Les principes de conception
Lorsque vous effectuez des exercices de programmation, des travaux pratiques ou des tutoriels, le travail à accomplir reste relativement cadré. Par exemple, lorsque l’on vous demande de coder une fonction, on vous décrit précisément ses paramètres et le traitement à effectuer.
En revanche, en codant par vous-même un projet de plusieurs centaines de lignes, plus le projet avance, plus vous rencontrez des problèmes :
Relire le code s’avère ardu car plutôt que de structurer en fonctions, on a préféré faire des copier-collers.
Les fonctions sont relativement longues, 80 à 150 lignes, si bien que l’on a du mal à identifier leur rôle exact.
Les fonctions étant mal conçues, il devient difficile de les réutiliser.
Ainsi, lorsque l’on a besoin d’une fonction déjà codée, on préfère recoder ou copier-coller et adapter.
En conséquence, on trouve souvent plusieurs fonctions qui effectuent un traitement similaire.
Au final, sur 1000 lignes de code, au moins les 2/3 proviennent de copier-collers.
Dans ce contexte, l’ajout de fonctionnalités devient difficile.
Pour couronner le tout, des erreurs étranges commencent à apparaître : le programme ne plante pas, mais il ne se comporte pas comme prévu.
Pourquoi une personne capable de mettre en place 20 fonctions de 10 lignes chacune, se retrouve en difficulté sur un projet de 200 lignes ? Il y a en effet, une différence cruciale entre savoir faire des exercices courts et mener à bien un projet long : il s’agit de la capacité à concevoir un programme, à l’organiser et à le structurer.
Les trois grands principes de conception
Pour concevoir un projet informatique long, tout programmeur est amené à respecter les trois principes suivants :
Identifier les données et les actions/traitements
Structurer les données et les actions/traitements
Améliorer ses choix de conception
Ces trois grands principes ne s’articulent pas autour des techniques de codage. En effet, réaliser un projet de plusieurs heures nécessite d’autres compétences que la programmation.
Avertissement
Les programmeurs motivés ont tendance à coder vite, sans prendre le temps de réfléchir à la conception, ce qui produit du code désorganisé. S’apercevant que leur conception est bancale, ces programmeurs vont reformuler les différentes parties de leur programme en espérant améliorer leur conception. Malheureusement, sans prendre davantage de recul, ils transforment leur conception bancale en une autre conception bancale, tout aussi peu satisfaisante.
Le secret pour concevoir un programme long est de prendre de la hauteur et du recul. Vous devez maintenant réfléchir en considérant les besoins et les objectifs demandés. Prendre ce temps de réflexion implique de s’éloigner momentanément du codage et ce n’est pas facile lorsque l’on a envie de coder. Cependant, les trois principes proposés vont vous aider à réaliser la conception la plus adéquate possible. Nous les détaillons ci-dessous :
Identifier
Identifier les données et les actions/traitements constitue le premier principe. Il devrait idéalement s’effectuer avant l’écriture du programme. En effet, lorsque l’on vous décrit un projet, comme PacMan par exemple, vous savez qu’il va falloir représenter en mémoire le décor ainsi que les PacGums. Il faudra aussi gérer les éléments du jeu comme PacMan, les quatre fantômes, les bonus et les super PacGums. Évidemment, il faudra aussi gérer les interactions entre tous ces éléments : PacMan ne doit pas traverser les murs, lorsqu’il passe sur une PacGum, celle-ci doit disparaître, comme les bonus par ailleurs. Les fantômes peuvent manger PacMan sauf s’il a avalé récemment une super PacGum… Au final, en listant l’ensemble des données et des traitements, vous arrivez à identifier 90% des besoins. Chacun de ces besoins étant inhérent au programme, ils se traduisent par la mise en place de variables et de fonctions.
Note
Pourquoi lorsque nous cherchons à identifier les données et les actions/traitements du projet, nous n’arrivons à détecter que 90 % de nos besoins ? Les 10% restants correspondent à des cas difficilement identifiables lors de la phase d’étude préliminaire. Ces besoins apparaîtront plus tard généralement durant une phase de tests. Par exemple, dans le jeu PacMan, les concepteurs se sont rendus compte que les joueurs avaient tendance à cliquer trop tôt sur le joystick pour faire tourner PacMan. Ils ont donc dû ajouter des traitements pour conserver en mémoire la dernière demande de déplacement afin d’améliorer la jouabilité.
Nous pouvons citer cette règle pour les variables :
CONSEIL : 1 information = 1 variable
La règle 1 information = 1 variable sous-entend que ce n’est pas 0 variable (dans ce cas il y a oubli) ni 2 ou plus (ici il y a redondance). Cela paraît évident. Pourtant, ces situations sont communes :
Il est souvent très facile de créer des redondances sans s’en rendre compte. Par exemple, un rectangle peut se représenter à partir des coordonnées du coin en haut à gauche et du coin en bas à droite ainsi que sa largeur et sa hauteur. Cependant, lorsque l’on connaît, un coin, sa largeur et sa hauteur, on peut facilement déduire les coordonnées de l’autre coin. Il faut ainsi minimiser l’information à stocker : deux coins ou un coin avec les dimensions.
Il arrive parfois de ne pas créer une variable pour une donnée. Il est courant d’utiliser les coordonnées d’un point (x,y) qui a été translaté par (tx,ty) Cependant, même si ces coordonnées sont utilisées une dizaine de fois dans le code, il est courant de voir écrit une dizaine de fois x+tx. Il est beaucoup simple et lisible de créer une variable xt stockant cette valeur et de l’utiliser en lieu et place.
