Algorithmes pour le
traitement de séquences. |
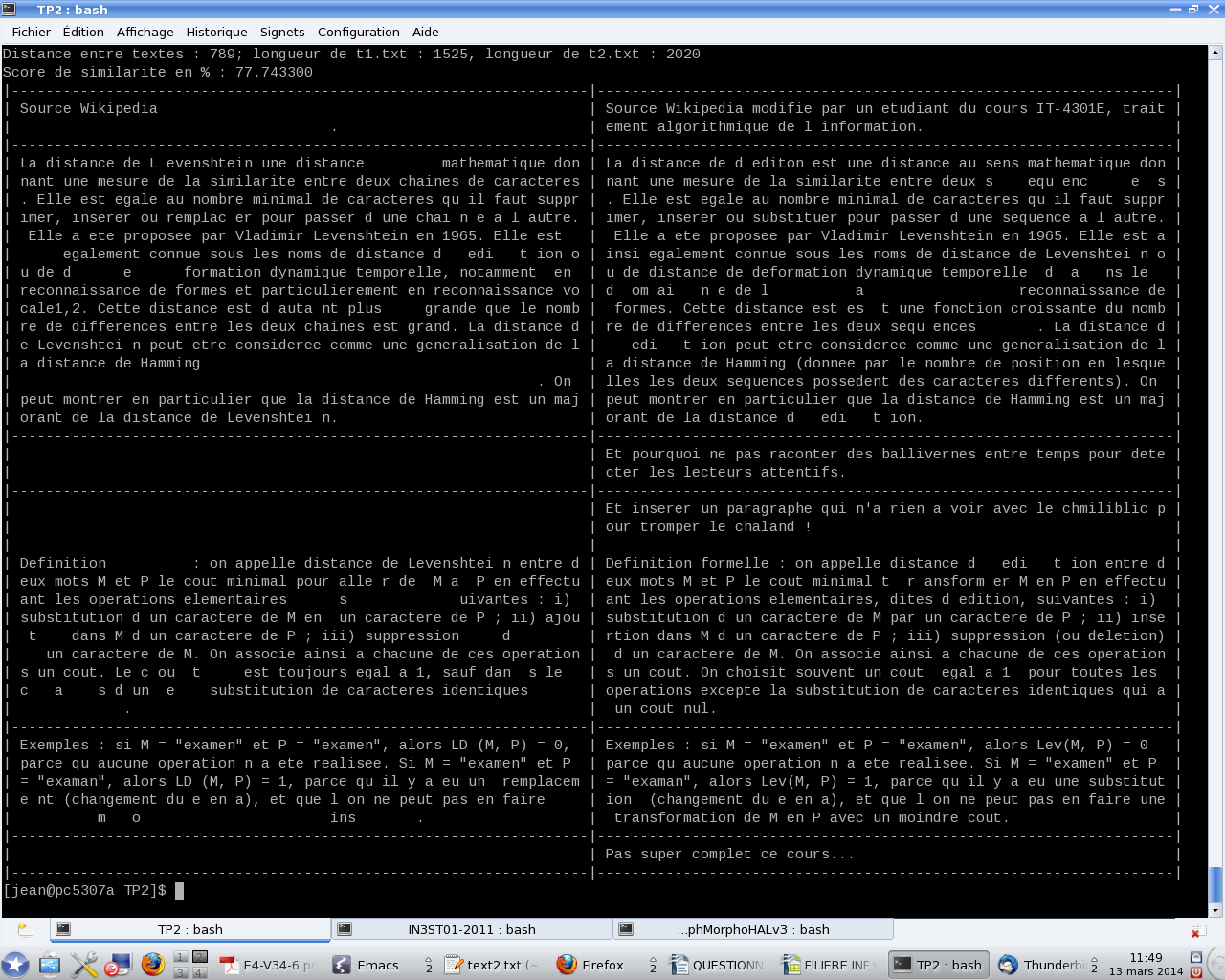
On s’intéresse à la conception d’un logiciel d’aide à la détection de plagiat comme celui illustré Figure 1. Les algorithmes étudiés ont néanmoins une portée plus générale et sont intéressants dans d’autres contextes comme la mise en correspondance de séquences ADN ou de signaux, la visualisation des différences entre textes (par exemple utilitaire diff sous linux ou svn diff dans le contexte d’un logiciel gestions de version) etc.
