4. Un aperçu du fonctionnement de R
R est un langage de haut niveau permettant la manipulation et la visualisation de données. On va montrer ici quelques possibilités offertes par R avant d’approfondir chacune des étapes présentées ici.
Si vous ne comprenez pas en totalité les commandes utilisées, tout ça devrait s’éclaircir dans les chapitres suivants.
4.1. Les données
Le jeu de données utilisé provient de la plateforme gouvernementale Open Data. Il concerne la consommation de carburant et l’impact sur la pollution de l’air d’un ensemble de véhicules vendus en France en 2014.
Le jeu de données complet est disponible au téléchargement ici. Dans ce chapitre, on utilisera une version réduite, directement lisible dans R.

4.2. Création du projet
Ouvrir RStudio et créer un nouveau projet:
File > New Project > New Directory > New project.
overview
Create Project.
Placer le fichier vehicules-2014.RData dans le répertoire du projet. Il contient une version réduite des données et sera utilisé dans la suite de ce chapitre.
4.3. Importation de tidyverse
On s’assure que le package Tidyverse a été correctement installé en essayant de l’importer:
> library(tidyverse)

On obtient la liste des packages importés ainsi que les conflits de fonctions. Tidyverse s’installant au dessus du langage R core, il « masque » des fonctions de ce dernier. Par exemple:
filter()fait référence au packagedplyr(tidyverse) et non plus au packagestats(R core). On continue toutefois à avoir accès à cette dernière avec le chemin completstats::filter()
Cette information est pertinente lorsqu’on exécute un code ancien sur une machine sur laquelle Tidyverse est installé. Ce n’est pas notre cas.
Avertissement
Si l’importation échoue, il est vraisemblable que le package n’a pas été installé
> install.packages("tidyverse")
4.4. Lecture des données
Comme on l’a vu précédemment, un fichier .RData est une archive compressée d’objets R.
Charger les données en mémoire:
> load("vehicules-2014.RData")
Observer l’apparition de l’objet veh dans l’onglet « Environnement » de R Studio.
veh est une référence vers une structure de données de type data.frame contenant 59 observations (les lignes) et 27 variables (les colonnes). On peut assimiler cet objet à un onglet de tableur.
4.5. Interprétation des données
L’analyse de données nécessite une connaissance élémentaire (a minima) du domaine couvert par celles ci sous peine de tirer des conclusions hâtives voire erronées. Pour comprendre les grandeurs référencées, on jettera un oeil attentif au codebook. La plupart d’entre elles ont un nom explicite.
Exercice
A l’aide du codebook, identifier la signification de chacune des variables du jeu de données. Effectuer les recherches minimales nécessaires pour en comprendre le sens. Pour une connaissance élémentaire du contexte de la pollution de l’air, on s’intéressera à la ressource Air Quality in Europe.
Exercice
Identifier les polluants mesurés dans le jeu de données, ceux référencés par la page d’information précédente. En déduire la complétude des conclusions que l’on peut mettre en avant avec le jeu de données utilisé.
4.6. Un premier regard
Pour une première exploration du jeu de données, un clic sur la variable veh dans l’explorateur d’objets ouvre une fenêtre de type tableur qui organise les données en lignes et colonnes.
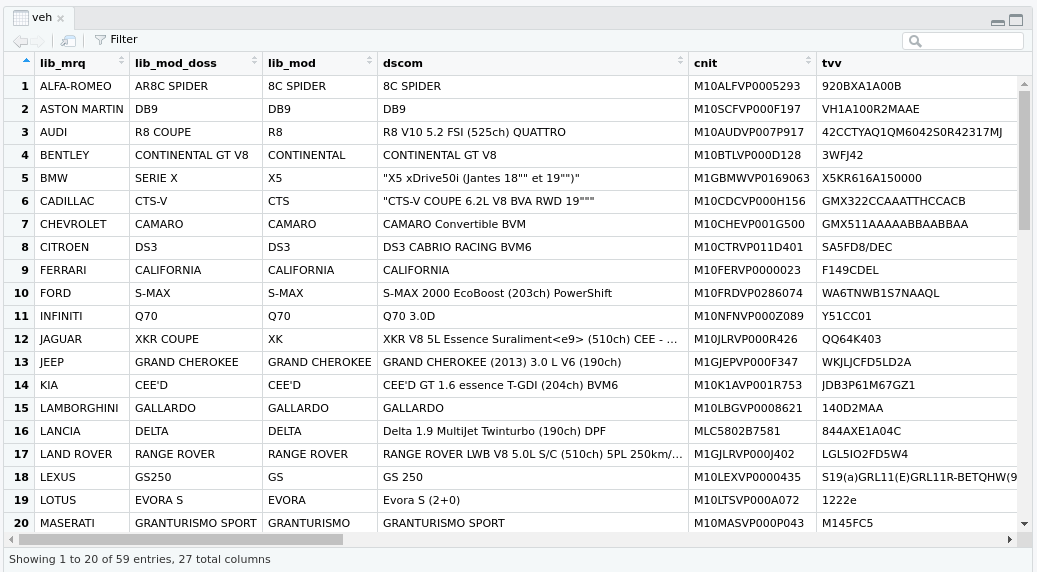
Ce clic est équivalent à la commande View() exécutée dans la console:
> View(veh)
Taper directement le nom de la variable dans la console fournit une autre représentation:
> veh
# A tibble: 59 × 27
lib_mrq lib_mod_doss lib_mod
* <fctr> <fctr> <fctr>
1 ALFA-ROMEO AR8C SPIDER 8C SPIDER
2 ASTON MARTIN DB9 DB9
3 AUDI R8 COUPE R8
4 BENTLEY CONTINENTAL GT V8 CONTINENTAL
5 BMW SERIE X X5
6 CADILLAC CTS-V CTS
7 CHEVROLET CAMARO CAMARO
8 CITROEN DS3 DS3
9 FERRARI CALIFORNIA CALIFORNIA
10 FORD S-MAX S-MAX
11 INFINITI Q70 Q70
12 JAGUAR XKR COUPE XK
13 JEEP GRAND CHEROKEE GRAND CHEROKEE
14 KIA CEE'D CEE'D
15 LAMBORGHINI GALLARDO GALLARDO
# ... with 44 more rows, and 24 more variables: dscom <fctr>,
# cnit <fctr>, tvv <fctr>, cod_cbr <fctr>, hybride <fctr>,
# puiss_admin_98 <int>, puiss_max <dbl>, typ_boite <fctr>,
# nb_rapp <int>, conso_urb <dbl>, conso_exurb <dbl>,
# conso_mixte <dbl>, co2 <int>, co_typ_1 <dbl>, hc <dbl>, nox <dbl>,
# hcnox <dbl>, ptcl <dbl>, masse_ordma_min <int>,
# masse_ordma_max <int>, champ_v9 <fctr>, date_maj <date>,
# Carrosserie <fctr>, gamme <fctr>
Avertissement
Si la première ligne n’indique pas que la structure de données est de type tibble, il est probable que le package Tidyverse n’a pas été importé. L’affichage peut différer légèrement
Chaque variable (colonne) possède un type :
<int>pour les entier<fct>pour les facteurs (plus d’informations dans les chapîtres suivants)<dbl>pour les nombres réels (floating point)<date>pour les objetsDateetc.
