La compilation séparée
La compilation séparée désigne le fait de compiler plusieurs fichiers sources séparément puis de les lier ensuite pour générer un exécutable par exemple.
Rappel
Le Build
La génération d’un programme (build en anglais) désigne le processus consistant à transformer des codes sources au format texte en programme exécutable sur un type de machines donné. Ce processus repose sur deux actions :
La compilation transforme chaque fichier source (.cpp) en un fichier objet.
La liaison fusionne les différents fichiers objets pour obtenir le programme exécutable final.
Voici un schéma qui représente le traitement des différents fichiers sources et des fichiers objets durant l’étape de Build :
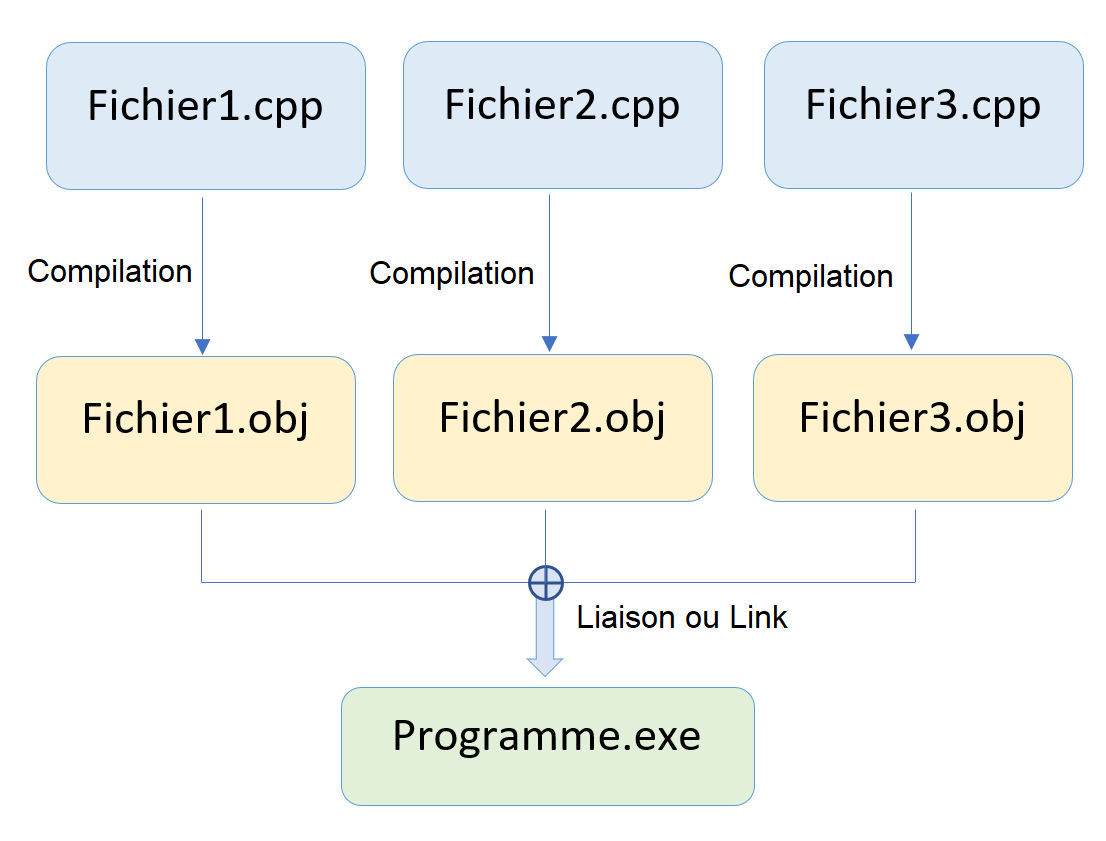
Lors du Build, chaque fichier est compilé séparement : il n’a pas connaissance des autres fichiers cpp et de leur contenu.
Le principe général
Dans la terminologie du langage C++, une déclaration et une définition sont deux notions proches mais différentes.
Une déclaration introduit ou réintroduit un nom dans un programme C++.
