String
Les littéraux
Dans vos programmes vous allez écrire des littéraux sous la forme suivante :
... "Bonjour" ...
Cette syntaxe date de l’époque du langage C. Elle correspond à la création un tableau de caractères. Dans cette écriture, le backslash \ permet d’insérer des caractères spéciaux comme \t pour une tabulation. Dans cette logique, pour insérer 1 backslash dans votre texte, il faudra donc le doubler \\.
Note
Si votre stage se déroule sous Windows, pour écrire le chemin "c:\temp\highscores.txt", il faut écrire "c:\\temp\\highscores.txt".
Le type string
La librairie standard du C++ (std) intègre le type string pour représenter des chaînes de caractères. Pour pouvoir l’utiliser dans un programme, il faut inclure la librairie string en début de fichier par la commande #include <string>.
Note
Le type chaînes de caractères n’est pas un type fondamental du C++ comme int ou double. En effet, aucun mot-clef du langage C++ ne fait référence à ce type. D’autre part, il faut inclure la librairie <string> et écrire std::string pour avoir accès à ce type.
Initialisation
Il existe deux manières d’initialiser une variable de type string. Nous les présentons ci-dessous.
#include <string>
#include <iostream>
int main()
{
std::string s1 = "Example 1"; // syntaxe 1
std::string s2("Example 2"); // syntaxe 2
std::cout << s1 << std::endl;
std::cout << s2 << std::endl;
}
Il n’est pas possible de créer une variable de type string à partir d’un numérique.
Concaténation
Le signe + entre deux chaînes de caractères permet de concaténer ces deux chaînes. Cette opération permet d’accoler les deux chaînes de caractères bout à bout pour n’en former plus qu’une. Voici un exemple illustrant la concaténation :
#include <string>
#include <iostream>
int main()
{
std::string s1 = "Je mange ";
std::string s2 = "des fruits.";
std::string s3 = s1 + s2;
std::cout << s3; // ==>> Je mande des fruits.
}
L’opérateur de concaténation + accepte les littéraux caractères. L’écriture suivante est donc valide :
std::string s1 = s1 + " ---- " + s2;
Mais l’opérateur de concaténation + n’accepte pas les numériques.
Conversion
Numérique vers string
Il est possible de convertir un numérique vers un string en utilisant la fonction to_string(…) de la librairie <string>. Ainsi, on peut initialiser un string à partir d’un numérique :
#include <string>
#include <iostream>
int main()
{
std::string s1 = std::to_string(42); // syntaxe 1
std::string s2(std::to_string(42)); // syntaxe 2
std::cout << s1 << std::endl;
std::cout << s2 << std::endl;
}
Grâce à cette fonction, on peut ainsi utiliser des numériques dans les concaténations :
#include <string>
#include <iostream>
int main()
{
int age = 20;
std::string s = "J'ai " + std::to_string(age) + " ans";
std::cout << s;
}
String vers numérique
Pour convertir un string vers un entier, la librairie <string> fournit la fonction stoi(..).
#include <string>
#include <iostream>
int main()
{
std::string s = "20";
int total = std::stoi(s) + 30;
std::cout << total;
}
Pour convertir un string vers un double, la librairie <string> fournit la fonction stod(..).
#include <string>
#include <iostream>
int main()
{
std::string s = "12.45";
double v = std::stod(s);
std::cout << v;
}
Détection d’une sous-chaîne
Il est possible de vérifier si une chaîne de caractères apparaît dans une autre grâce à la fonction find(). Cette fonction est disponible depuis une variable string existante :
#include <string>
#include <iostream>
int main()
{
std::string s = "Il y a douze mois dans le calendrier";
if ( s.find("treize") == std::string::npos )
{
std::cout << "Texte non trouvé";
}
}
Indiquez si les affirmations suivantes sont vraies ou fausses :
L’écriture "3" correspond à un littéral.
Pour créer un string, une seule syntaxe est possible.
Le type string est un type fondamental du C++.
La librairie <cstring> permet d’accèder au type string.
la librairie <string> fait partie de la librairie standard du C++.
