Catalogue des premiers CNN
Pourquoi ces architectures comptent encore en 2025
Même si les modèles récents — Vision Transformers, ConvNeXt ou EfficientNetV2 — dominent aujourd’hui les benchmarks, les réseaux convolutifs historiques restent essentiels pour comprendre l’évolution du domaine.
Ces architectures constituent les briques fondatrices de la vision par ordinateur moderne : convolutions, pooling, profondeur des réseaux, explosion du nombre de paramètres, stratégies de régularisation… Autant de notions qui se sont construites progressivement à travers les modèles présentés ci-dessous.
Entre 2010 et 2017, une véritable course à la précision s’est engagée autour de grandes bases de données, notamment ImageNet. Chaque amélioration, parfois minime, représentait un gain critique lorsqu’un système devait fonctionner des milliers d’heures ou être déployé dans des millions d’appareils. Aujourd’hui, l’intérêt principal de ces modèles est pédagogique : ils éclairent les principes qui ont permis l’émergence des architectures modernes.
LeNet
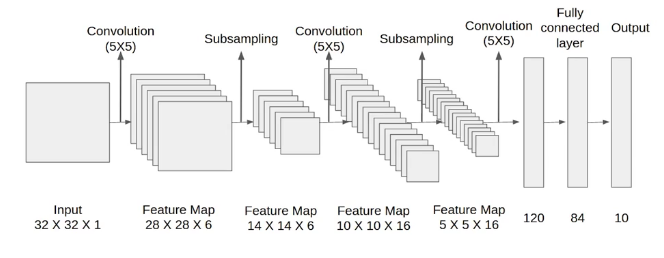
LeNet est l’un des premiers réseaux convolutifs opérationnels. Conçu en 1989 par Yann LeCun et ses collègues dans les laboratoires AT&T Bell, il a été appliqué avec succès à la reconnaissance de chiffres manuscrits, notamment pour le tri automatique du courrier postal américain.
Dans les années 1990, les limites matérielles empêchaient l’usage massif de
réseaux profonds. Les CNN étaient alors concurrencés par des méthodes moins
coûteuses comme les SVM. Malgré leur simplicité, les briques fondamentales de
LeNet — couches Conv, Pool et Linear — constituent encore la base
conceptuelle des architectures modernes.
LeNet contient environ 40 000 paramètres.
Couche |
Shape |
Nb paramètres |
|---|---|---|
conv2d_4 (Conv2D) |
(24, 24, 6) |
156 |
max_pooling2d_4 (MaxPooling2D) |
(12, 12, 6) |
|
conv2d_5 (Conv2D) |
(8, 8, 16) |
2 416 |
max_pooling2d_5 (MaxPooling2D) |
(4, 4, 16) |
|
flatten_2 (Flatten) |
||
dense_6 (Dense) |
30 840 |
|
dense_7 (Dense) |
10 164 |
|
dense_8 (Dense) |
850 |
|
TOTAL |
44 426 |
ImageNet
ImageNet est une base de données contenant plus de 14 millions d’images organisées en 22 000 catégories. Elle a joué un rôle majeur dans l’essor du deep learning, notamment à travers le concours ImageNet Large Scale Visual Recognition Challenge (ILSVRC), organisé de 2010 à 2017.
Ce concours visait à comparer objectivement les nouvelles architectures de réseaux. Au début, la métrique utilisée était la Top-5 accuracy ; aujourd’hui, la Top-1 accuracy est privilégiée.
AlexNet
En 2012, Alex Krizhevsky et ses collègues de l’Université de Toronto remportent l’ILSVRC avec AlexNet, réduisant l’erreur de plus de 10 points par rapport aux autres concurrents. Cette percée est due à plusieurs éléments :
un réseau plus profond,
l’utilisation des GPU pour l’apprentissage,
l’introduction de la fonction d’activation
ReLU.