4.7. Obtenir plus d’informations
L’objet chargé en mémoire est de type tibble. Pour le moment il est suffisant d’assimiler ça à un onglet de tableur. Il s’agit en fait d’un objet de type data.frame que l’on trouve également dans l’univers Python avec le package pandas.
Par commodité, seul le coin supérieur gauche est affiché, mais il existe des possibilités de contrôle de l’affichage
> options(tibble.width = Inf) # Display all columns. NULL : screen width
> options(tibble.print_min = 15) # Display 15 rows
On peut afficher les premières ou les dernières lignes du fichier avec les fonctions head() et tail().
Les 5 premières lignes:
> head(veh,5)
# A tibble: 5 × 27
lib_mrq lib_mod_doss lib_mod
<fctr> <fctr> <fctr>
1 ALFA-ROMEO AR8C SPIDER 8C SPIDER
2 ASTON MARTIN DB9 DB9
3 AUDI R8 COUPE R8
4 BENTLEY CONTINENTAL GT V8 CONTINENTAL
5 BMW SERIE X X5
# ... with 24 more variables: dscom <fctr>, cnit <fctr>, tvv <fctr>,
# cod_cbr <fctr>, hybride <fctr>, puiss_admin_98 <int>,
# puiss_max <dbl>, typ_boite <fctr>, nb_rapp <int>, conso_urb <dbl>,
# conso_exurb <dbl>, conso_mixte <dbl>, co2 <int>, co_typ_1 <dbl>,
# hc <dbl>, nox <dbl>, hcnox <dbl>, ptcl <dbl>, masse_ordma_min <int>,
# masse_ordma_max <int>, champ_v9 <fctr>, date_maj <date>,
# Carrosserie <fctr>, gamme <fctr>
Les 5 dernières:
> tail(veh,5)
# A tibble: 5 × 27
lib_mrq lib_mod_doss lib_mod
<fctr> <fctr> <fctr>
1 VOLKSWAGEN GOLF GOLF
2 VOLKSWAGEN PASSAT PASSAT
3 VOLKSWAGEN SHARAN SHARAN
4 VOLKSWAGEN TIGUAN TIGUAN
5 VOLVO S80 S80
# ... with 24 more variables: dscom <fctr>, cnit <fctr>, tvv <fctr>,
# cod_cbr <fctr>, hybride <fctr>, puiss_admin_98 <int>,
# puiss_max <dbl>, typ_boite <fctr>, nb_rapp <int>, conso_urb <dbl>,
# conso_exurb <dbl>, conso_mixte <dbl>, co2 <int>, co_typ_1 <dbl>,
# hc <dbl>, nox <dbl>, hcnox <dbl>, ptcl <dbl>, masse_ordma_min <int>,
# masse_ordma_max <int>, champ_v9 <fctr>, date_maj <date>,
# Carrosserie <fctr>, gamme <fctr>
Plus intéressant, on peut obtenir une information quantitative sur le tibble avec la fonction summary(). Pour les variables numériques, il s’agit d’une description statistique (min, max, median, quantiles). Pour les facteurs, ils s’agit d’un comptage:
> summary(veh)
lib_mrq lib_mod_doss lib_mod
PEUGEOT :10 FORTWO : 3 FORTWO : 3
RENAULT : 6 107 : 1 107 : 1
VOLKSWAGEN: 6 2008 : 1 2008 : 1
SMART : 3 207 : 1 207 : 1
SEAT : 2 208 : 1 208 : 1
ALFA-ROMEO: 1 3008 : 1 3008 : 1
(Other) :31 (Other):51 (Other):51
dscom cnit
"CTS-V COUPE 6.2L V8 BVA RWD 19""" : 1 M10ALFVP0005293: 1
"PRIUS (136ch) 15""" : 1 M10AUDVP007P917: 1
"S80 D5 Stop&Start et ou 19"" (215ch) BVM6": 1 M10BTLVP000D128: 1
"X5 xDrive50i (Jantes 18"" et 19"")" : 1 M10CDCVP000H156: 1
107 5P 1.0e Blue Lion BVM5 : 1 M10CHEVP001G500: 1
2008 1.6 Vti BVM5 : 1 M10CTRVP011D401: 1
(Other) :53 (Other) :53
tvv cod_cbr hybride puiss_admin_98
001A01 : 1 EH: 1 non:58 Min. : 1.00
0A5FVA/1 : 1 EL: 3 oui: 1 1st Qu.: 7.00
0G-ADAHFA12BA1R5BGDA5: 1 ES:37 Median :11.00
0U5FVA/1 : 1 GO:18 Mean :16.71
1222e : 1 3rd Qu.:30.00
140D2MAA : 1 Max. :50.00
(Other) :53
puiss_max typ_boite nb_rapp conso_urb
Min. : 35.0 A:23 Min. :0.000 Min. : 3.300
1st Qu.: 93.0 D: 1 1st Qu.:6.000 1st Qu.: 6.575
Median :139.5 M:32 Median :6.000 Median : 8.750