Concaténer une chaîne consiste à retirer les caractères inutiles.
On peut concaténer un string avec un int.
L’écriture : string s = 42 convertit un int en string.
La fonction stod() convertit un double en string.
La fonction stoi() prend en paramètre un string.
La fonction to_string() permet de convertir un numérique en string.
Les variables s1 et s2 représentent des variables de type string initialisées à "BOB" et "EVA". Pour chacune des expressions, donnez le résultat SANS guillemets s’il existe ou indiquez ERR :
Expression |
Résultat |
|---|---|
"Hello" + 4 |
|
s1 + "_" + s2 |
|
s1 + 5 |
|
to_string(50) |
La librairie string
Présentation
Rendez-vous sur le site de la documentation en ligne du C++ : https://www.cplusplus.com/. Choisissez la section référence qui nous donne accès à la liste des librairies de la bibliothèque standard du C++. Recherchez la librairie <string> et non <cstring> correspondant au portage des anciennes fonctions du langage C. Vous devriez voir apparaître la page suivante :
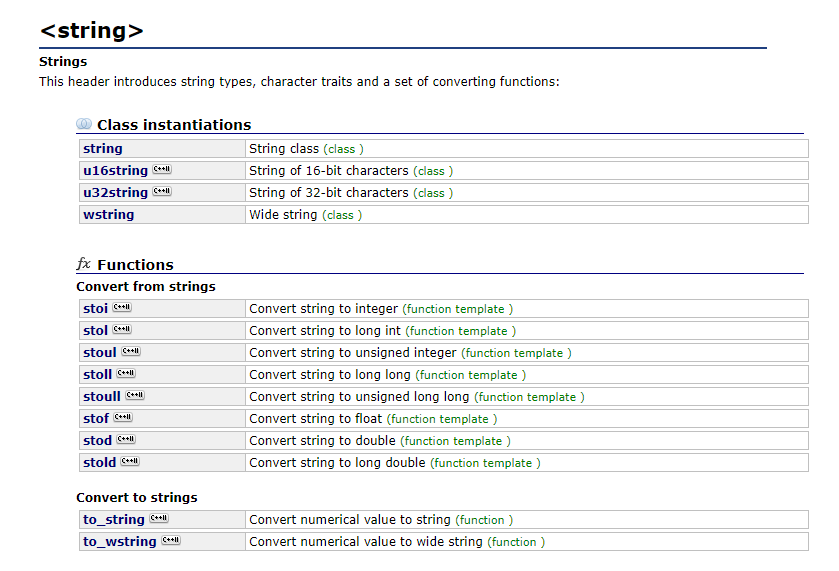
Vous retrouvez les diverses fonctions de conversion :
stod : conversion d’un string vers un double
stoi : conversion d’un string vers un int
et bien d’autres encore..
Les chaînes de caractères sont toujours un sujet délicat et ceci quel que soit le langage… En effet, nous pouvons remarquer qu’il existe dans la librairie string du C++ quatre types pour créer une chaîne de caractères. Nous venons d’ouvrir la boite de Pandore !
Avant d’aller plus loin, il faut connaître quelques notions basiques sur les chaînes de texte :
Comment représenter un caractère ?
Comment encoder un caractère ?