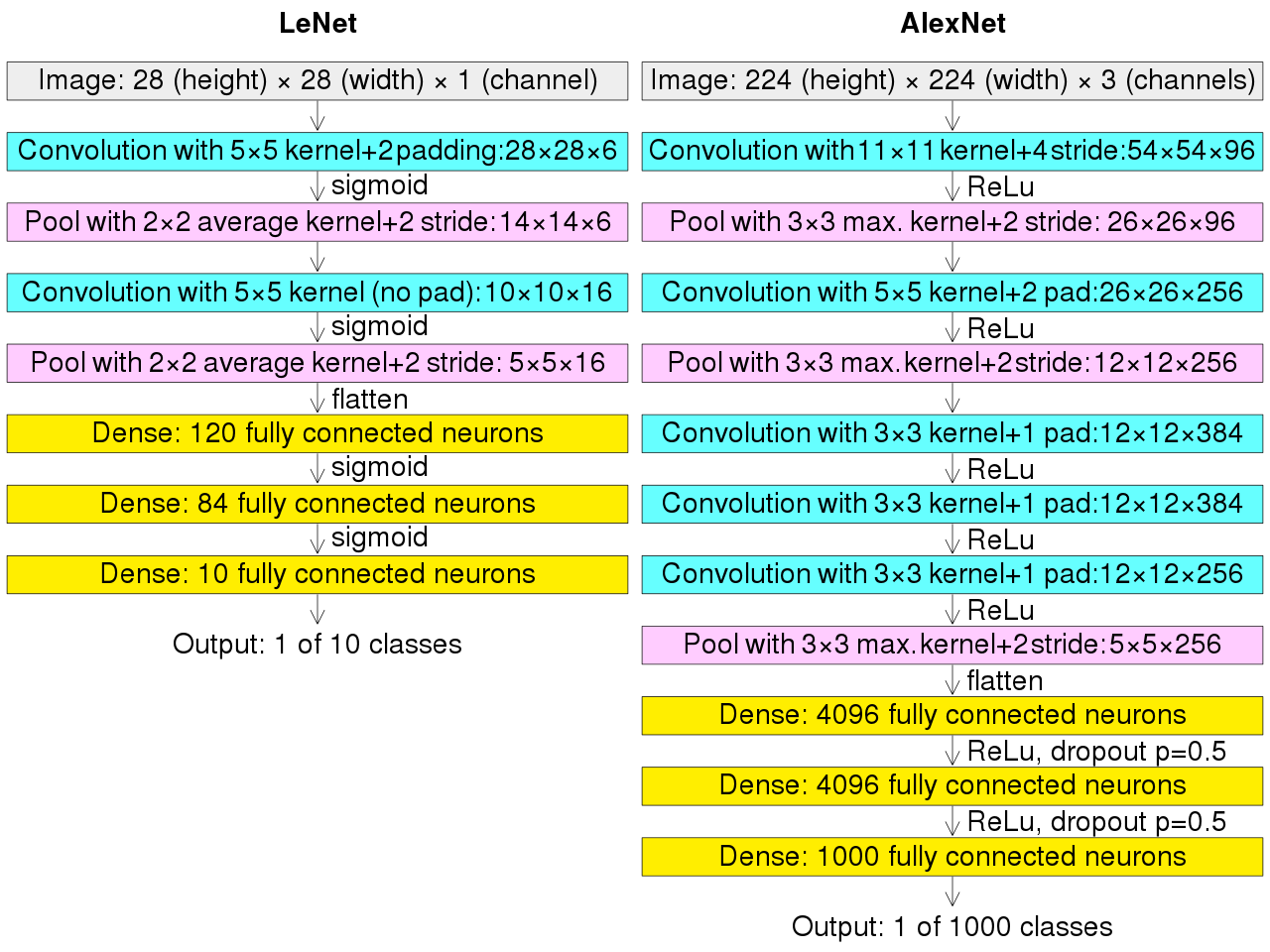
Comparé à LeNet, AlexNet traite des images beaucoup plus grandes (224×224 RGB) et comporte 60 millions de paramètres. Il empile des couches convolutives (kernels 11×11, 5×5, 3×3) séparées par du pooling, suivies de trois couches entièrement connectées.
