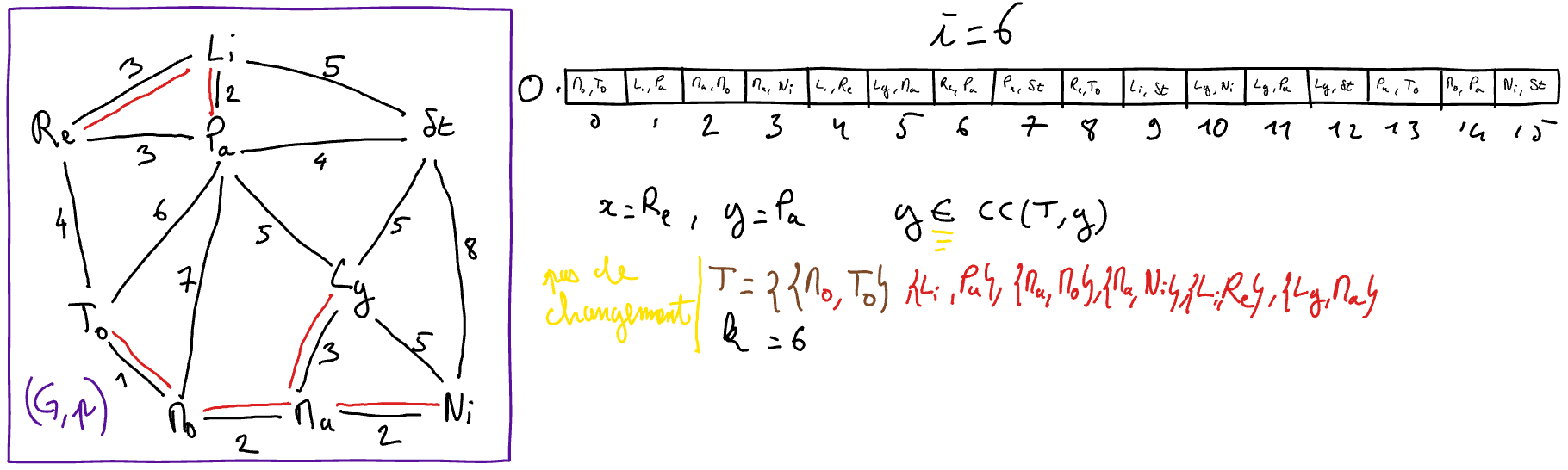
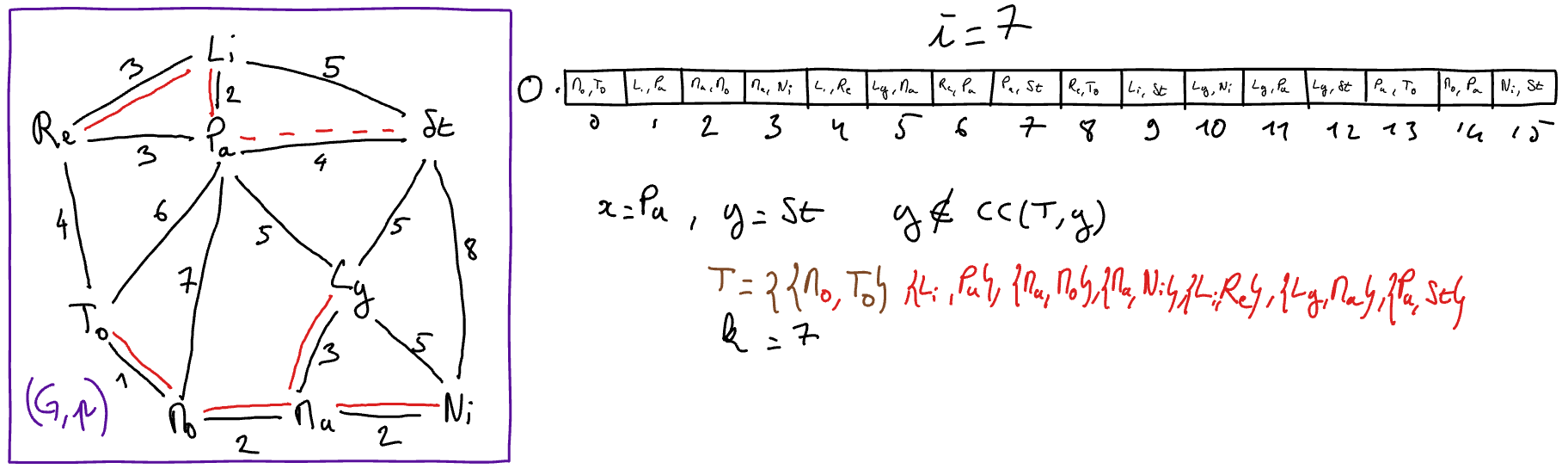
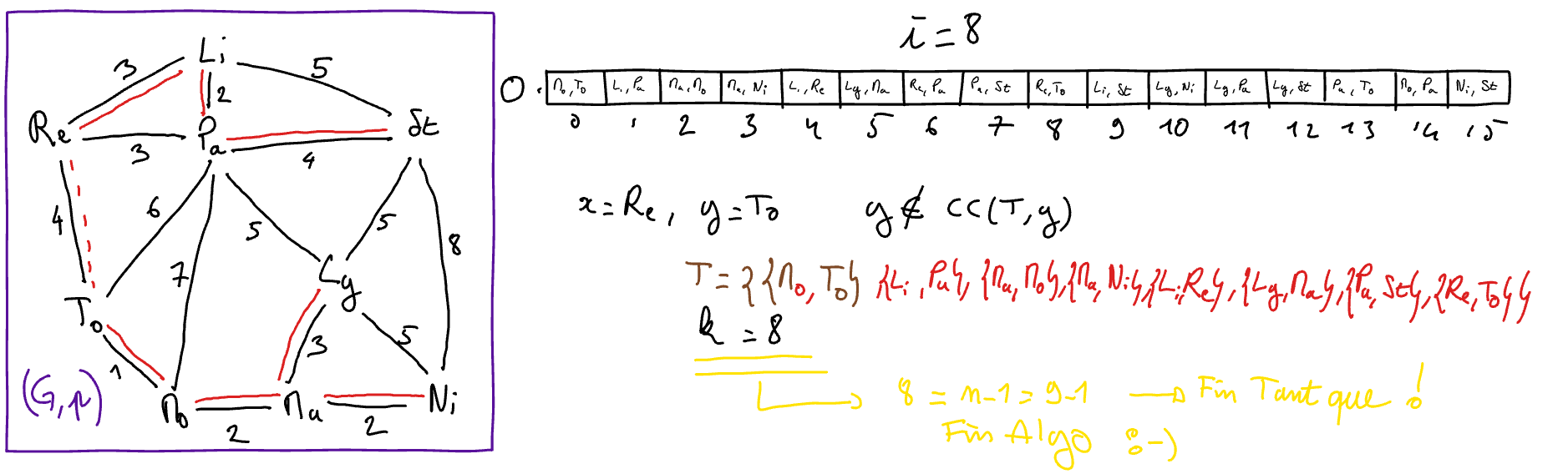

Choix des structures de données et Analyse de complexité¶
Pour analyser la complexité de l’algorithme de Kruskal, nous allons supposer que :
l’ensemble \(A\) des arêtes de \(G\) est représenté par tableau d’arêtes
l’arbre de poids minimum \((S,T)\) est représenté par tableau de listes chaînée.
Analysons la complexité de chaque ligne de l’algorithme de Kruskal.
La ligne 1 consiste à initialiser \(T\), cela peut être effectué avec une complexité \(O(n)\) (une liste vide pour chaque sommet du graphe)
Les lignes 2 et 3 ont une complexité en temps constant.
La ligne 4 consiste à trier \(m\) arêtes ce qui peut être effectué avec un algorithme de tri standard en \(O(n\log(n))\).