Pour aider à détecter un plagiat, on souhaite afficher simultanément le texte soupçonné d’être un plagiat et le texte plagié de manière à mettre en lumière les correspondances (voir par exemple l’illustration de la Figure 1). Pour cela on essaye “d’aligner au mieux” les deux textes. Par exemple, les textes x = abbacb et y = cbbbacab peuvent être alignées de la manière suivante :
| étirement de x | a | b | ␣ | b | a | c | ␣ | b |
| étirement de y | c | b | b | b | a | c | a | b |
| indice | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
Pour aligner x et y il faut étirer les deux mots afin qu’ils aient la même longueur. Étirer un mot signifie simplement que l’on insère dans ce mot un ou plusieurs caractères blancs de manière à le rallonger.
Définition 1. Soit x une séquence définie sur un alphabet A et ␣ une lettre n’appartenant pas à A. On dit que la séquence x′ définie sur l’alphabet A ∪ {␣} est un étirement de x si x est exactement la séquence obtenue en retirant toutes les occurrences du caractères ␣ dans x′.
Définitions 2. Soient x et y deux séquences définies sur A. Un alignement de x et y est une paire de séquences (x′,y′) définies sur A ∪{␣} telle que :
Dans l’alignement (x′,y′) de x et y présenté ci-dessus, on voit que 3 caractères (aux indices 0,2 et 6) sont mal appariés. Ce nombre constitue une bonne indication de la qualité de l’alignement considéré : plus il est petit, meilleur est l’alignement et plus la probabilité de détecter un plagiat est élevée. En particulier, lorsque ce nombre est égal à 0, l’alignement est parfait et le plagiat est complet (les deux textes sont identiques).
Définitions 3. Le score d’un alignement (x′,y′) est la grandeur d(x′,y′) égale au nombre de caractères mal appariés entre x′ et y′, c’est-à-dire le nombre d’indices i ∈ {0, …, |x′|−1} pour lesquels x′[i] ≠ y′[i]. Un alignement (x′,y′) de deux séquences x et y définies sur A est dit optimal (pour d) si son score est inférieur ou égal au score de tout autre alignement de x et y.
Proposer un algorithme en O(|x| × |y|) pour calculer le score d’un alignement optimal entre x et y (indications : on essaiera de se ramener à un problème connu).
On considère la matrice T de taille (|x|+1) × (|y|+1) telle que T[i][j] est le score d’un alignement optimal entre xi et yj, où xi et yj désignent les préfixes de x et de y de longueur i et j respectivement.
Étant donnée la matrice T (obtenue par exemple avec l’algorithme de la question 1) et les séquences x et y, proposez un schéma de programme retournant un alignement optimal (x′,y′) de x et y.
Évaluer la complexité de calcul de l’algorithme proposé; si celle-ci n’est pas linéaire, proposez un autre algorithme de complexité linéaire.
Ressource : Pour répondre à cette question, vous pouvez utiliser le fichier source TD2.c qui contient entre autre :
Implémentez les algorithmes des questions 1 et 2 et testez les en affichant un alignement optimal de texte1.c et texte2.c.
La méthode proposée aux questions précédentes fonctionne correctement pour aligner un texte comprenant une seule ligne ou un seul paragraphe. On se propose désormais d’aligner et mettre en correspondance les différentes lignes/paragraphes d’un texte. Il s’agit donc de chercher à apparier les lignes (et non pas les caractères) d’un premier texte avec celles d’un second. Proposez une méthode, un algorithme de résolution et une implémentation pour cette nouvelle fonctionnalité (indications : on cherchera à se ramener un problème connu, dont on possède déjà une implémentation :)).
Vous pourrez tester votre méthode sur les fichiers t1.txt et t2.txt. Vous devriez obtenir un résultat qui ressemble fortement à celui de la Figure 2
Ce document a été traduit de LATEX par HEVEA