1. Introduction
Ceci est une présentation des principales fonctionnalités du langage R.
R est un langage de programmation et un logiciel libre destiné aux statistiques et à la science des données soutenu par la R Foundation for Statistical Computing [Wikipedia].
1.1. L’écosystème R
Le langage R proprement dit est un langage assez ancien issu du monde des statistiques. On y fera référence avec les termes « base R » ou « R core ». De façon générale, l’utilisation des fonctions bas niveau du langage de base est déconseillée, car elles sont peu intuitives et manquent d’homogénéité.
On cherchera donc systématiquement à mettre en oeuvre les fonctions appartenant à un éco système nommé tidyverse qui contient plusieurs packages partageant tous la même philosophie, la même grammaire et les mêmes structures de données. L’utilisation des fonctions de Tidyverse est la façon moderne et efficace de travailler avec R, ce qui facilite beaucoup sa prise en main.
On travaillera exclusivement avec les fonctions de cette famille de packages qui présentent tous une interface et un fonctionnement communs.
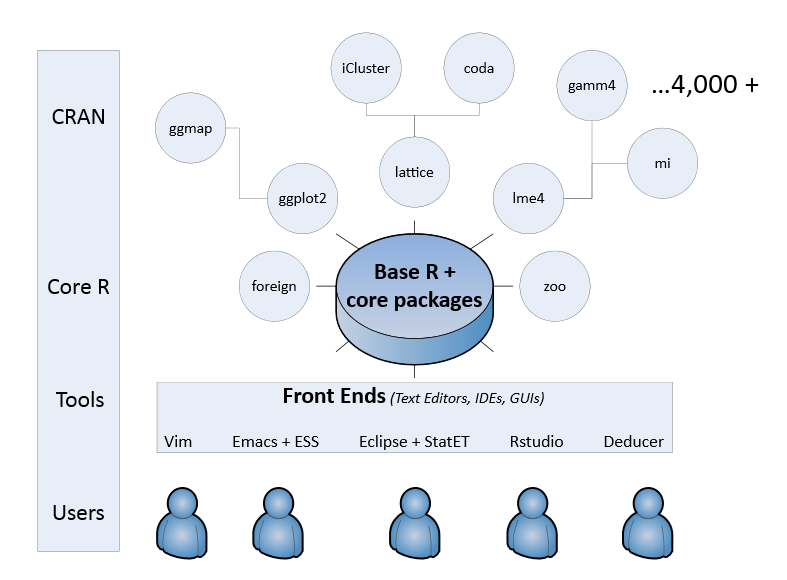
Cependant, il est nécessaire de comprendre les particularités de R, et donc d’étudier les structures de données de base, ainsi que la façon de les manipuler.
Avertissement
Lorsqu’on effectue des requêtes internet pour savoir comment mettre en oeuvre un traitement sur les données, il faudra être attentif et sélectionner l’information privilégiant les fonctions Tidyverse plus que celles du core langage.
1.2. R vs Python
Dans le domaine de la Data Science, les deux langages prépondérants sont R et Python.
Pour faire court, R est un langage Open Source issu du monde des statistiques et dispose donc d’une grande quantité de packages adressant des domaines très spécifiques des statistiques.
Python est issu lui du monde de l’informatique et s’est rapidement imposé comme un langage puissant et de haut niveau, ce qui rend le compact compact et relativement simple à lire. Il est également doté d’un écosystème très performant et de structures de données bien adaptées à la Data Science.
Lorsqu’on débute l’apprentissage, on trouvera à Python de grandes qualités pour ce qui concerne la récupération de données, les performances, la syntaxe, la productivité… On appréciera son spectre large qui lui permet d’être performant dans d’autres domaines applicatifs et sa relative facilité d’apprentissage.
De son côté R dispose d’un mécanisme performant d’installation de packages. C’est également une référence dans le domaine de la data visualisation et de l’analyse statistique.
Les deux langages disposent d’IDE performants, et d’une communauté active. Ils permettent tous deux de mixer du code et du texte sous forme de notebooks et disposent de bibliothèques adaptées au Machine Learning.
La connaissance des deux est un atout majeur dans le monde de la Data Science.