La condition de continuation de la boucle Tant que (ligne 5) peut être testée en temps constant et elle est testée au plus \(m+1\) fois au cours de l’algorithme. En effet, dans le pire cas, l’arête de poids le plus élevé (donc positionnée à l’indice \(m-1\) du tableau \(O\)) appartient à l’arbre de poids minimum. Il faut donc avoir parcouru toutes les autres arêtes du graphe avant de l’insérer dans \(T\). Dans ce cas, le corps de la boucle Tant que est répété \(m\) fois et le test est effectué une fois de plus. La complexité de la ligne 5 est donc \(O(m)\).
La ligne 6 est exécutée au plus \(m\) fois (pour les raisons évoquées au point précédent) et sa compléxité est en \(O(m)\).
Le test de la ligne 7 est également répété au plus \(m\) fois. Pour évaluer ce test, il est nécessaire de trouver la composante connexe de \((S,T)\) qui contient \(x\). Cette opération est en temps \(O(|S| + |T|)\) en utilisant l’algorithme CC. Le nombre d’arêtes de \(T\) est majoré par \(n-1\) car \(T\) est un arbre à la fin de l’algorithme. La complexité de la ligne 6 est donc \(O(mn)\).
Les lignes 7 et 8 sont répétées au plus \(n-1\) fois (une fois pour chaque arête insérée dans \(T\)). La complexité de ces lignes est donc \(O(n)\).
La ligne 9 est répétée au plus \(m\) fois, sa complexité est en \(O(m)\).
Globalement la complexité de l’algorithme de Kruskal est donc en \(O(m\log(m) + mn)\). Cette complexité peut être réduite à \(O(m\log(m) + \alpha(n)n)\), où \(\alpha\) est une fonction qui croit extrêmement lentement (typqiement \(\alpha(n)\) est inférieur à 5 quand \(n\) est égal au nombre d’atomes de l’univers), en utilisant l’algorithme Union-Find de Robert Tarjan pour gérer dynamiquement les composantes connexes de \(T\). Enfin, il est à noter que dans certains cas fréquents en pratique, on peut trier les arêtes en temps linéaire (par exemple pour des poids entiers dans un ensemble de valeurs pas trop grand). Dans ce cas la compléxité de l’algorithme est en \(O(mn)\), réduit à \(O(\alpha(n)n)\) en utilisant l’algorithme Union-Find.
Preuve de correction de l’algorithme de Kruskal¶
A venir pour la prochaine édition du cours graphes et algorithmes :-) Cette preuve repose sur un “théorème de coupure” qui formalise l’idée donnée au début de la section précédente.
Pour aller plus loin…¶
Nous contribuons à ESIEE Paris, au sein du Laboratoire d’Informatique Gaspard Monge, à faire progresser la recherche sur les arbres de poids minimum (et sur l’algorithme de Kruskal) dans le contexte de l’analyse d’images et de l’intelligence artificielle ! Pour en savoir plus, vous pouvez par exemple jeter un oeil aux articles scientifiques suivants que nous avons écrits :
Watershed cuts: Minimum spanning forests and the drop of water principle, J Cousty, G Bertrand, L Najman, M Couprie, IEEE transactions on pattern analysis and machine intelligence 31 (8), pages 1362-1374, 2009.
Playing with kruskal: algorithms for morphological trees in edge-weighted graphs, L Najman, J Cousty, B Perret, International Symposium on Mathematical Morphology and Its Applications to Signal and Image Processing, pages 135-146, 2013.
Hierarchical segmentations with graphs: quasi-flat zones, minimum spanning trees, and saliency maps, J Cousty, L Najman, Y Kenmochi, S Guimarães, Journal of Mathematical Imaging and Vision 60 (4), 479-502, 2018
Si vous voulez rejoindre notre équipe de recherche, nous pouvons monter avec et pour vous des sujets de projets E4, de stages et envisager des poursuites en doctorat pour les plus passionés. N’hésitez pas à nous contacter ! Nous prendrons plaisir à vous parler de nos travaux de recherche. Nous avons même lancé un programme spécifique pour vous initier à la recherche dès la E4 :