Créer une base d’images
Sélectionner des images
Utiliser les moteurs de recherche
Nous vous conseillons une approche simple, rapide et efficace. D’autres options sont possibles, vous êtes libres de choisir. Nous utilisons par exemple le site flickr. En tapant dans la barre de recherche le mot clef pizza, le site nous propose des vignettes associées à cette thématique :
Descendez la page pour faire apparaître de nombreuses vignettes.
Utiliser un image downloader
Comme la quantité d’images à télécharger reste importante, il devient nécessaire de prendre un outil performant. Pour Chrome, nous vous conseillons l’extension : Imageye. Une fois l’extension installée, cliquez sur l’icône pièce de puzzle de Chrome (voir-ci dessous) et épingler l’extension Imageye en cliquant sur la punaise. Une fois cette manipulation effectuée, l’icône de l’extension apparaît à gauche de la pièce de puzzle comme dans l’image ci-dessous.

Cliquez sur l’icône de l’extension pour vérifier le nombre d’images disponibles. Si la quantité vous semble insuffisante, scrollez plus en profondeur la page flickr pour ajouter des images.
Constituer une base de qualité
Il faut viser entre 500 à 5000 images par classe afin de construire une base d’images sérieuse. De plus, pour garantir la qualité de la base, un contrôle visuel s’impose. Si trop d’images parasites sont présentes, les retirer une à une peut devenir un travail trop chronophage, pensez que 1h à 2h de retouche par classe représente un travail de 20h au final. L’objectif est donc d’effectuer une requête sur flickr la plus précise possible. Cela vous évitera d’avoir trop de contrôles à effectuer dans votre base. Prenons l’exemple de la recherche sur le mot-clef frelon, nous voyons apparaître des images :
de l’hélicoptère Super Frelon
de l’araignée Argiope frelon
de nids de frelons

Pour retirer les images parasites, vous avez plusieurs options :
utiliser le - dans la recherche pour retirer des éléments en écrivant : -helicopter ou encore -niddle -spider
spécifier plus en profondeur ce qu’on recherche : insect, frelon asiatique (Asian hornet)
Pour effectuer un contrôle qualité des images téléchargées, nous vous conseillons d’utiliser votre explorateur de fichiers et d’afficher en mode grandes icônes pour visualiser plusieurs images à la fois. Les touches PageUp et PageDown permettant de passer d’une planche d’images à l’autre.

Charger votre base dans Colab
Uploader votre base sur Google Drive
Afin d’éviter d’envoyer les données image par image, nous allons zipper le répertoire principal data stockant les répertoires de chaque catégorie. Vous travaillez donc avec un zip unique pour l’ensemble de vos fichiers images. Nous ne stockons pas directement ce fichier sur une session Colab car le disque des machines virtuelles n’est pas persistant !
Importer vos données dans une session Colab
Créez un notebook Colab vide. Cliquez sur l’icône répertoire présent sur le bandeau gauche :
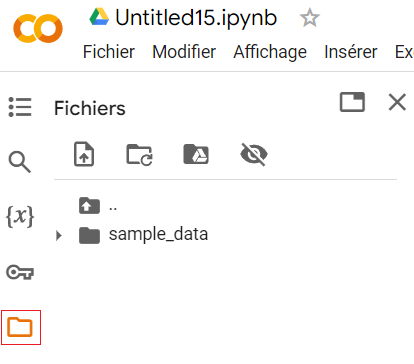
Ainsi apparaît la structure du disque de votre machine virtuelle. Nous allons monter le disque de votre compte Google Drive sur votre session Colab. Créez une cellule de code vide et entrez les commandes suivantes :
from google.colab import drive
drive.mount('/content/GoogleDrive/', force_remount=True)
La directive ! a pour effet d’exécuter une commande unix sur la machine virtuelle. Vous devriez voir apparaître le répertoire GoogleDrive sur le disque. Si ce n’est pas le cas, refermez le bandeau gauche et rouvrez le !
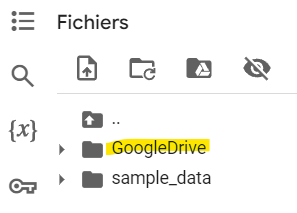
Copiez ensuite votre fichier zip depuis le Drive Google sur le disque de la session Colab :
source = '/content/GoogleDrive/MyDrive/data.zip'
dest = '/content/data.zip'
!cp $source $dest
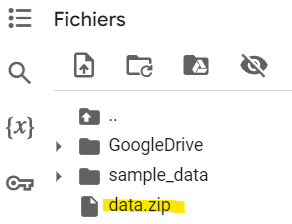
Il ne vous reste plus qu’à décompresser le fichier zip :
!unzip -q data.zip
!ls