Mean :174.8 N: 1 Mean :5.712 Mean :10.895
3rd Qu.:287.8 V: 2 3rd Qu.:6.000 3rd Qu.:14.050
Max. :415.0 Max. :8.000 Max. :24.400
NA's :3
conso_exurb conso_mixte co2 co_typ_1
Min. : 3.300 Min. : 3.300 Min. : 86.0 Min. :0.0270
1st Qu.: 4.575 1st Qu.: 5.375 1st Qu.:125.0 1st Qu.:0.2145
Median : 5.150 Median : 6.400 Median :152.0 Median :0.3030
Mean : 6.198 Mean : 7.929 Mean :189.6 Mean :0.3694
3rd Qu.: 7.475 3rd Qu.:10.025 3rd Qu.:232.2 3rd Qu.:0.5095
Max. :11.600 Max. :16.300 Max. :379.0 Max. :0.8460
NA's :3 NA's :3 NA's :3 NA's :4
hc nox hcnox ptcl
Min. :0.01800 Min. :0.00600 Min. :0.1250 Min. :0.000000
1st Qu.:0.03300 1st Qu.:0.02000 1st Qu.:0.1467 1st Qu.:0.000000
Median :0.04100 Median :0.02900 Median :0.1605 Median :0.001000
Mean :0.04319 Mean :0.06124 Mean :0.1662 Mean :0.001098
3rd Qu.:0.05100 3rd Qu.:0.10750 3rd Qu.:0.1807 3rd Qu.:0.002000
Max. :0.07400 Max. :0.19400 Max. :0.2130 Max. :0.004000
NA's :22 NA's :4 NA's :41 NA's :18
masse_ordma_min masse_ordma_max champ_v9
Min. : 875 Min. : 875 715/2007*195/2013EURO5 :13
1st Qu.:1320 1st Qu.:1320 715/2007*630/2012EURO5 :13
Median :1555 Median :1555 "715/2007*195/2013EURO5: 7
Mean :1607 Mean :1619 715/2007*692/2008EURO5 : 6
3rd Qu.:1852 3rd Qu.:1868 715/2007*566/2011EURO5 : 5
Max. :2745 Max. :2745 (Other) :12
NA's : 3
date_maj Carrosserie gamme
Min. :2013-03-01 BERLINE :23 ECONOMIQUE: 5
1st Qu.:2014-03-01 BREAK : 3 INFERIEURE: 7
Median :2014-03-01 CABRIOLET : 9 LUXE :18
Mean :2014-01-31 COUPE : 9 MOY-INFER :11
3rd Qu.:2014-03-01 MONOSPACE : 3 MOY-SUPER :10
Max. :2014-03-01 MONOSPACE COMPACT : 1 SUPERIEURE: 8
NA's :17 TS TERRAINS/CHEMINS:11
Exercice
A l’aide du résultat de la fonction summary(), identifier les différents types de variables du jeu de données. Combien y en a t-il ? Pour les variables numériques, toutes les données statistiques ont elle un sens ? Y a t-il des variables numériques qui auraient pu être considérées comme des facteurs ? Vice versa ?
La fonction str() donne le type et la liste des premières valeurs de chacune des variables
> str(veh)
Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 59 obs. of 27 variables:
$ lib_mrq : Factor w/ 37 levels "ALFA-ROMEO","ASTON MARTIN",..: 1 2 3 4 5 6 7 8 9 10 ...
$ lib_mod_doss : Factor w/ 57 levels "107","2008","207",..: 10 22 46 20 52 21 13 24 12 50 ...
$ lib_mod : Factor w/ 57 levels "107","2008","207",..: 11 22 45 20 55 21 14 24 13 49 ...
$ dscom : Factor w/ 59 levels "\"CTS-V COUPE 6.2L V8 BVA RWD 19\"\"\"",..: 13 22 46 21 4 1 15 24 14 50 ...
$ cnit : Factor w/ 59 levels "M10ALFVP0005293",..: 1 40 2 3 54 4 5 6 7 8 ...
$ tvv : Factor w/ 59 levels "001A01","0A5FVA/1",..: 25 52 13 12 56 37 38 49 35 53 ...
$ cod_cbr : Factor w/ 4 levels "EH","EL","ES",..: 3 3 3 3 3 3 3 3 3 3 ...
$ hybride : Factor w/ 2 levels "non","oui": 1 1 1 1 1 1 1 1 1 1 ...
$ puiss_admin_98 : int 38 44 45 41 35 50 35 12 40 12 ...
$ puiss_max : num 331 381 386 373 330 415 318 152 360 146 ...
$ typ_boite : Factor w/ 5 levels "A","D","M","N",..: 3 1 3 1 1 1 3 3 2 1 ...
$ nb_rapp : int 6 6 6 8 8 6 6 6 7 6 ...
$ conso_urb : num 24.4 21.6 22.2 15.4 14 ...
$ conso_exurb : num 11.6 10 10.6 7.7 8.3 ...
$ conso_mixte : num 16.3 14.3 14.9 10.6 10.4 ...
$ co2 : int 379 333 346 246 242 336 329 149 299 189 ...
