13. Importer des données
Jusqu’à présent, les données utilisées provenaient de datasets inclus dans les packages R et Tidyverse ou étaient fournies sous la forme d’objets R.
On va explorer l’utilisation de données externes fournies sous la forme de fichiers.
La lecture de données est relativement simple en R, à la condition express que les données soient strictement structurées. La bonne pratique est d’effectuer le travail de nettoyage et de formattage avec un autre langage, avant d’importer les données dans R. Python est un excellent candidat pour ces tâches.
Par la suite, les données importées seront structurées pour que l’importation se passe sans difficulté.
On va se contenter ici d’importer les données à partir de fichiers texte, mais on trouvera un document exhaustif sur l’importation de données dans le R Data Import/Export manual. Ca couvre également la connexion à des bases de données.
13.1. La fonction read.table()
La fonction utilisée pour l’importation de données à partir de fichiers texte est read.table() dont on trouvera la documentation complète ici.
Pour une importation réussie des données dans une data.frame, le fichier texte doit avoir un format bien défini:
la première ligne du fichier doit contenir le nom de chaque variable de la data.frame.
chaque ligne supplémentaire doit être composée d’un label et de valeurs pour chacune des variables décrites sur la première ligne.
Si cette structuration n’est pas respectée, l’importation peut conduire à des erreurs où à des résultats imprévisibles.
A titre d’exemple, un fichier bien formé ressemble à ça:
Price Floor Area Rooms Age Cent.heat
01 52.00 111.0 830 5 6.2 no
02 54.75 128.0 710 5 7.5 no
03 57.50 101.0 1000 5 4.2 no
04 57.50 131.0 690 6 8.8 no
05 59.75 93.0 900 5 1.9 yes
...
Le comportement par défaut est que les valeurs numériques sont importées avec le mode numeric et que les variables non numériques sont importées comme des factors (Cent.heat dans cet exemple). Ce comportement par défaut peur être modifié en passant des paramètres à la fonction read.table().
Le fichier utilisé pour cet exemple se trouve ici.
En utilisant les paramètres par défaut, on construit la data.frame de la façon suivante:
> HousePrice <- read.table("houses.data")
La data.frame importée:
> HousePrice
Price Floor Area Rooms Age Cent.heat
01 52.00 111 830 5 6.2 no
02 54.75 128 710 5 7.5 no
03 57.50 101 1000 5 4.2 no
04 57.50 131 690 6 8.8 no
05 59.75 93 900 5 1.9 yes
Il peut arriver que les observations contenues dans le fichier ne disposent pas de labels. Dans ce cas, les labels sont construits à la volée en utilisant les entiers consécutifs.
Un fichier sans label pour les observations ressemble à ça:
Price Floor Area Rooms Age Cent.heat
52.00 111.0 830 5 6.2 no
54.75 128.0 710 5 7.5 no
57.50 101.0 1000 5 4.2 no
57.50 131.0 690 6 8.8 no
59.75 93.0 900 5 1.9 yes
...
On le lit (presque) de la même façon:
> HousePrice <- read.table("houses.data", header=TRUE)
Il faut cependant spécifier le paramètre header=TRUE pour indiquer que la première ligne contient le nom des variables (c’était implicite précédemment car les lignes d’observations étaient identifiées par un label).
La data.frame importée:
> HousePrice
Price Floor Area Rooms Age Cent.heat
1 52.00 111 830 5 6.2 no
2 54.75 128 710 5 7.5 no
3 57.50 101 1000 5 4.2 no
4 57.50 131 690 6 8.8 no
5 59.75 93 900 5 1.9 yes
13.2. Les datasets fournis
Comme indiqué précedemment, R et Tidyverse fournissent un grand nombre de datasets fort utiles pour prendre en main et tester les fonctions de manipulation de données.
Pour obtenir une liste de ces datasets:
> data(package = .packages(all.available = TRUE))
Chacun de ces dataset est accessible par son nom (le package doit avoir été importé).
On peut à titre d’exemple s’intéresser aux datasets Freedman, storms, starwars, gapminder, lakers, etc…
> library(lubridate)
Attaching package: ‘lubridate’
The following objects are masked from ‘package:base’:
date, intersect, setdiff, union
> summary(lakers)
13.3. Application : le Titanic
On va s’intéresser aux données relatives au naufrage du Titanic qui s’est déroulé dans la matinée du 15 avril 1912. On trouvera une source complète d’informations sur l”Encyclopedia Titanica.
Créer un nouveau projet dans RStudio. Télécharger les données stockées au format texte (csv).
13.3.1. Importation
Observer la structure du fichier dans un éditeur de texte. Utiliser la fonction read.table() pour lire les données.
Quel est la nature de l’objet retourné par cette opération ?