Si le résultat obtenu ne vous convient pas, il suffit de déconnecter et reconnecter votre environnement d’exécution pour remettre à zéro le disque.
Accéder à la base partagée par votre binôme
Lorsque votre binôme vous partage la base mise en place sur son drive, vous pouvez voir les fichiers depuis votre compte. Cependant, vous ne pourrez pas y accéder à travers Colab.
En effet, Google Drive n’est pas organisé en interne comme un système de fichiers mais comme un Datalake où chaque fichier reçoit un identifiant unique pour y accéder. Ainsi l’arborescence de fichiers comme on l’a connaît n’est pas obligatoire. Pour associer le répertoire de votre binôme à votre arborescence, il faut créer un raccourci :
Identifiez le répertoire Data de votre binôme en faisant une recherche sur son nombre
Faites un clic droit dessus > Organiser > Ajouter un raccourci
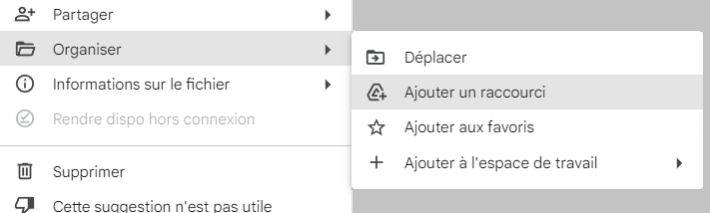
Créez le raccourci directement dans votre drive comme proposé
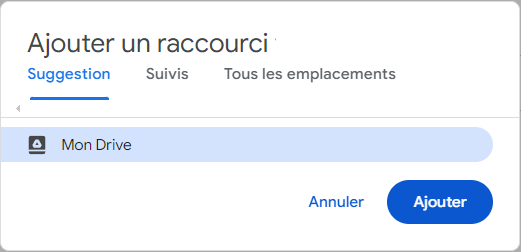
Ainsi le répertoire devient accessible en utilisant le chemin : “/content/GoogleDrive/MyDrive/Data”
Data Loader
Mise en place
Nous allons maintenant utiliser la fonction image_dataset_from_directory() de Keras qui crée un service mettant en place des batchs d’images pour le process d’apprentissage. Pour cela, il suffit de lui transmettre le chemin du répertoire contenant les images d’apprentissage :
train, valid = keras.utils.image_dataset_from_directory(
directory = '/content/data',
batch_size=64,
image_size=(64, 64),
validation_split=0.2,
subset='both',
seed = 14)
>> Found 608 files belonging to 2 classes.
>> Using 487 files for training.
>> Using 121 files for validation.
Ses différents arguments permettent de régler son comportement :
directory : correspond au répertoire qui contient les répertoires contenant les images de chaque catégorie.
batch_size : indique la taille de chaque batch lors de l’apprentissage.
image_size : la taille de l’image en entrée du réseau, keras se charge de redimensionner et découper chaque image pour former une image carrée.
validation_split : indique le pourcentage d’images à réserver pour construire le set de validation.
subset=both : indique qu’il faut construire deux ensembles : un pour l’entraînement et l’autre pour la validation.
seed : les images des différentes classes sont mélangées automatiquement. En changeant la valeur de seed, on construit un autre mélange.
Note
Les éléments retournés : train et valid, ne sont pas des listes d’images comme on l’a vu précédemment dans les notebooks. Il s’agit ici d’objets qui construisent à la demande des batchs pour le processus d’apprentissage.
Test
A titre d’exemple, affichons les images contenues dans un batch :
def ShowSamples(T):
plt.figure(figsize=(10, 10))
plt.subplots_adjust(top=1)
for images, labels in T.take(1):
for i in range(len(images)):
ax = plt.subplot(10, 10, i + 1)
plt.imshow(np.array(images[i]).astype("uint8"))
plt.title(int(labels[i]))
plt.axis("off")
ShowSamples(train)