Couche |
Shape |
Nb paramètres |
|---|---|---|
input_shape |
(227, 227, 3) |
|
conv2d 11x11 96 filters |
(55, 55, 96) |
34 944 |
max_pooling2d 3x3 |
(27, 27, 96) |
|
conv2d 5x5 |
(27, 27, 256) |
614 656 |
max_pooling2d 3x3 |
(13, 13, 256) |
|
conv2d 3x3 |
(13, 13, 384) |
885 120 |
conv2d 3x3 |
(13, 13, 384) |
1 327 488 |
conv2d 3x3 |
(13, 13, 256) |
884 992 |
max_pooling2d 3x3 |
(6, 6, 256) |
|
flatten |
||
dense |
37 752 832 |
|
dense |
16 781 312 |
|
dense |
4 097 000 |
|
TOTAL |
62 383 848 |
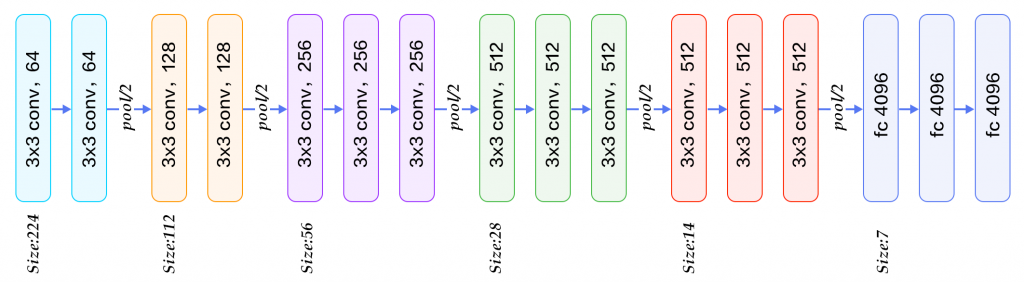
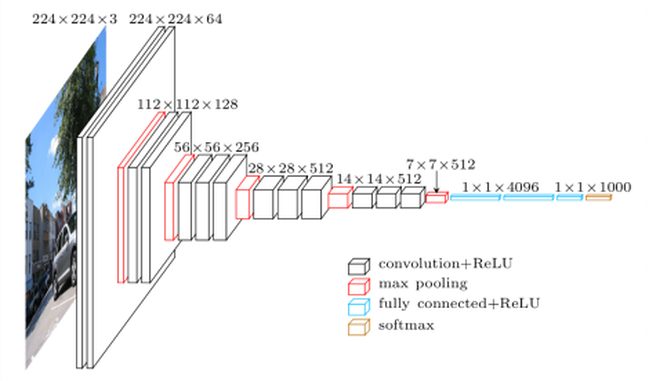
VGG16
Présenté en 2014 par l’équipe Visual Geometry Group (Université d’Oxford), VGG16 se distingue par sa simplicité : empilement systématique de convolutions 3×3 suivies de pooling. Cette architecture atteint 92,7% de précision (Top-5) sur ImageNet. L’entraînement a nécessité plusieurs semaines sur des cartes NVIDIA Titan.
VGG16 comporte 140 millions de paramètres.