Une définition est un cas particulier des déclarations. Une définition correspond à une déclaration donnant suffisamment d’informations pour utiliser l’entité associé au nom déclaré.
Si un seul fichier cpp existe, le principe général des déclarations / définitions est le suivant :
REGLE 1 : Un nom est défini UNE UNIQUE fois dans tout le fichier cpp.
REGLE 2 : Pour utiliser un nom, il faut l’avoir déclaré/défini auparavant.
Note
On peut cependant déclarer autant de fois que l’on veut un nom.
Que se passe-t-il lorsque nous avons plusieurs fichiers sources ? Les règles 2 et 3 sont conservées. Mais la règle 1 évolue :
REGLE 1 - fonction : Lorsque nous avons plusieurs fichiers cpp, un nom de fonction doit être DEFINI UNE UNIQUE FOIS POUR L’ENSEMBLE DES FICHIERS CPP.
Cependant, pour les structures, la règle est différente :
REGLE 1 - structure : Lorsque nous avons plusieurs fichiers cpp, un nom de structure/classe doit être DEFINI DANS CHAQUE FICHIER CPP où ce nom est utilisé.
Avertissement
Attention, ces deux règles vont établir les règles d’usage en développement C++ décrites dans la suite. Il faut bien remarquer leur différence et ne pas les confondre.
Exporter des fonctions
Approche basique
Supposons que nous ayons une fonction DetectionCollision() définit dans un fichier collision.cpp. Si nous voulons l’utiliser dans un autre fichier test.cpp, nous ne pouvons pas copier coller sa définition, sinon nous ne respecterions pas la règle 1 et le build donnerait une erreur. La solution -basique- consiste à écrire la déclaration de cette fonction dans le fichier test.cpp avant son utilisation :
// fichier collision.cpp
...
bool DetectionCollision(..) // définition
{
...
}
// fichier test.cpp
bool DetectionCollision(..); // déclaration
...
void fnt()
{
...
bool t = DetectionCollision(..); // appel
}
Au niveau de la compilation, tout est correct :
La fonction est définie une unique fois dans tous les fichiers cpp.
Elle est déclarée avant son utilisation dans le fichier test.cpp.
Au moment de la création du fichier exécutable, le linker fera le lien entre l’appel de la fonction DetectionCollision() dans test.cpp et son code présent dans collision.cpp.
Cette solution fonctionne, elle n’a pas de défaut particulier, mais nous ne la retiendrons pas en production. Nous allons voir comment faire de manière plus orthodoxe.
Approche professionnelle
L’approche précédente pose problème lorsque vous avez des centaines de fonctions à exporter et à importer. Il faudrait à chaque fois copier-coller les déclarations nécessaires, ce n’est pas très pratique. Une solution plus élégante consiste à utiliser les fichiers d’entête ou header files du C++, les fameux fichiers .h ou .hpp.
CONVENTION 1 : A chaque fichier source (.cpp) correspond un fichier d’entête .h contenant toutes les déclarations des fonctions que vous souhaitez exporter au reste du programme.
CONVENTION 2 : Chaque fichier source (.cpp) inclut son propre fichier d’entête.
Comment importer ces déclations ? C’est le rôle du préprocesseur et de la directive #include. Cette directive a pour objetif de copier-coller tout le contenu du fichier indiqué dans le fichier .cpp en cours de compilation. Ainsi, cela importe directement dans le fichier source toutes les déclarations présentes dans le header. Voici l’exemple précédent modifié :
// fichier collision.h
...
bool DetectionCollision(..); // déclaration
// fichier collision.cpp
#include "collision.h"
...
bool DetectionCollision(..) // définition
{
...
}
// fichier test.cpp
#include "collision.h" // import des déclarations
...
void fnt()
{
...
bool t = DetectionCollision(..); // appel
}
Exporter des structures
Option 1
Comme on l’a vu précédemment, les structures doivent être définies dans chaque fichier source où elles sont utilisées. Il faudrait donc copier coller la définition d’une structure dans chaque fichier source. Personne n’oserait faire cela ! On va donc préférer mettre une UNIQUE FOIS la définition d’une structure/classe dans un fichier .h.