Data Augmentation
Cette technique consiste à construire des légères variations des images en entrée pour former de nouvelles images d’apprentissage. Le plus souvent, on utilise :
une symétrie gauche / droite
une légère rotation
un léger décalage
l’ajout de bruit
Quels sont les avantages de cette approche :
Elle permet augmenter virtuellement le nombre d’images dans la base.
L’apprentissage est améliorée puisqu’on rend le réseau plus robuste face à une légère rotation / translation / dégradation de l’image.
Indirectement, on réduit le risque d’overfitting en évitant de présenter des images identiques d’une epoch à l’autre.
La mise en place est assez aisée sous Keras :
data_augmentation_layers = [
keras.layers.RandomFlip("horizontal"),
keras.layers.RandomRotation(0.1),
]
def data_augmentation(images):
for layer in data_augmentation_layers:
images = layer(images)
return images
augmented_train = train.map( lambda x, y: (data_augmentation(x), y))
L’élément augmented_train s’utilise comme le précédent :
ShowSamples(augmented_train)
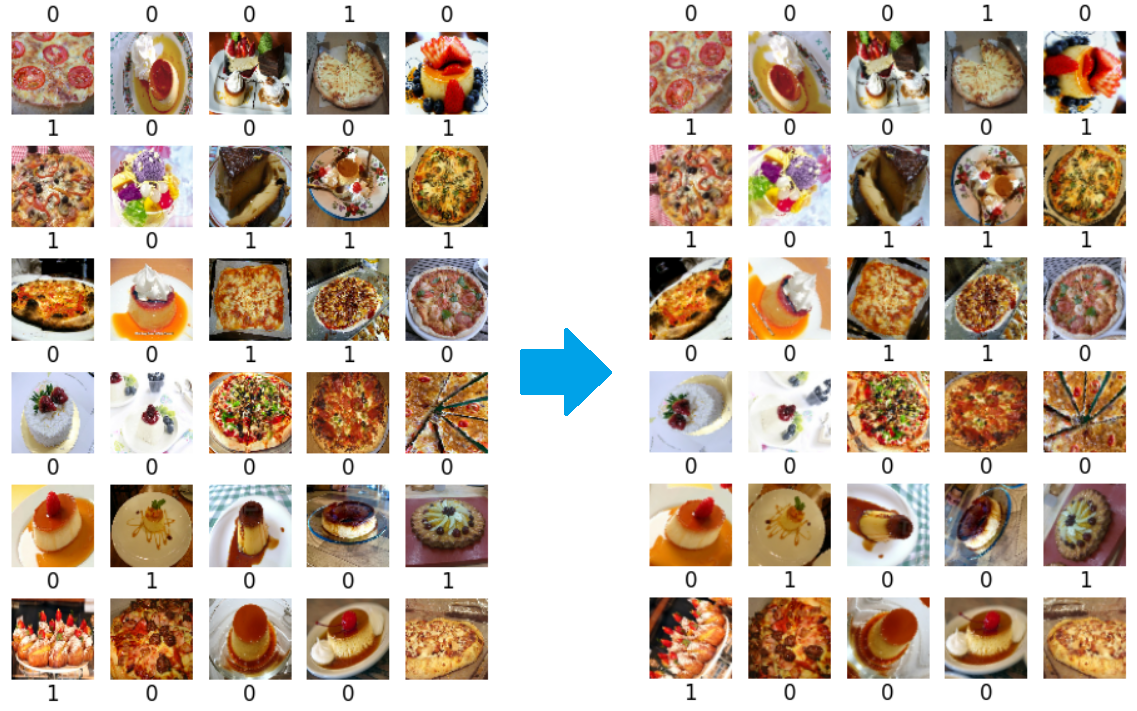
Note
Pour rendre plus visibles les rotations, nous avons choisi 0.3 comme valeur de RandomRotation. Nous avons aussi appelé à nouveau la fonction image_dataset_from_directory() pour repartir du premier batch afin de traiter les mêmes images que précédemment.
C’est parti
Étalonnage des images
A noter que nous n’avons pas effectué l’étalonnage des images, leurs valeurs restent entre 0 et 255. Quels sont nos choix :
On pourrait ajouter une étape d’étalonnage dans l’étape de data augmentation, mais comme cette étape est active uniquement durant l’entraînement et non pour les estimations, il y aurait un problème car l’étalonnage ne s’appliquerait pas sur toutes les images !
On peut effectuer l’étalonnage sur les images de la base en créant des tenseurs normalisés stockés sur le disque. On va alors construire des tenseurs en float32 ce qui va tenir 4x plus de place sur le disque.
Une option acceptable consiste à créer une couche supplémentaire dans le réseau pour effectuer cet étalonnage sur toutes les images traitées. On positionne cette couche juste après la couche d’input des données et juste avant la chaîne de traitement.
Note
Cette solution n’est pas optimale puisqu’elle va rajouter du temps de calcul mais elle évite de multiplier par 4 la taille de la base sur le disque, ce qui n’est pas négligeable.
Construire un réseau auto-étalonné
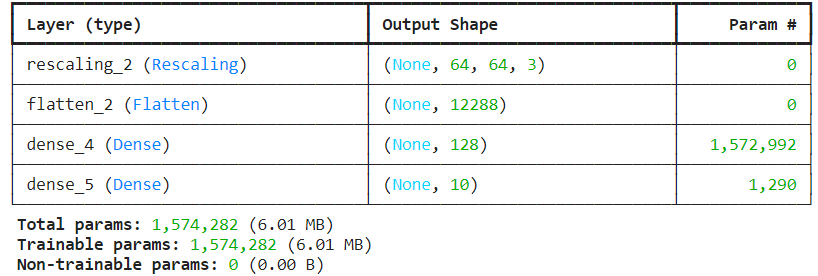
Nous utilisons un réseau basique en guise de démonstration :
model = keras.Sequential()
model.add(keras.Input(shape=(64,64,3)))
model.add(keras.layers.Rescaling(1.0 / 255)) ## couche supplémentaire pour l'étalonnage
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(128, activation="relu"))
model.add(keras.layers.Dense(10, activation="relu"))
model.summary()
model.compile(optimizer='adam',
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Apprentissage
Pour lancer la phase d’apprentissage, il suffit de transmettre au réseau le paramètre augmented_train là où précédemment on transmettait la liste d’images :
model.fit( x = augmented_train,
epochs = 10,
)