Le codage des caractères
Un codage associe un numéro à un caractère de manière unique, comme le fait un numéro de plaque d’immatriculation pour une voiture ou un numéro de sécurité sociale pour une personne. Il existe aujourd’hui deux grands codages des caractères dans le monde informatique, l’un est historique l’autre est devenu un incontournable. Nous vous les présentons ci-dessous :
L’ASCII
Le codage ASCII datent des années 60. Au départ, il comporte 127 codes associés représentant :
Les lettres de l’alphabet latin en version majuscule/minuscule
Les 10 chiffres
Des caractères spéciaux : ( ) [ ] { } , ; : . ! % * $ = …
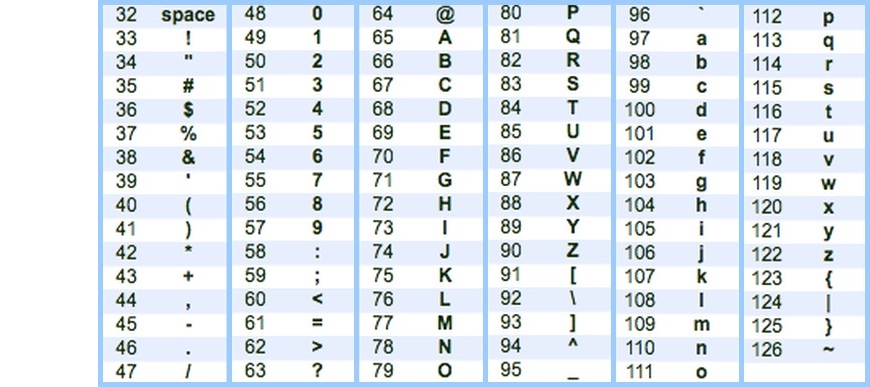
Par exemple, la suite de valeurs 78 79 78 code les lettres NON.
L’Unicode
Le standard Unicode couvre plus de 150 écritures et représentent plus de 144 697 caractères. La table Unicode peut être parcourue sur des sites spécialisée. Les caractères ont été regroupés par thématiques et par langues. Pour des raisons de compatibilité, la plage 0-128 correspond à la table ASCII.
L’encodage
Un éditeur de texte moderne, comme Notepad++ connaît le format Unicode. Pour tester cela, vous pouvez copier-coller un caractère Unicode depuis internet dans Notepad++ et il apparaîtra à l’identique. Il serait simple de coder chaque caractère Unicode en utilisant 4 octets. Cependant, en sauvegardant, vous obtenez un fichier 4 fois plus long qu’un fichier texte n’utilisant que de l’ASCII. Ce n’est pas l’option qui a été retenue. Lorsque vous sauvegardez un fichier texte, un encodage est appliqué. Ainsi, les codes des caractères Unicode sont encodés sur un nombre variable d’octets. Les codes les plus courants sont encodés sur un minimum d’octets pour optimiser la taille des fichiers.
Le codage UTF-8
L’encodage UTF-8 se fait par tranche de 1 octet. La forme sur 1 octet est reconnaissable par le premier bit mis à 0. La forme sur 2/3/4 octets commence par des séquences de bits : 110, 1110 et 11110 respectivement. Les octets commençant par les bits 10 indiquent que l’octet courant n’est pas le démarrage d’une série. Nous présentons le tableau d’encodage ci-dessous :
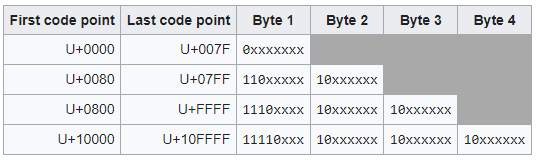
Les 128 premiers caractères de l’ASCII&Unicode nécessitent un seul octet lors de l’encodage. Les 1920 caractères suivants ont besoin de deux octets pour être codés, ce qui couvre le quasi-restant des alphabets latins, grec, cyrillique, arménien, hébreu ou arabe… Trois octets sont nécessaires pour représenter les caractères multilingues de base, comprenant tous les caractères d’usage courant, y compris la plupart des caractères chinois, japonais et coréens. Quatre octets sont nécessaires pour les caractères des autres plages d’Unicode comprenant diverses écritures historiques, des symboles mathématiques et des emoji.
Le codage UTF-16
Le principe reste le même que pour l’UTF-8. Cette fois l’encodage fonctionne par tranche de 2 octets. Ainsi, il n’y a que deux tailles possibles pour un encodage : 2 ou 4 octets.
Indiquez si les affirmations suivantes sont vraies ou fausses :
La librairie <string> fournit 1 seul type de chaîne de caractères.
Le codage de caractères consiste à associer à numéro à chaque symbole.
Le codage ASCII représente l’alphabet grec.
Le codage ASCII contient les chiffres.
La lettre X a un code ASCII supérieur à 128.
La lettre -a- et -A- ont le même code en ASCII.