$ co_typ_1 : num 0.501 0.187 0.547 0.55 0.36 ...
$ hc : num 0.038 0.041 0.074 0.048 0.04 ...
$ nox : num 0.027 0.029 0.035 0.042 0.022 ...
$ hcnox : num NA NA NA NA NA NA NA NA NA NA ...
$ ptcl : num NA NA 0.003 0.002 0.001 NA NA 0.001 NA 0.003 ...
$ masse_ordma_min: int 1750 1860 1695 2370 2250 1986 1965 1231 1875 1676 ...
$ masse_ordma_max: int 1750 1860 1695 2370 2250 2028 1974 1231 1875 1676 ...
$ champ_v9 : Factor w/ 12 levels "\"715/2007*195/2013EURO5",..: 12 11 5 7 2 10 10 1 12 5 ...
$ date_maj : Date, format: "2014-03-01" "2013-03-01" NA "2014-03-01" ...
$ Carrosserie : Factor w/ 7 levels "BERLINE","BREAK",..: 3 4 4 1 7 4 3 1 3 5 ...
$ gamme : Factor w/ 6 levels "ECONOMIQUE","INFERIEURE",..: 3 3 3 3 3 6 3 2 3 6 ...
Exercice
Quelle fonction R Core donne l’information présentée sur la première ligne de résultat de la fonction str() ?
Les dimensions du tibble sont données par les fonctions précédentes mais on peut y avoir accès programmatiquement avec les fonctions dim(), nrow() et ncol()
> dim(veh)
[1] 59 27
> nrow(veh)
[1] 59
> ncol(veh)
[1] 27
On obtient une liste des variables contenues dans le tibble avec la fonction names()
> names(veh)
[1] "lib_mrq" "lib_mod_doss" "lib_mod"
[4] "dscom" "cnit" "tvv"
[7] "cod_cbr" "hybride" "puiss_admin_98"
[10] "puiss_max" "typ_boite" "nb_rapp"
[13] "conso_urb" "conso_exurb" "conso_mixte"
[16] "co2" "co_typ_1" "hc"
[19] "nox" "hcnox" "ptcl"
[22] "masse_ordma_min" "masse_ordma_max" "champ_v9"
[25] "date_maj" "Carrosserie" "gamme"
4.8. Visualisation
Afficher les valeurs numériques contenues dans un jeu de données est une première prise de contact sommaire car il est nécessaire de faire une opération de réduction de données (statistiques de premier ordre) pour rendre l’information accessible sur le plan cognitif.
Cette opération de réduction de données masque parfois de grandes disparités, comme le montre le quartet d’Anscombe.
Il est donc indispensable d’avoir une représentation graphique des données, qui véhicule une quantité d’informations beaucoup plus importante.
Le langage R core dispose de packages graphiques « historiques » : base et lattice:
le premier permet la construction de graphiques par un appel successif à des fonctions modificatrices du graphique de base
le second construit le graphique en un seul appel, avec passage de paramètres, et a été conçu pour étendre les possibilités du premier.
Mais ces deux packages sont anciens, pas compatibles et la syntaxe est parfois un peu complexe.
La solution moderne et performante de création de graphiques dans R réside dans le package ggplot2 qui se base sur le principe d’une grammaire initialement proposée par Leland Wilkinson et dont l’application à R est décrite dans cet article.
ggplot2 combine les concepts des deux packages historiques et fournit une méthode structurée et performante de construction des graphiques en identifiant plusieurs couches indépendantes (avec cependant un concept d’héritage entre elles).
ggplot2 est donc la référence et le standard graphique de R. Son approche est relativement simple mais la création de graphiques complexes demande cependant une maitrise plus avancée.
4.8.1. Un premier graphique
Comme indiqué dans l’introduction de ce paragraphe, ggplot2 utilise le concept de layer pour construire un graphique. Il y a 7 types de layers disponibles pour un contrôle total de la représentation graphique, mais seulement 3 sont réellement indispensables pour un affichage basique :
data: le jeu de donnéesaesthetics: la sélection des variables à représenter graphiquement ainsi que le type de graphique sur lequel on souhaite les représentergeometry: comment ces données seront représentées sur le graphique.
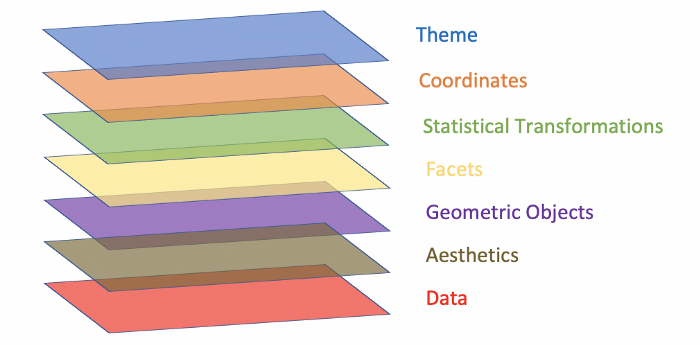
Les layers de ggplot2 sont présentés dans le document Build a plot layer by layer
Avant utilisation, le package ggplot2 doit être installé puis importé:
> install.packages("ggplot2")
> library(ggplot2)
Important
le package ggplot2 fait partie de l’éco système Tidyverse. Si celui ci a déjà été installé, l’installation individuelle de ggplot2 est inutile.