Couche |
Shape |
Nb paramètres |
|---|---|---|
InputLayer |
(224, 224, 3) |
|
Conv2D 3x3 |
(224, 224, 64) |
1 792 |
Conv2D 3x3 |
(224, 224, 64) |
36 928 |
MaxPooling 2x2 |
(112, 112, 64) |
|
Conv2D 3x3 |
(112, 112, 128) |
73 856 |
Conv2D 3x3 |
(112, 112, 128) |
147 584 |
MaxPooling 2x2 |
(56, 56, 128) |
|
Conv2D 3x3 |
(56, 56, 256) |
295 168 |
Conv2D 3x3 |
(56, 56, 256) |
590 080 |
Conv2D 3x3 |
(56, 56, 256) |
590 080 |
MaxPooling 2x2 |
(28, 28, 256) |
|
Conv2D 3x3 |
(28, 28, 512) |
1 180 160 |
Conv2D 3x3 |
(28, 28, 512) |
2 359 808 |
Conv2D 3x3 |
(28, 28, 512) |
2 359 808 |
MaxPooling 2x2 |
(14, 14, 512) |
|
Conv2D 3x3 |
(14, 14, 512) |
2 359 808 |
Conv2D 3x3 |
(14, 14, 512) |
2 359 808 |
Conv2D 3x3 |
(14, 14, 512) |
2 359 808 |
MaxPooling 2x2 |
(7, 7, 512) |
|
Flatten |
||
Dense |
102 764 544 |
|
Dense |
16 781 312 |
|
Dense |
4 097 000 |
|
TOTAL |
138 357 544 |
GoogLeNet et les modules Inception
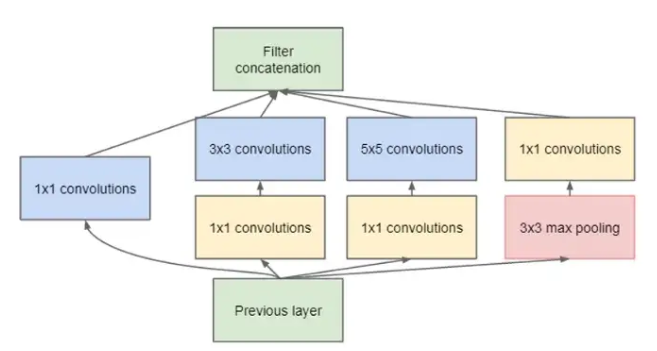
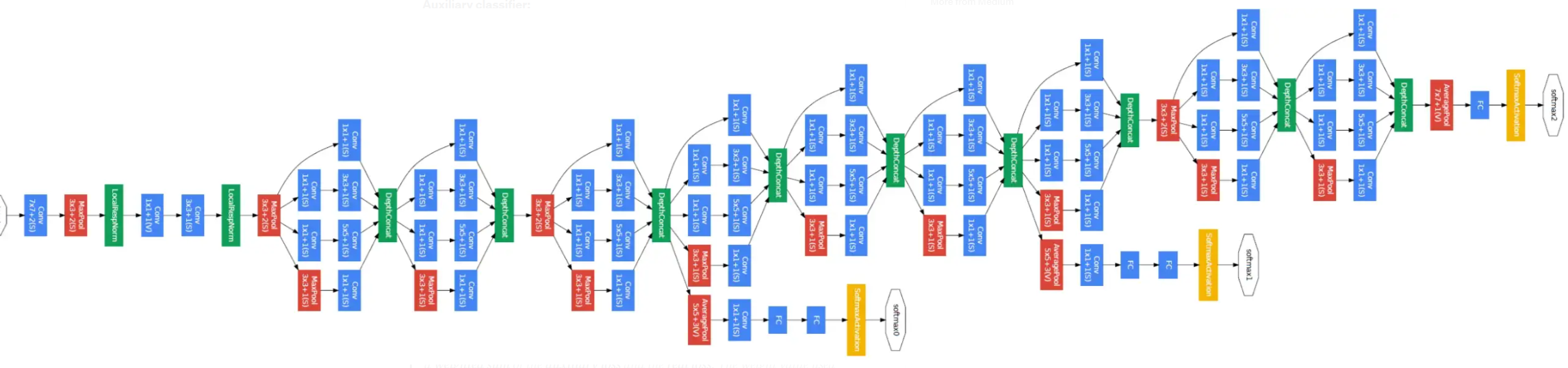
Toujours en 2014, les chercheurs de Google proposent GoogLeNet, qui introduit le module Inception. Ce dernier combine plusieurs opérations en parallèle (convolutions 1×1, 3×3, 5×5, pooling) puis concatène les résultats.
Pour limiter le nombre de paramètres, des convolutions 1×1 sont utilisées comme réduction dimensionnelle. GoogLeNet empile 9 modules Inception et totalise seulement 7 millions de paramètres, une réduction spectaculaire comparée aux 140 millions de VGG16.
La version Inception v3 (2017) en comporte environ 26 millions.
ResNet
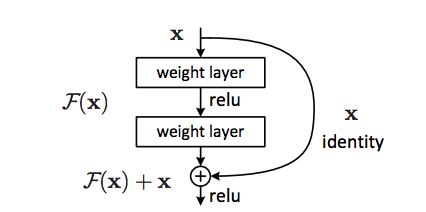
En 2015, Kaiming He et al. (Microsoft Research) présentent les réseaux résiduels ou ResNet, qui résolvent deux limitations majeures des réseaux profonds :
le vanishing gradient,
la saturation de précision : ajouter des couches dégrade parfois les performances.
