Datasets
Organisation
Pour commencer, nous allons étudier le format des données des différentes bases d’images disponibles dans la bibliothèque Keras. Ci-après, nous vous donnons un d’exemple servant à charger quatre bases. A la première exécution, cela peut prendre un moment.
import os
os.environ["KERAS_BACKEND"] = "torch"
import keras_core as keras
MNIST = keras.datasets.mnist.load_data()
CIFAR10 = keras.datasets.cifar10.load_data()
CIFAR100 = keras.datasets.cifar100.load_data()
FASHION = keras.datasets.fashion_mnist.load_data()
En écrivant du code Python, vous devez déterminer comment sont organisées les données, autrement dit que retourne la fonction load_data() ?
Le type des différents objets : tableaux numpy, tableaux Pytorch…
La taille des différents tableaux
Le type de stockage des données :uint8, int8, int32…
Le nombre d’échantillons dans le set d’apprentissage et dans le set de validation
Le type des images : RGB ou N&B
Leur standard : Channel First (Channels,Height,Width) ou Channel Last (Height,Width,Channels) ?
Les images sont-elles regroupées par catégorie dans le tableau, ou sont-elles déjà mélangées ?
Pour les questions suivantes, il faudra vous aider d’Internet :
Quelle est la différence entre CIFAR10 et CIFAR100 ? Car leurs tableaux semblent exactement de la même taille.
Trouvez les encodages des classes de CIFAR10 et des classes et des groupes de classes de CIFAR100.
Affichage
Dans l’exemple ci-dessous, nous présentons un exemple de code qui charge les images de CIFAR10 et qui affiche les 10 pi
import os
os.environ["KERAS_BACKEND"] = "torch"
import keras_core as keras
import numpy as np
import matplotlib.pyplot as plt
# load data
CIFAR10 = keras.datasets.cifar10.load_data()
cifar10_data = CIFAR10[0][0]
cifar10_labels = CIFAR10[0][1]
# create a 10xNB area for drawing images
def CreateGraphics(NB):
categories = ['Airplane', 'Automobile', 'Bird', 'Cat', 'Deer', 'Dog', 'Frog', 'Horse', 'Ship', 'Truck']
fig, axes = plt.subplots(10, NB, figsize=(15, 15))
plt.subplots_adjust(wspace=0, hspace=0)
for i, ax in enumerate(axes.flat):
ax.set_xticks([])
ax.set_yticks([])
for i,Lax in enumerate(axes) :
Lax[0].set_ylabel(categories[i], rotation=0, labelpad=50)
return axes
def ShowImage(axes,x,y,data):
axes[y][x].imshow(data)
# TODO
axes = CreateGraphics(20)
images = cifar10_data.reshape(-1, 32, 32, 3)
for i in range(10):
ShowImage(axes,i,0,images[i])
plt.show()
Exercice 1
Complétez ce code pour que soit affiché NB vignettes de la bonne catégorie sur chaque ligne.
Exercice 2
Faites en sorte que les images soient sélectionnées au hasard afin qu’à chaque lancement du programme on ait des images différentes à l’écran mais toujours de la bonne catégorie.
Normalisation des données
Dans les images RGB, trois plans de couleurs sont disponibles. En examinant une image de la faune marine, on obtient typiquement un histogramme de la forme suivante :
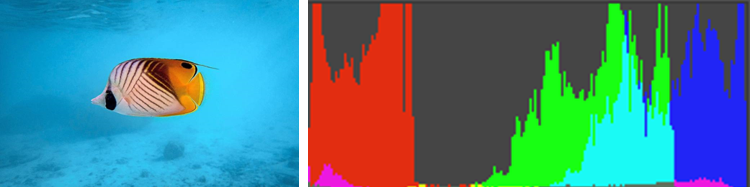
Dans cet histogramme, les valeurs de faible intensité sont comptabilisées sur la gauche et les valeurs de forte intensité sur la droite. Sur cette image, les rouges sont dans la zone 0% à 20% ce qui est normal car ils sont peu présents. Les bleus sont évidemment très présents et lumineux, ils sont donc placés dans les hautes valeurs entre 70% et 100%. La présence de vert dans les hautes valeurs peut surprendre, mais le fond marin tire sur un bleu céleste de valeur RGB (38, 196, 236) ce qui correspond au profil de l’histogramme ci-dessus, avec le niveau des verts 4/5ème en dessous de celui des bleus. Nous rencontrons donc plusieurs problèmes :
Les valeurs sont entre 0 et 255, mais, si nous avions des images 12 bits elles seraient entre 0 et 2048. Le réseau ne pourrait donc pas les gérer.
Dans un même set d’images, on peut avoir une teinte présente sur toutes les images
Pour résoudre le premier problème, il suffit de normaliser les valeurs sur un intervalle [0,1]. Ainsi, quelle que soit la dynamique du capteur : 8, 12, 14 ou 16 bits, on se ramène à la même plage de valeurs.
Pour le second problème, une fois la normalisation effectuée, ce ne devrait pas être si problématique. Les paramètres internes de la première couche peuvent compenser cela :
S’il existe un décalage entre la moyenne des rouges et la moyenne des bleus, le paramètre de biais peut corriger cela.
Si la plage des verts est plus large que la plage des rouges, les autres paramètres internes peuvent se scaler pour compenser cet effet.
Cependant, si on laisse le réseau gérer cela, le temps de « calibration » vient alors s’ajouter au temps d’apprentissage. Pour réduire le temps de convergence, il est d’usage de corriger ces décalages en appliquant le prétraitement suivant :
# IMG : tenseur des images (60 000, 32, 32, 3) -> 60 000 images 32x32 en RVB
for c in range(3) : # pour chaque canal R/V/B
mean = IMG[:,:,:,c].mean() # calcul de la moyenne
std = IMG[:,:,:,c].std() # calcul de la déviation standard
IMG[:,:,:,c] = (IMG[:,:,:,c] – mean) / std # normalisation
Ainsi, on normalise les plans R,V,B pour obtenir une distribution statistique de moyenne nulle et de variance unitaire.
Avertissement
Attention, cette normalisation s’effectue pour chaque canal en tenant compte de la totalité des images. Elle ne s’effectue pas image par image.
Note
On remarque que cette méthode ne permet pas d’équilibrer des images sombres et des images surexposées. Cependant, si l’on examine les images présentes dans la base CIFAR, elles ont globalement une luminosité équilibrée. Ainsi cette question ne se pose finalement pas.
Note
Parfois, dans les exemples que vous trouverez sur internet, il n’y aura pas de normalisation, ou seulement une division par 255. Comme évoqué précédemment, la normalisation peut faire gagner du temps. Si elle n’est pas faite, le temps d’apprentissage sur de petits exemples peut passer de 7 minutes à 9 minutes, ce qui reste finalement acceptable. Mais de 7 jours à 9 jours ou de 7 mois à 9 mois, on ressent plus la différence.
Exercice
Pour la base CIFAR10, trouvez la couleur « moyenne » sur l’ensemble du set d’images. Pour cela, on applique la fonction mean() sur chaque couche R, V et B. A partir des valeurs trouvées, utilisez un site dédié pour trouver la couleur correspondante. La légende veut que ce soit un marron… est-ce vrai ?