On obtient la liste des packages installés avec
> installed.packages()
Comme la liste peut être longue
> "ggplot2" %in% rownames(installed.packages())
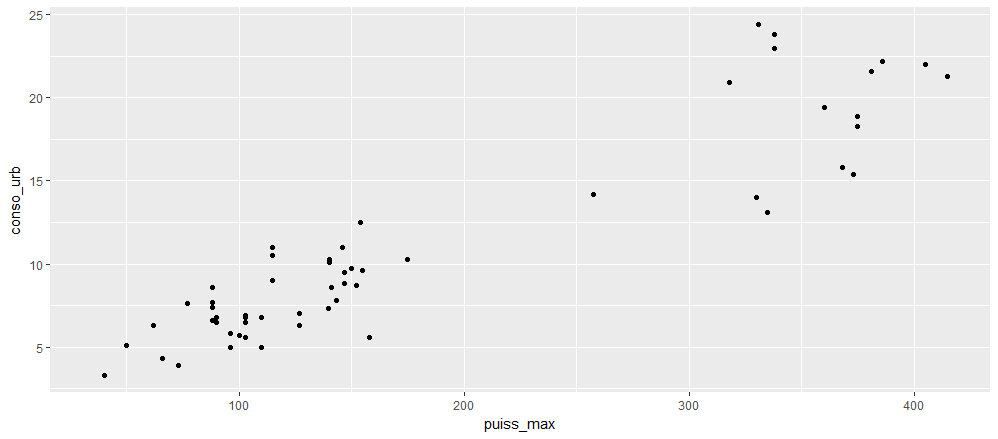
On peut tracer la consomation de carburant en fonction de la puissance du moteur de façon assez simple:
> ggplot(veh) +
+ aes(x=puiss_max, y=conso_urb) +
+ geom_point()
Warning message:
Removed 3 rows containing missing values (geom_point).
Le graphique obtenu devrait être proche de celui ci dessous.
Exercice
Pour bien décomposer le processus, chaque ligne adresse ici un des 3 layers requis. Identifier le layer mis en jeu par chacune des lignes et l’opération qu’elle réalise.
Il existe des façons plus compactes de construire les graphiques en utilisant des fonctions agissant sur plusieurs layers. Dans ce qui suit, on construit l’objet graphique et on définit son esthétique en une seule opération:
> ggplot(veh, aes(x=puiss_max, y=conso_urb)) +
+ geom_point()
Warning message:
Removed 3 rows containing missing values (geom_point).
L’utilisation de plusieurs lignes est plus explicite lorsqu’on débute mais n’est pas strictement requise et la forme compacte ci dessous est tout à fait valide:
> ggplot(veh, aes(x=puiss_max, y=conso_urb)) + geom_point()
Warning message:
Removed 3 rows containing missing values (geom_point).
Dans ce cas, la fonction ggplot() donne les informations relatives aux deux premiers layers. veh est la data.frame et aes() précise que ce sera un graphique cartésien avec la puissance du moteur sur l’axe des abscisses et la consommation de carburant sur l’axe des ordonnées. geom_point() permet de construire un scatter plot.
Exercice
Que se passe t-il lorsqu’on modifie le layer 3 en utilisant la fonction geom_line() ?
Question
La construction du scatter plot s’accompagne d’un warning « Removed 3 rows containing missing values (geom_point) ». On remarque au passage que ggplot2 gère la situation et construit le graphique tout de même.
Utiliser la fonction
View()et essayer de comprendre la cause de l’apparition du warningLa suppression de 3 observations est elle légitime ?
Que pensez vous de l’alerte déclenchée par
ggplot2?
Le graphique obtenu est un graphique minimal, mettant en jeu les seuls layers obligatoires. Plusieurs paramètres par défaut ont été utilisés. Par exemple le choix d’une représentation cartésienne a été déduite des paramètres de la fonction aes().
Le concept de layers permet d’ajouter relativement aisément des informations additionnelles. C’est le cas avec les fonctions ggtitle() et labs()
> ggplot(veh, aes(x=puiss_max, y=conso_urb)) +
+ geom_point() +
+ ggtitle("Urban fuel consumption vs engine power") +
+ labs(x="Engine Power (kW)", y="Fuel consumption (l)")
Warning message:
Removed 3 rows containing missing values (geom_point).
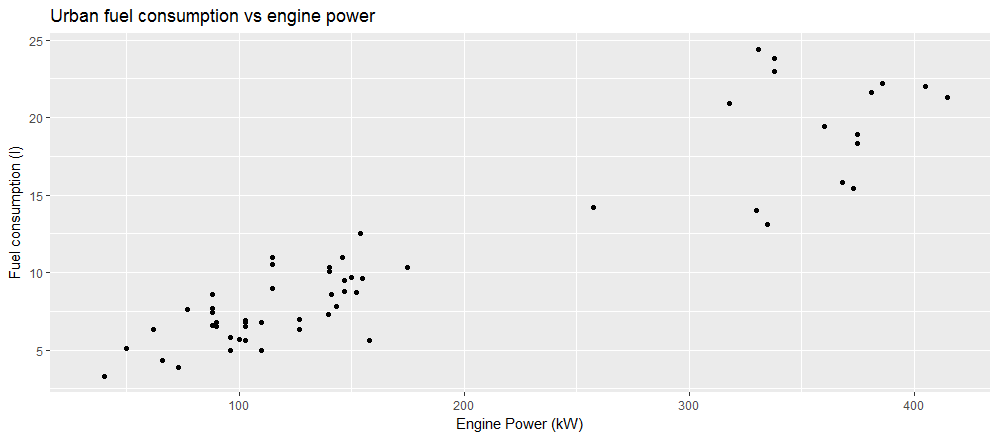
Question
Un graphique permet d’extraire de l’information que le simple examen des données alphanumériques ne permet pas. Quelle conclusion tirez vous des données affichées ?
4.8.2. Ajouter des informations
Le graphique précédent utilisait les données de l’ensemble des véhicules (à l’exception des véhicules électriques pour lesquels la consommation se mesure différemment) sans aucun moyen de distinguer des sous catégories. Pour rendre les choses plus explicites, on peut coder celles ci à l’aide d’informations additionnelles : couleur, taille, forme du symbole… La fonction aes() permet cette distinction.