// fichier V2.h
struct V2
{
float x,y;
float norm() {...}
void normalize() {...}
};
Ainsi, on retrouve un style très proche du Java. Il reste à inclure le fichier V2.h dans chaque fichier header (.h) ou source (.cpp) où les V2 sont utilisées.
Option 2
Il est possible de ne donner dans le fichier header que les déclarations des fonctions membres. Leurs définitions peuvent être mises dans le fichier cpp associé. L’intérêt est de retirer du fichier d’entête le code des fonctions et de le déplacer là où on le trouve habituellement : à l’intérieur d’un fichier cpp. Cela a le mérite d’éclaircir le contenu du fichier d’entête qui ne contient alors que des déclarations. Il faut utiliser une syntaxe spécifique utilisant l’opérateur de résolution de portée :: indiquant que la fonction appartient à une structure :
// fichier V2.h
struct V2
{
float x,y;
float norm();
void normalize();
};
// fichier V2.cpp
#include "V2.h"
float V2::norm() {...} // l'écriture V2:: indique l'appartenance de cette fonction à la structure V2
void V2::normalize() {...}
Note
Il est possible d’utiliser l’option 1 pour certaines fonctions et l’option 2 pour les autres fonctions de la structure. Généralement, l’option 1 est choisie pour des fonctions très courtes comportant une seule instruction.
Inclusions multiples
Ce scénario est un classique ! Supposons que nous ayons un header V2.h inclus dans deux autres headers collision.h et path.h. Jusque là, aucun soucis. Maitenant, un fichier eleve.cpp inclut à la fois le header collision.h et le header path.h. Que risque-t-on ? En fait, en jouant le jeu des copiers-collers avec les #include, le contenu de V2.h va être copié-collé deux fois en tout dans eleve.cpp.
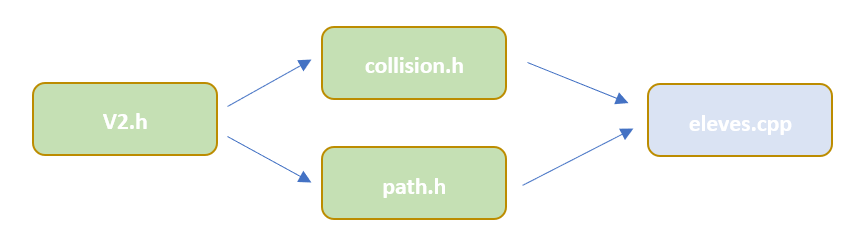
Est-ce un problème ?
Pour les fonctions, le fait d’avoir plusieurs déclarations de la même fonction dans le même fichier ne pose pas de problèmes.
Pour les structures, le fait d’avoir plusieurs définitions de la même structure dans un même fichier POSE problème.
Dans cette situation, en compilant le fichier eleve.cpp, vous allez obtenir cette erreur : redéfinition de la structure V2. Sans connaître ce problème, il vous faudra un long moment pour recoller les morceaux.
Pour éviter cette situation, nous utilisons un tag spéficique en début de fichier : #pragma once. Cet indicateur précise au préprocesseur de ne pas réinclure le header en question une deuxième fois si cela devait arriver par le jeux de inclusions multiples. Ainsi, il faut écrire :
#pragma once
struct V2
{
float x,y;
float norm();
void normalize();
};
Les problèmes
Les dépendances cycliques
Ce scénario arrive lorque
Le fichier A.h inclut le fichier B.h
Le fichier B.h inclut le fichier A.h
Cette situation est rare et il faut tout faire pour l’éviter car le C++ refuse catégoriquement ce genre de situation : en compilant A.cpp, le précompilateur va inclure (copier-coller) le contenu de son header A.h, ensuite le header A.h incluant le fichier B.h, le préprocesseur va donc copier-coller le contenu de B.h, mais le contenu de B.h incluant le contenu de A.h… bref le préprocesseur va effectuer des inclusions à l’infini et il finira par crasher.
Note
Dans un programme complexe, il n’est pas rare d’avoir des milliers de .h qui s’incluent les uns les autres. En rajoutant une inclusion supplémentaire, on peut créer ce scénario.