Les skip connections permettent à l’information de contourner certaines couches, rendant possible l’entraînement de réseaux extrêmement profonds. Cette idée a révolutionné le domaine.
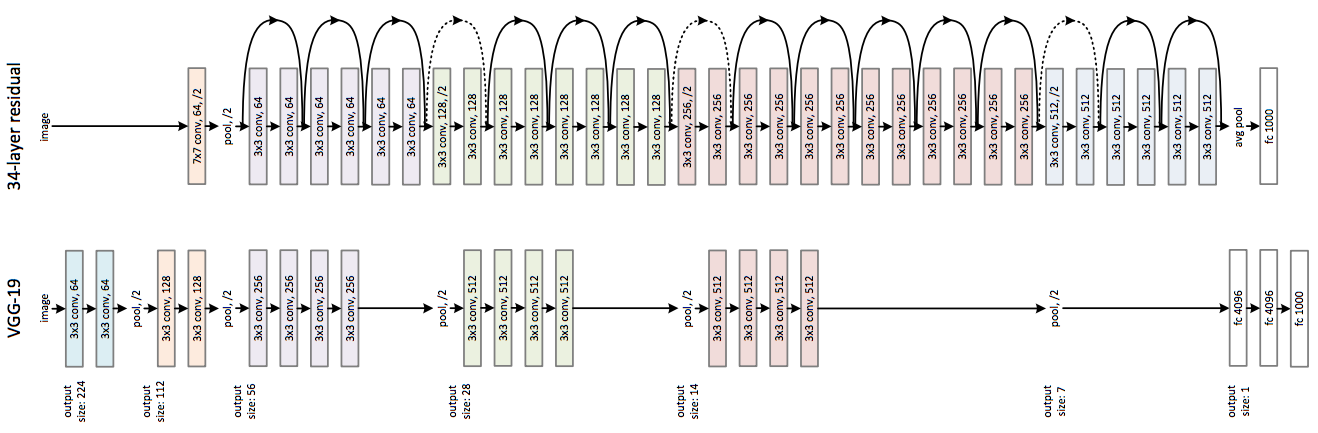
Grâce à cette approche, les architectures dépassent rapidement la centaine de couches. Par exemple, ResNet50 contient 25 millions de paramètres, bien moins que les 140 millions de VGG16.
Et après ?
Après ResNet, l’amélioration des CNN s’est poursuivie sans chercher uniquement à augmenter la profondeur. Plusieurs tendances structurantes se sont dégagées.
ResNeXt et WideResNet ont montré que la capacité d’un réseau peut être accrue en jouant sur d’autres dimensions comme la largeur des blocs, ce qui améliore les performances tout en restant simple à entraîner.
Les réseaux légers tels que MobileNet et ShuffleNet ont répondu au besoin de déployer des modèles sur des appareils à faible puissance. Leurs stratégies réduisent drastiquement le coût de calcul tout en conservant une précision acceptable.
Avec EfficientNet, l’accent a été mis sur un redimensionnement cohérent des architectures : profondeur, largeur et résolution évoluent ensemble selon une règle simple (compound scaling), permettant d’obtenir un excellent rapport précision / coût.
Révolutions au-delà des CNN
Après les premiers CNN, plusieurs avancées majeures ont transformé la vision artificielle :
U-Net a introduit une architecture capable de produire des prédictions pour chaque pixel, ouvrant la voie à la segmentation moderne.
Le mécanisme d’attention a permis d’analyser une image de manière globale plutôt que locale.
Cette idée a mené aux Transformers en vision, capables d’obtenir d’excellentes performances sans convolutions.
Les modèles génératifs ont appris à créer des images nouvelles et réalistes.
Les modèles multimodaux combinent désormais texte et image dans une même architecture.
L’apprentissage auto-supervisé permet d’exploiter des données non annotées pour préentraîner des modèles efficaces.
Ces innovations constituent les principales révolutions ayant suivi les CNN traditionnels.