Affecter une couleur différente à chaque gamme de voiture se fait de façon intuituive en associant la variable gamme à l’attribut color:
> ggplot(veh, aes(x=puiss_max, y=conso_urb, color = gamme)) +
+ geom_point() +
+ ggtitle("Urban fuel consumption vs engine power") +
+ labs(x="Engine Power (kW)", y="Fuel consumption (l)")
Warning message:
Removed 3 rows containing missing values (geom_point).
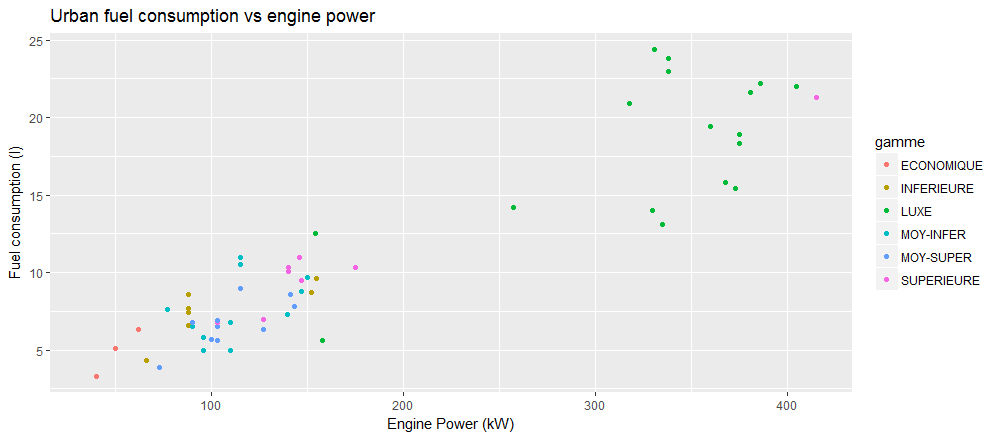
Pour obtenir se résultat, ggplot2 effectue silencieusement un travail de catégorisation des données, de choix d’une échelle de couleur, d’affichage de la légende correspondante, etc…
Question
Quelle est l’information apportée par le groupement des données par gamme de véhicule ?
On peut également grouper les données par type de carburant en utilisant la forme des symboles:
> ggplot(veh, aes(x=puiss_max, y=conso_urb, color=gamme, shape=cod_cbr)) +
+ geom_point() +
+ ggtitle("Urban fuel consumption vs engine power") +
+ labs(x="Engine Power (kW)", y="Fuel consumption (l)")
Warning message:
Removed 3 rows containing missing values (geom_point).
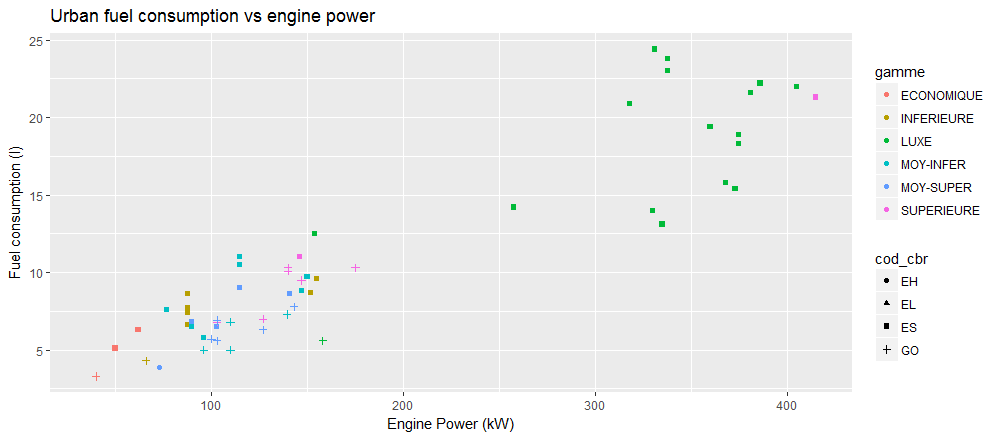
Question
Peut on tirer une conclusion sur la relation entre la puissance et le type de carburant (ES=essence, GO=diesel) ? Quid de la relation entre consommation de carburant et type de carburant pour des véhicules de puissance comparable ?
Une dernière propriété est disponible pour coder une autre variable sur le graphique : la taille du symbole. On peut par exemple l’affecter à l’émission de CO2:
> ggplot(veh, aes(x=puiss_max, y=conso_urb, color=gamme, shape=cod_cbr, size=co2)) +
+ geom_point() +
+ ggtitle("Urban fuel consumption vs engine power") +
+ labs(x="Engine Power (kW)", y="Fuel consumption (l)")
Warning messages:
1: Using size for a discrete variable is not advised.
2: Removed 3 rows containing missing values (geom_point).
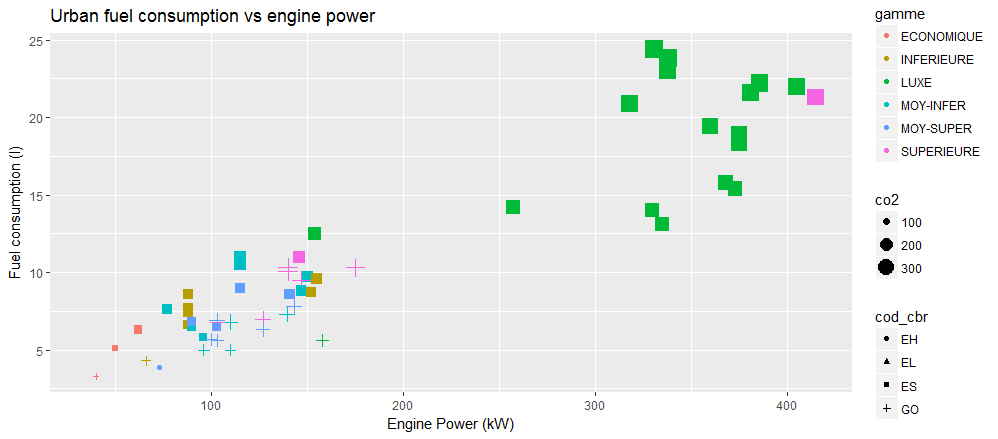
Question
Que pensez vous du premier warning émis par ggplot2 ? Quelle conclusion tirer de l’information révélée par cette nouvelle variable ?