Structurer
Structurer les données et les actions représente le deuxième principe. Une fois un besoin identifié, il faut gérer son traitement dans une zone identifiée du programme, généralement, à l’intérieur d’une fonction. A ce niveau, il est préférable de respecter l’association suivante :
CONSEIL : 1 action/traitement = 1 fonction
Pour atteindre cet objectif, il faut que l’action à accomplir soit clairement identifiée et que son périmètre soit clairement délimité. Il faut en parallèle que le traitement mis en place dans le code soit en correspondance avec ce besoin. Cela peut sembler évident, mais ce n’est pas si facile.
Note
Parfois l’action n’est pas correctement identifiée : on peut par exemple trouver une fonction Gestion(), au titre peu évocateur, regroupant plusieurs traitements sans lien cohérent : collision du héros avec les murs, déplacement des monstres et mise en place des bonus. Il est impossible d’associer une thématique à cette séquence. Ce n’est pas la gestion du jeu, car il manque l’affichage ou l’IA des monstres. Ce n’est pas non plus la gestion du héros, car on fait bien d’autres choses à l’intérieur.
Améliorer
Améliorer la structure actuelle correspond au troisième principe. Après avoir fait un choix de conception vous semblant convenable, vous allez parfois avoir l’impression que l’organisation du code n’est pas idéale, qu’il faudrait trouver une meilleure conception et peut-être aller dans une autre direction. Tout d’abord, sachez que cette situation est normale. Vous écrivez vos programmes par rapport aux besoins exprimés. Mais souvent, on découvre de nouveaux besoins en cours de route. De plus, certains demandes peuvent s’avérer finalement peu séduisantes, coté Game Design par exemple. Il faut donc modifier le programme en conséquence et la conception aussi parfois.
Note
Comment savoir si la structuration d’une fonction nécessite encore des améliorations ? Un point important lorsque l’on cherche à améliorer le code est la question de la réutilisabilité. Si vous avez mis en place une fonction dans votre programme qui semble très similaire à d’autres fonctions déjà existantes. Ne peut-on pas les fusionner en ajoutant des paramètres supplémentaires pour qu’une seule fonction puisse traiter plusieurs configurations ? Le fait qu’une fonction soit adaptable à d’autres configurations que celles prévues au départ ou qu’une fonction soit réutilisable dans d’autres parties du programme ou dans d’autres programmes est un gage de qualité de sa conception.
Les dépendances entre fonctions
Dépendance implicite
Lorsqu’une fonction regroupe un ensemble de traitements cohérents au niveau de sa thématique, on peut penser que sa structuration est réussie. Pourtant, cela n’assure pas totalement une structuration correcte ! En effet, une partie du traitement de cette fonction peut être effectuée dans une autre partie du programme qu’elle ne contrôle pas. Dans ce cas apparaît une dépendance de la fonction à une autre partie de code sans lien direct. Prenons l’exemple de la fonction GestionMonstres() qui appelle GestionMomies() et GestionSerpents(). Tout semble aller pour le mieux. Cependant, il existe une fonction GestionScorpions() appelées par ailleurs. Même si le programme fonctionne correctement, il s’agit ici d’une erreur de conception. En effet, si une fonction a pour objectif de gérer les monstres, elle doit tous les gérer !

Si la partie appelant la fonction GestionScorpions est modifiée ou supprimée, nous pouvons nous attendre à ce que le jeu dysfonctionne. Ainsi, structurer implique de regrouper 100% des traitements nécessaires à l’intérieur d’une fonction ceci en utilisant éventuellement des sous-fonctions, mais ces sous-fonctions doivent être pilotées entièrement par la fonction que l’on vient d’écrire.
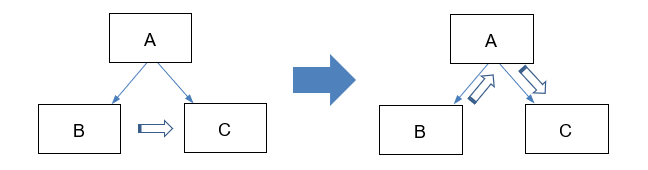
Dépendance chronologique
Une fonction A() peut appeler une fonction B() puis une fonction C(). Cependant, il se peut que la fonctionne C() pour fonctionner correctement nécessite que B() soit appelée avant elle. En effet, supposons que la fonction B() effectue un calcul ou une initialisation qu’elle transmet à C() par l’intermédiaire d’une variable globale. Cette dépendance n’est pas visible mais elle existe. Ainsi, dans la fonction A() on change l’ordre d’appel en permutant l’appel de B() et de C(), aucune erreur ne sera signalée et le programme risque de dysfonctionner.
Ainsi, pour éviter de créer ce type de dépendance, il peut être utile de retourner le résultat de B() à la fonction appelante pour le transmettre ensuite à la fonction C(). Cette écriture rendra la dépendance explicite et évitera de permutter les ordres d’appels.
Note
Attention, nous avons donné un grand principe : lorsqu’une dépendance existe localement, il est mieux de la rendre explicite. Cependant d’autres variables, comme les points du vie du héros, risquent d’être stockées en global. Beaucoup de fonctions vont modifier cette valeur : explosion, flèches empoisonnées, potions de soin, sort de régénération… Et il existe donc une dépendance chronologique sur l’ordre des traitements ! Par exemple, si le héros a 5 points de vie, le fait que la boule de feu faisant perdre 10 points de vie soit gérée avant ou après la sort de soin peut tout changer pour notre héros. Cependant, à ce niveau, on ne se pose pas cette question car il y a trop d’évènements. Qu’importe ce qu’il arrive à notre héros, on considérera que c’est le coup du sort !