KERAS + TDA + TDB
Boucle implicite
Comme dans le cas du Broadcasting, il existe un mécanisme implicite de traitement pour chaque couche d’un réseau de neurones, nous allons le présenter maintenant. Tout d’abord, on part du principe que chaque couche, en fonction de sa nature, est conçue pour traiter un tableau 1D, 2D ou 3D. Par exemple, supposons que la couche que l’on utilise traite des données 1D de taille (128) et qu’elle construit en sortie un tenseur de taille (10). Si on lui présente un tenseur de taille (20,128), elle va alors accepter de traiter ce tenseur en effectuant une boucle implicite:
def My1DLayer_in128_out10(Input):
if Input.shape[-1] != 128 :
raise Exception('bad dimensions')
if len(Input.shape) == 1: # tenseur 1D en entrée
return Process(Input)
if len(Input.shape) == 2: # tenseur 2D en entrée
nb = Input.shape[-2]
Output = NewArray(nb,10)
for i in range(nb):
Output[i] = Process(Input[i])
return Output
...
Ainsi, un tenseur de taille (30,128) est traité par cette couche comme 30 échantillons indépendants de taille 128. De cette façon, chaque échantillon va être traité l’un après l’autre et leurs résultats vont être empilés dans le tenseur de sortie de taille (30,10). Si l’on note nb le nombre d’échantillons, on peut dire qu’une entrée de taille (nb,128) donne après traitement un tenseur de taille (nb,100).
Note
Dans les librairies, la valeur de nb étant seulement connue lors du traitement, on trouve donc cette écriture : (None,128)→(None,10).
Le mécanisme s’étend au couche traitant un tableau 2D. Par exemple, si une couche accepte en entrée un tenseur de taille (32,32), alors un tenseur de taille (100,32,32) sera traité comme l’injection consécutive de 100 échantillons de taille (32,32) dans cette couche.
Les différentes fonctions de Forward
Les trois écritures suivantes effectuent chacune une passe Forward :
y = model.evaluate(x)
y = model.predict(x)
y = model(x)
avec x un tableau d’échantillons. Pourquoi disposer de trois fonctions différentes pour effectuer une passe Forward ? En fait, elles n’ont pas le même rôle :
L’opérateur () s’utilise pour entraîner le réseau. Il effectue une passe Forward mais en plus de cela, il conserve les résultats intermédiaires de chaque couche afin d’effectuer la passe Backward pour calculer le gradient.
Les fonctions predict() et evaluate() sont utilisées pour connaître la réponse du réseau. Dans cette configuration, pas d’apprentissage, on effectue uniquement une passe Forward sans conserver d’informations au niveau des couches intermédiaires.
Avertissement
Vous n’avez pas normalement à utiliser l’écriture model(x) car elle correspond à l’utilisation avancée de Keras où on cherche à écrire sa propre fonction d’optimisation. Cependant, vous pourrez croiser cette écriture dans les exemples sur le net. Il est important de s’en méfier car si un code fait appel à cette écriture pour faire un affichage à l’écran, cela va impacter le calcul du gradient, ce qui n’est pas le rôle d’une fonction d’affichage.
Il existe une distinction entre les fonctions predict() et evaluate() :
predict() : calcule la sortie du réseau et retourne les logits (sans appliquer la fonction d’erreur).
evaluate() : cette fonction retourne l’erreur totale du réseau.
Qui, quoi et quand ?
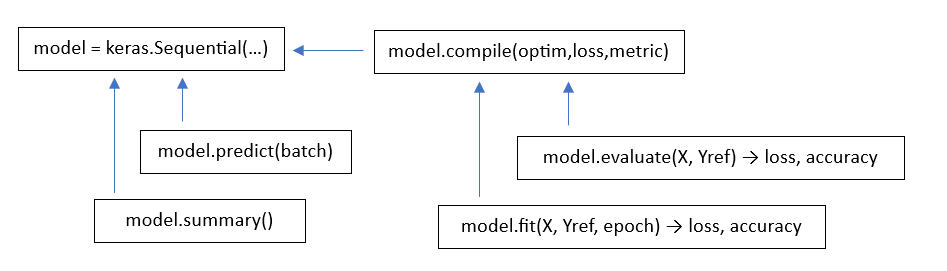
Certaines fonctions sont dépendantes d’autres fonctions pour pouvoir travailler correctement. Ainsi, elles peuvent être appelées à certains moments et pas à d’autres. Voici un rapide rappel des différentes dépendances :
Tout d’abord, on crée un réseau séquentiel en utilisant le constructeur keras.Sequential().
Une fois le réseau créé, on peut appeler les fonctions :
summary() qui donne la taille des paramètres internes utilisés par chaque couche.
predict() qui effectue une passe Forward simple pour connaître les valeurs en sortie du réseau.
Note
La fonction predict() prend obligatoirement un tableau d’échantillons en entrée. Si vous voulez traiter 1 seul échantillon, il faudra effectuer un reshape pour lui donner une dimension de la forme (1,…).
Une fois le réseau créé, grâce à la fonction compile(), on lui associe :
un optimiseur
une fonction d’erreur
une métrique, fonction utilisée pour évaluer la performance du réseau, comme par exemple le % de bonnes réponses.
Une fois les informations nécessaires à l’apprentissage transmises, on peut utiliser les fonctions suivantes :
fit(X,Yref,epoch=n) : qui lance n epochs d’apprentissage, en utilisant les données d’entrée X et les labels de référence Yref.
evaluate(X,Yref) : effectue une passe Forward simple et retourne la valeur de l’erreur et de la métrique pour les échantillons transmis.
Voici un graphique qui présente les différentes dépendances :
TD-A
Voici le TD d’introduction à Keras.
TD-B
Nous passons maintenant à la vitesse supérieure avec le TD sur les réseaux convolutionnels.