4.9. D’autres graphiques
ggplot2 peut tracer un très grand nombre de graphiques, bien au delà du simple scatter plot utilisé jusqu’ici. On jettera un oeil attentif à la galerie pour avoir un aperçu de toutes les possibilités. Nous allons en présenter ici quelques uns.
4.9.1. Histogrammes
Les histogrammes sont des graphiques intéressants dans le sens où ils présentent des informations qui ne sont pas explicitement contenues dans le jeu de données. Une opération de catégorisation et de comptage est effectuée au préalable par ggplot2. Observons les instructions suivantes:
ggplot(veh, aes(x=puiss_max)) +
+ geom_histogram(bins=10, colour="black", fill="#e5f5f9") +
+ ggtitle("Engine power") +
+ xlab("Power (kW)") +
+ ylab("count")
Ici la fonction aes() utilise une seule variable, en l’occurence la puissance maximum du véhicule puiss_max. La seconde utilisée lors de l’affichage (le comptage) n’est pas présente directement dans le jeu de données et est produite par le layer « statistical » et associée automatiquement à l’axe des ordonnées.
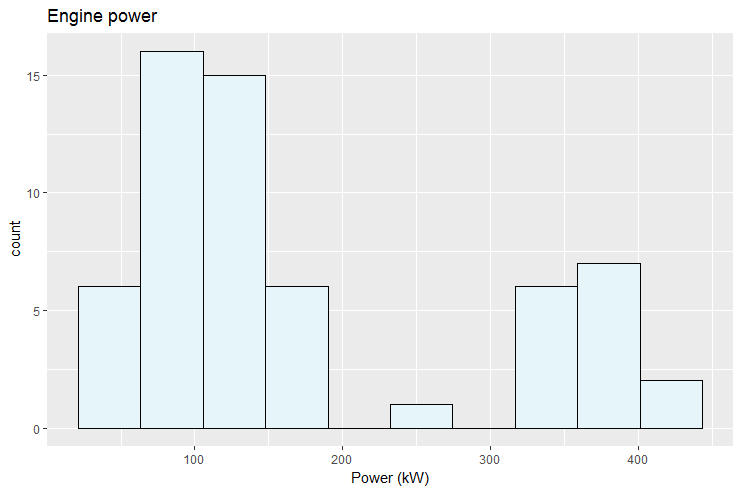
On remarque que les valeurs par défaut utilisées par ggplot2 pour les paramètres colour and fill sont modifiées dans la fonction geom_histogram(). On utilise également deux nouvelles fonctions, xlab() et ylab(), pour communiquer l’information sur les labels de façon distincte. ggplot2 fonctionne en mode TIMTOWTDI (There Is More Than One Way To Do It).
Question
Quelle information supplémentaire est apportée par cette nouvelle représentation graphique ?
4.9.2. Modélisation
Bien que l’on acquiert une connaissance importante de la relation entre deux variables en observant un graphique, il est parfois intéressant et/ou nécessaire de quantifier cette relation en donnant les paramètres de la fonction qui « fitte » les données.
Pour l’exemple précédent (la relation entre la consommation de carburant et la puissance du véhicule), il semble qu’il y ait une relation quasi linéaire entre les deux mais on ignore quelle est la pente de cette droite de régression.
ggplot2 possède la fonction geom_smooth()
> ggplot(veh, aes(x=puiss_max, y=conso_urb)) +
+ geom_point() +
+ geom_smooth() +
+ ggtitle("Urban fuel consumption vs engine power") +
+ xlab("Power (kW)") +
+ ylab("Fuel consumption (l/100 km)") +
+ theme(plot.title = element_text(hjust = 0.5))
`geom_smooth()` using method = 'loess'
Warning messages:
1: Removed 3 rows containing non-finite values (stat_smooth).
2: Removed 3 rows containing missing values (geom_point).
ggplot2 alerte sur la méthode mathématique utilisée pour le fitting par la fonction geom_smooth(). La méthode Loess est utilisée par défaut. Pour plus d’information, consulter la page d’aide.
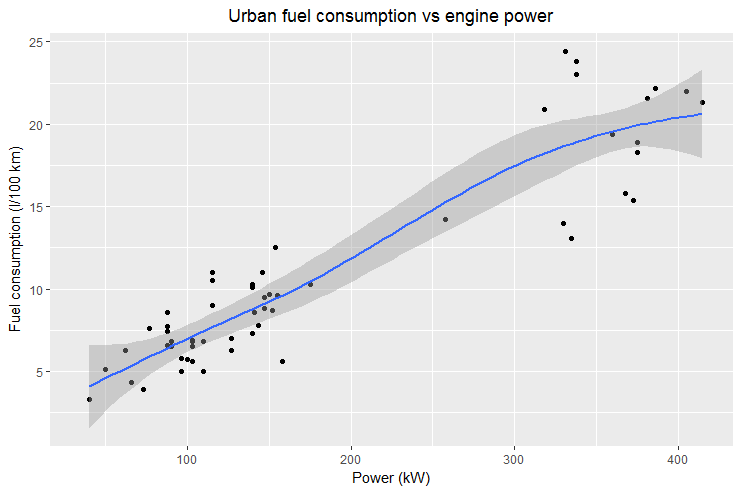
Ce graphique est un autre exemple d’affichage de données ne faisant pas explicitement partie du jeu de données initial. Les données de base sont utilisées par ggplot2 pour en générer d’autres utilisées pour l’affichage. Les instructions utilisées pour construire le graphique mettent en évidence le concept de layers utilisé par ggplot2. geom_point() et geom_smooth() adressent chacune un layer différent qui sont superposés au moment du rendu graphique. Cette décomposition en layers donne une grande souplesse et permet de construire des graphiques complexes. La fonction theme() adresse le dernier layer et est utilisée ici pour centrer le titre. Plus généralement, elle permet l’interaction avec les éléments externes à la zone de données du graphique (taille du texte, couleur, justification, etc…).