L’unicode compte environ 10 000 caractères à ce jour.
Les couples codes/caractères ASCII sont repris en Unicode.
L’UTF-8 est un système d’encodage sur un nombre variables d’octets.
L’UTF-8 utilise de 1 à 8 octets pour encoder une valeur.
Pourquoi le type string dysfonctionne ?
Tests pratiques
Pourquoi ces informations sur l’encodage UTF-8 et l’Unicode ? Nous allons prendre deux situations. Dans la première, tout va se comporter normalement. Dans la seconde, sans quasiment rien changer dans votre chaîne de caractères, vous allez constater que les opérations basiques ne fonctionnent plus comme prévu.
Voici un exemple :
#include <iostream>
using namespace std;
int main()
{
string s = "Hello";
cout << s << " ";
cout << s.length() << " ";
cout << s[0] << " ";
cout << s[1] << " ";
cout << s[4] << " ";
cout << endl;
return 0;
}
Dans ce premier exemple, nous créons d’abord une chaîne de caractères représentant le mot « Hello ». Les affichages se passent sans encombre :

Voici ce que nous obtenons :
L’affichage de Hello s’effectue correctement
La longueur de la chaîne est bien de 5 lettres
La première lettre est H
La seconde lettre est e
La dernière lettre est o
Aucune erreur n’apparaît ! Ceci est normal, car dans notre texte, nous avons choisi que des caractères ASCII. Ainsi, l’encodage UTF-8 se comporte comme un encodage ASCII et il utilise 1 seul octet par caractère. Par conséquent l’appel de s.length() retourne la longueur exacte de la chaîne. De la même manière l’accès au i-ème caractère s[i] retourne le i-ème caractère correctement.
Dans le deuxième exemple ci-dessous, nous gardons le même mot mais nous remplaçons le second caractère par un é :
#include <iostream>
using namespace std;
int main()
{
string s = "Héllo";
cout << s << endl;
cout << s.length() << endl;
cout << s[0] << " ";
cout << s[1] << " ";
cout << s[4] << " ";
cout << endl;
return 0;
}
Voici le résultat que nous obtenons :

Avant de commenter, nous rappelons l’encodage UTF-8 de :
Hello : | 72 | 101 | 108 | 108 | 111 |
Héllo : | 72 | 195 | 169 | 108 | 108 | 111 |
Dans cet exemple, l’encodage UTF-8 du caractère é utilise 2 octets. Comment se comporte les choses :
L’affichage se passe correctement car la console sait décoder l’UTF-8.
La méthode length() retourne 6 au lieu de 5. Le C++ pense toujours gérer une chaîne en ASCII. Il indique basiquement le nombre d’octets utilisés pour stocker cette chaîne.
L’indexation [i] fournit un affichage correct du premier caractère. Cependant, l’affichage du second caractère est erroné, en effet, la syntaxe s[1] retourne le premier des deux octets encodant le caractère é, c’est à dire la valeur 195. Cette valeur n’a pas de sens pour la console et l’affichage est incohérent. L’affichage du dernier caractère correspond en fait à l’avant dernier, ceci vient du décalage induit par le caractère é prenant deux octets au lieu d’un seul.
Solutions
ASCII only
Cette approche consiste, pour accéder à l’ensemble des fonctionnalités des strings, à n’utiliser que les caractères ASCII. Ce n’est pas glorieux, mais ça fonctionne.
UTF-8
C’est la solution la plus simple et la plus répandue aujourd’hui. Le type string est utilisé pour stocker des chaînes Unicode en UTF-8 !!! Comme nous l’avons vu, pour l’affichage, les initialisations, la concaténation ou la recherche, cela est compatible. Par contre, ce choix suppose que l’on évite les fonctions retournant des résultats erronés comme la fonction length().
Indiquez si les affirmations suivantes sont vraies ou fausses :
La fonction length() des string renvoie une longueur correcte tout le temps.
Concaténer deux strings stockant de l’UTF-8 est possible.
Un accent présent dans une string peut faire boguer certaines fonctions.
L’affichage n’est pas perturbé par l’encodage en UTF-8.