Utiliser la fonction
as_tibble()pour transformer l’objetAfficher le
tibbleainsi construitComment peut on afficher les 20 premières lignes ?
Quelles sont les informations présentes ?
Sont elles toutes renseignées ?
Utiliser les fonctions
summary()etstr()pour avoir un aperçu des données.Quel est le type de chacune des variables ?
Construire une table de contingence pour chacune des variable. Quelles premières conclusions en tirer ?
13.3.2. Nettoyage des données
Il est fréquent qu’un jeu de données contienne des valeurs manquantes. Une opération courante est d’isoler les observations complètes (aucune valeur manquante) ou au contraire les observations incomplètes (au moins une valeur manquante).
Astuce
S’il subsiste des valeurs manquantes dans un vecteur numérique, les fonctions courantes (mean() par exemple) ont un paramètre na.rm qui permet d’écarter ces valeurs au moment du traitement.
Rechercher les observations incomplètes (avec au moins une valeur manquante) avec la fonction filter() à laquelle on passera un vecteur logique construit à partir des fonctions if_any() ou if_all(), auxquelles on passera deux paramètres:
un opérateur de sélection de variable (la fonction
everything()les prend toutes)la fonction à appliquer à chacune des variables sélectionnées
Le vecteur logique ainsi crée sera réduit par if_any() ou if_all() à une seule valeur logique.
On consultera:
On doit obtenir:
Age Class.Dept Fare.today Joined Survived
1 39 1st Class NA Belfast FALSE
2 NA 1st Class 2390 Southampton FALSE
3 40 1st Class NA Belfast FALSE
...
198 26 Engine NA Belfast FALSE
199 36 Engine NA Southampton FALSE
200 29 Engine NA Southampton FALSE
[ reached 'max' / getOption("max.print") -- omitted 723 rows ]
Identifier les trois premières observations de ces observations incomplètes.
On doit obtenir:
Age Class.Dept Fare.today Joined Survived
1 39 1st Class NA Belfast FALSE
2 NA 1st Class 2390 Southampton FALSE
3 40 1st Class NA Belfast FALSE
L’index de la data.frame initiale a été perdu dans l’opération. Pour le conserver, il faut explicitement en faire une variable avant le filtrage avec la fonction tibble::rownames_to_column().
On doit obtenir:
index Age Class.Dept Fare.today Joined Survived
1 8 39 1st Class NA Belfast FALSE
2 47 NA 1st Class 2390 Southampton FALSE
3 71 40 1st Class NA Belfast FALSE
La fonction réciproque tibble::column_to_rownames() permet de supprimer la variable temporaire et de renommer les observations avec l’index de la data.frame originale.
On doit obtenir:
Age Class.Dept Fare.today Joined Survived
8 39 1st Class NA Belfast FALSE
47 NA 1st Class 2390 Southampton FALSE
71 40 1st Class NA Belfast FALSE
De la même façon, rechercher les observations complètes, sans aucune valeur manquante. Combien y en a t-il ?
On doit obtenir:
Age Class.Dept Fare.today Joined Survived
1 29.0 1st Class 16300 Southampton TRUE
2 0.9 1st Class 11700 Southampton TRUE
3 2.0 1st Class 11700 Southampton FALSE
...
206 25.0 1st Class 6350 Cherbourg TRUE
207 65.0 1st Class 2050 Cherbourg FALSE
208 44.0 1st Class 6950 FALSE
[ reached 'max' / getOption("max.print") -- omitted 1085 rows ]
On peut cibler une (ou plusieurs) variable particulière en la passant en argument de if_any() ou if_all().
Rechercher les trois premières observations pour lesquelles l’age est manquant.
On doit obtenir:
Age Class.Dept Fare.today Joined Survived
47 NA 1st Class 2390 Southampton FALSE
180 NA 1st Class 2050 Southampton FALSE
182 NA 1st Class 2700 Southampton FALSE
Astuce
Lorsque peu de variables sont en jeu, on peut construire le vecteur logique plus simplement :
> df %>% filter(is.na(Age))
La valeur ajoutée de if_any() ou if_all() réside dans leur capacité à réduire un grand nombre de valeurs logiques.
Rechercher les observations pour lesquelles l’age et le montant du billet sont manquant.
On doit obtenir:
Age Class.Dept Fare.today Joined Survived
1516 NA Engine NA Southampton FALSE
1737 NA Engine NA Southampton FALSE
2153 NA Victualling NA Southampton FALSE
Observer les lignes 208, 209 et 210 de la data.frame originale. Ces lignes sont elles identifiées comme des observations incomplètes ? Pour répondre à cette question:
construire la
data.frameinc_obsdes observations incomplètes.créer une variable
indexà partir du nom des observations avec la fonctiontibble::rownames_to_column(). Quel est le type de la variableindex?convertir la variable index en un type propice à la comparaison avec la fonction
mutate()à laquelle on passe la fonctionacross()en argumentfiltrer selon les observations recherchées
Construire l’instruction complète permettant de s’assurer que les lignes 208, 209 et 210 sont, ou ne sont pas dans les observations incomplètes.