4.10. Facetting
Le facetting est la possibilité pour ggplot2 de construire un ensemble de sous graphiques, issu d’une catégorisation basée sur une variable du jeu de données, présentés selon une organisation matricielle.
Par exemple, on peut explorer la relation entre la puissance maximale et la consommation de carburant pour chaque type de carburant avec la fonction facet_wrap()
> ggplot(data = veh) +
+ geom_point(mapping = aes(x = puiss_max, y = conso_urb)) +
+ facet_wrap(~ cod_cbr, nrow = 2)
Ainsi la consommation de carburant est affichée pour les 4 catégories d’énergie identifiées par la variable cod_cbr : EH (hybride), EL (électrique), ES (essence) et GO (diesel).
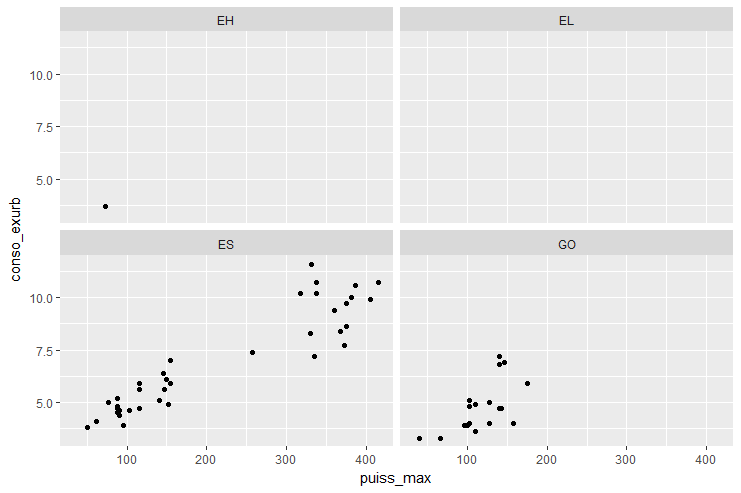
Cette première approche est un naïve car elle inclut toutes les valeurs que peut prendre la variable cod_cbr. Il est parfois judicieux de ne produire l’affichage que pour un sous ensemble des valeurs possibles d’une variable.
Ici, il n’est pas très pertinent d’inclure les véhicules dont le carburant est de type EH et EL. Trop peu de données pour le premier, et pas de pertinence pour le second.
Il est donc nécessaire de filtrer le jeu de données initial pour ne présenter à l’affichage que les données qui nous intéressent. Ce genre d’opération est réalisé avec le package dplyr que l’on étudiera plus en détail plus tard dans ce cours. Si l’éco système Tidyverse a correctement été installé, il est juste nécessaire de l’importer avant utilisation
> library(dplyr)
Attachement du package : ‘dplyr’
The following objects are masked from ‘package:stats’:
filter, lag
The following objects are masked from ‘package:base’:
intersect, setdiff, setequal, union
Un warning alerte sur les fonctions R core masquées par cette importation.
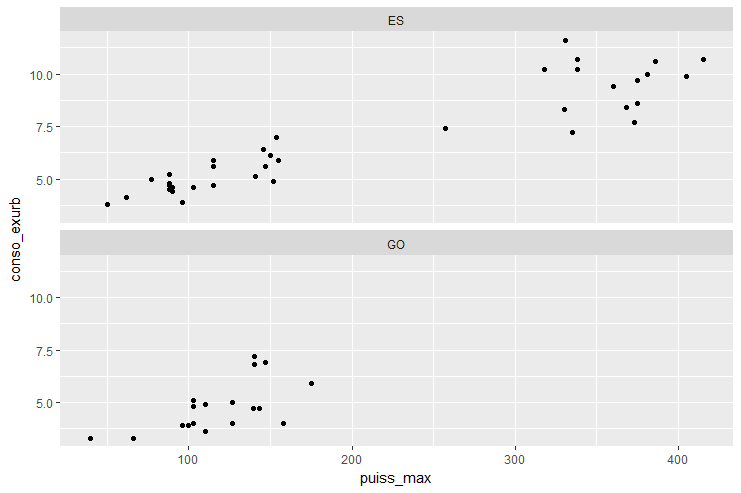
La construction du graphique est similaire. La seule modification concerne les données présentées au layer 1. Sans rentrer dans les détails de syntaxe abordés plus loin dans ce cours, on passe à ggplot() un ensemble réduit de données, construit par filtrage du jeu de données initial. Le filtrage est effectué par filter() à qui on passe un prédicat en argument. En langage (presque) naturel, le jeu de données initial est filtré avec les véhicules dont le carburant est de type ES OU de type GO:
> ggplot(data = veh %>% filter(cod_cbr=="ES" | cod_cbr=="GO")) +
+ geom_point(mapping = aes(x = puiss_max, y = conso_exurb)) +
+ facet_wrap(~ cod_cbr, nrow = 2)
Le graphique produit est similaire à celui ci dessous.
On travaillera de façon plus approfondie sur la manipulation de données dans les chapitres Data frames et Transformation de données.