Quelle opération doit on réaliser pour ajouter ce genre d’observation aux observations incomplètes ? Par défaut R affecte la valeur NA aux variables numériques et logiques pour lesquelles il détecte un champ vide, mais pas aux variables de type character.
Utiliser la fonction mutate() à laquelle on passe la across() qui prend deux arguments:
les colonnes sélectionnées par position, par nom ou par type avec la fonction
where()la fonction
na_if()à appliquer, précédée d’un tilde~pour en faire une formule..représente la variable sélectionnée.
Pour chacune de ces fonctions, on lira attentivement la documentation et les exemples associés.
Astuce
Il est souvent plus efficace de convertir en NA les valeurs concernées lors du processus de lecture. N’y a t’il pas un paramètre de la fonction read.table() qui permet de considérer les chaines de caractères vides comme des valeurs NA ?
Construire la data.frame com_obs des observations complètes.
Observer le résultat de la fonction summary() appliquée à la data.frame des observations complètes. On doit obtenir:
Age Class.Dept Fare.today Joined
Min. : 0.00 1st Class:310 Min. : 245 Belfast : 1
1st Qu.:21.00 2nd Class:271 1st Qu.: 612 Cherbourg :271
Median :27.00 3rd Class:701 Median : 1120 Queenstown :120
Mean :29.32 Mean : 2600 Southampton:890
3rd Qu.:37.00 3rd Qu.: 2420
Max. :74.00 Max. :39600
Survived
Mode :logical
FALSE:786
TRUE :496
Est ce le cas ? Si non, quelles variables ne produisent pas les résultats escomptés.
Comment peut on les modifier avec la fonction mutate() ?
Astuce
Il existe un paramètre de la fonction read.table() permettant de convertir les chaines de caractères en facteurs à la lecture des données.
13.3.3. Transformation
L”Encyclopedia Titanica fournit un certain nombre de statistiques. Nous allons en reconstruire certaines en utilisant R et Tidyverse. Il peut y avoir des écarts mineurs dans les résultats obtenus, dus à des écarts entre les jeux de données utilisés.
On va utiliser les data.frame précédentes pour tirer quelques conclusions et tracer quelques graphiques.
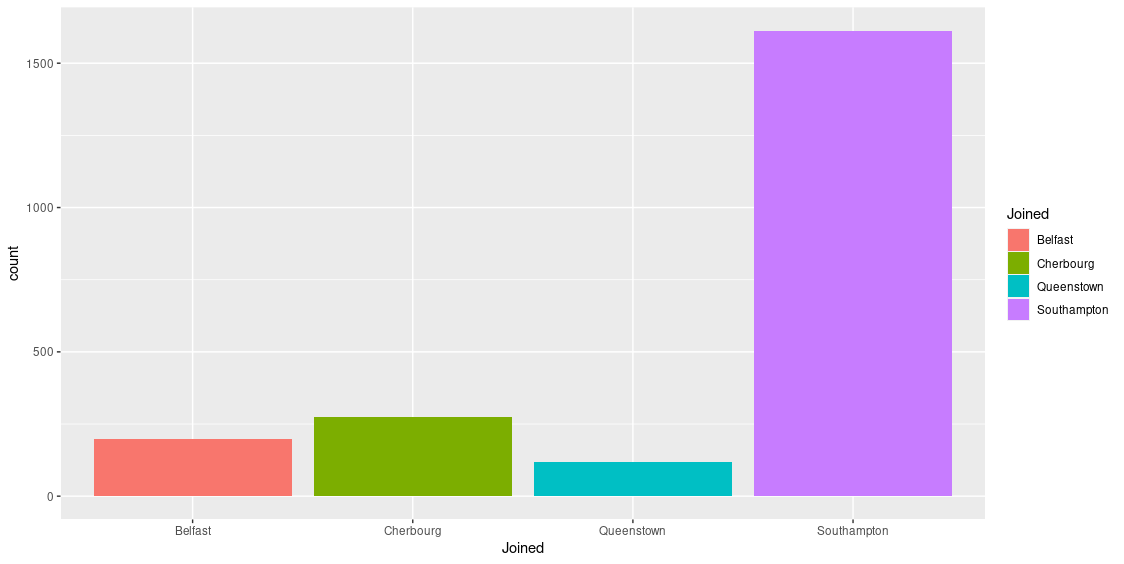
Combien de passagers ont embarqué à Belfast, Southampton ? Cherbourg ? Queenstown ?
Construire la figure ci dessous.
Astuce
La variable Joined contient des NA. On peut les éliminer en amont en construisant une data.frame spécifique. On peut également les écarter au moment de la construction de l’objet ggplot avec la fonction remove_missing() : la documentation.
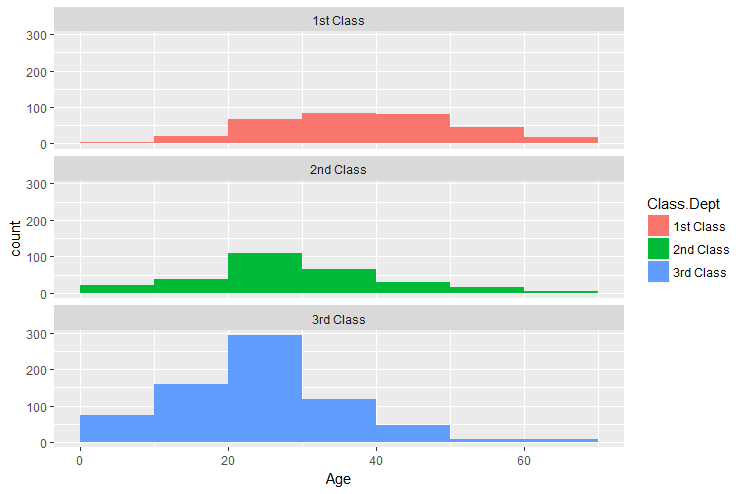
Tracer l’histogramme de l’age des passagers pour chaque classe.
Astuce
On peut utiliser la fonction stringr::str_detect() pour sélectionner les observations de la variable Class.Dept
Quels sont la moyenne, la médiane, et l’écart type le la variable Age pour chacune des valeurs de la variable Class.Dept ? On utilisera la fonction group_by() pour le groupement de données et la fonction summarize() pour la réduction.
Construire le flux de traitement conduisant à
# A tibble: 7 x 2
Class.Dept mean
<fct> <dbl>
1 1st Class 39.1
2 2nd Class 29.6
3 3rd Class 24.9
4 A la Carte 25.2
5 Deck 33.8
6 Engine 30.4
7 Victualling 31.3
Astuce
Les fonctions statistiques comme mean() acceptent le paramètre na.rm=TRUE pour écarter les NA avant traitement.
Modifier le groupement pour obtenir l’age moyen des survivants et des morts pour chacune des classes.
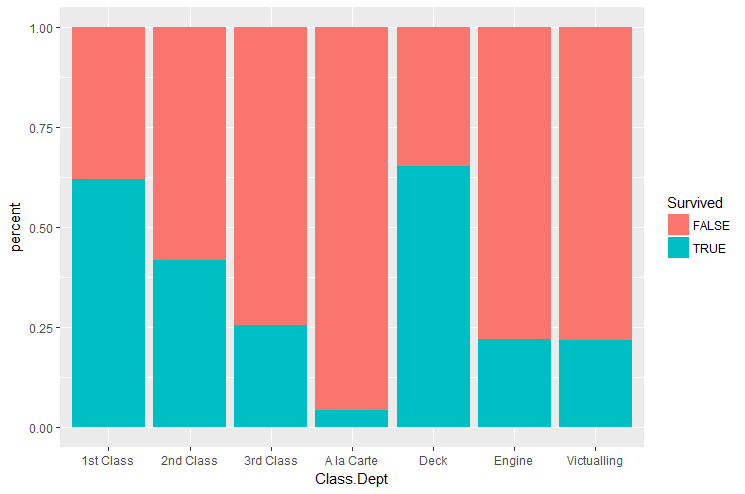
Compter le nombre de morts et de survivants pour chacune des classes de passagers et comparer les pourcentages.
# A tibble: 14 x 4
# Groups: Class.Dept [7]
Class.Dept Survived n percent
<fct> <lgl> <int> <dbl>
1 1st Class FALSE 123 0.380
2 1st Class TRUE 201 0.620
3 2nd Class FALSE 166 0.582
4 2nd Class TRUE 119 0.418
5 3rd Class FALSE 528 0.746
6 3rd Class TRUE 180 0.254
7 A la Carte FALSE 66 0.957
8 A la Carte TRUE 3 0.0435
9 Deck FALSE 23 0.348
10 Deck TRUE 43 0.652
11 Engine FALSE 253 0.778
12 Engine TRUE 72 0.222
13 Victualling FALSE 337 0.782
14 Victualling TRUE 94 0.218
Source: local data frame [14 x 4]
Groups: Class.Dept [7]
A partir du tibble précédent, tracer un barplot pour mettre en évidence le pourcentage de survivant pour chacune des catégories de passagers.