Catalogue CNN
Dans le domaine de la classification d’images, une course à la performance s’est instaurée pour atteindre les taux d’erreur les plus faibles sur les bases existantes.
Chaque année sont produits des centaines de réseaux permettant de gagner quelques dixièmes de pourcent de précision. Cela peut aussi paraître futile mais à l’échelle de la conduite automatique, où l’algorithme peut fonctionner 8h par jour sur plusieurs jours et dans plusieurs millions de voitures, la recherche d’un taux d’erreur le plus faible possible peut se comprendre.
LeNet
La reconnaissance d’images de chiffres manuscrits est l’application la plus classique du réseau LeNet car il a été conçu pour cette raison.
En 1989, Yann LeCun et al dans les laboratoires AT&T Bell (USA). créé la forme initiale de LeNet. L’article Backpropagation Applied to Handwritten Zip Code Recognition (Neural Computation) présente ce réseau et l’applique avec succès à la reconnaissance de chiffres manuscrits de codes postaux du service postal américain.
Cependant, dans les années 90, la puissance de calcul n’est pas suffisante, et les CNN sont concurrencés par d’autres algorithmes moins gourmands, tels les SVM pouvant obtenir des résultats similaires ou supérieurs. Aujourd’hui, les réseaux CNN sont bien plus complexes, mais on retrouve dans leurs modèles les briques de base du modèle LeNet avec les couches Conv, Pool et Linear. LeNet contient 40 000 paramètres.
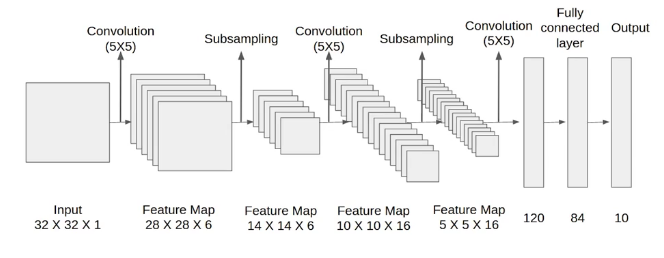
Qui se construit en Keras par le code suivant :
model = Sequential()
model.add(Conv2D(6, kernel_size=(5, 5), activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(16, kernel_size=(5, 5), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(120, activation='relu'))
model.add(Dense(84, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.summary()
Couche |
Shape |
Nb paramètres |
|---|---|---|
conv2d_4 (Conv2D) |
(24, 24, 6) |
156 |
max_pooling2d_4 (MaxPooling2D) |
(12, 12, 6) |
|
conv2d_5 (Conv2D) |
(8, 8, 16) |
2 416 |
max_pooling2d_5 (MaxPooling2D) |
(4, 4, 16) |
|
flatten_2 (Flatten) |
( 256 ) |
|
dense_6 (Dense) |
( 120 ) |
30 840 |
dense_7 (Dense) |
( 84 ) |
10 164 |
dense_8 (Dense) |
( 10 ) |
850 |
TOTAL |
44 426 |
Vous pouvez consulter le classement des meilleurs réseaux de prédiction sur la base MNIST.
ImageNet
ImageNet est une base de données de 14 millions d’images appartenant à environ 22 000 catégories. Cette base a largement contribué à faire progresser la recherche en vision par ordinateur et en apprentissage profond.
Parallèlement à l’enrichissement de cette base, s’est déroulé de 2010 à 2017 le concours ImageNet Large Scale Visual Recognition Challenge (ILSVRC). Cette épreuve utilisait une partie d’Imagenet avec environ 1000 images par catégorie pour un total de 1000 catégories.
Cet évènement permettait de classer les meilleurs algorithmes de segmentation et de classification d’images afin de de comparer les nouvelles architectures de réseaux mis en place par les équipes de recherche. Au début de la compétition, le critère de précision utilisé pour savoir si une prédiction était correcte était le Top 5 accuracy : la prédiction du réseau était considérée comme valide si parmi les 5 prédictions les plus probables se trouvait la bonne. Aujourd’hui, le critèe Top 1 accuracy permet de classer les algorithmes.
Vous pouvez consulter le classement des meilleurs réseaux de prédiction sur la base ImageNet.
Alexnet
AlexNet, réseau conçu par Alex Krizhevsky et al de l’Université de Toronto (Canada), a remporté le concours ImageNet Large Scale Visual Recognition Challenge en septembre 2012. Le réseau a obtenu une erreur de 15% creusant un écart de 10% avec les autres compétiteurs. La nouveauté d’AlexNet fut une profondeur de réseau accrue. Celui-ci nécessitait une puissance de calculs accrue pour l’apprentissage qui fut atteinte grâce à l’utilisation des GPU. AlexNet introduisit la fonction ReLU qui finit avec le temps par détrôner tanh. Ce réseau atteint 60 millions de paramètres.
Comparé avec le réseau LeNet, la première différence importante est la taille des inputs. En effet, nous sommes passés d’images en 28x28 pixels en niveaux de gris à des images en 224x224 pixels en RGB. Ainsi, la première couche Conv voit augmenter la taille de son noyau de 5x5 à 11x11. La suite du réseau consiste en un empilement de couche Conv5x5 ou Conv3x3 espacés de couches Pool . La fin du réseau Alexnet se compose de 3 couches FC comme LeNet, cependant, le nombre de neurones a été multiplié par 30, ceci afin de pouvoir gérer non plus 10 classes mais 1000 classes :
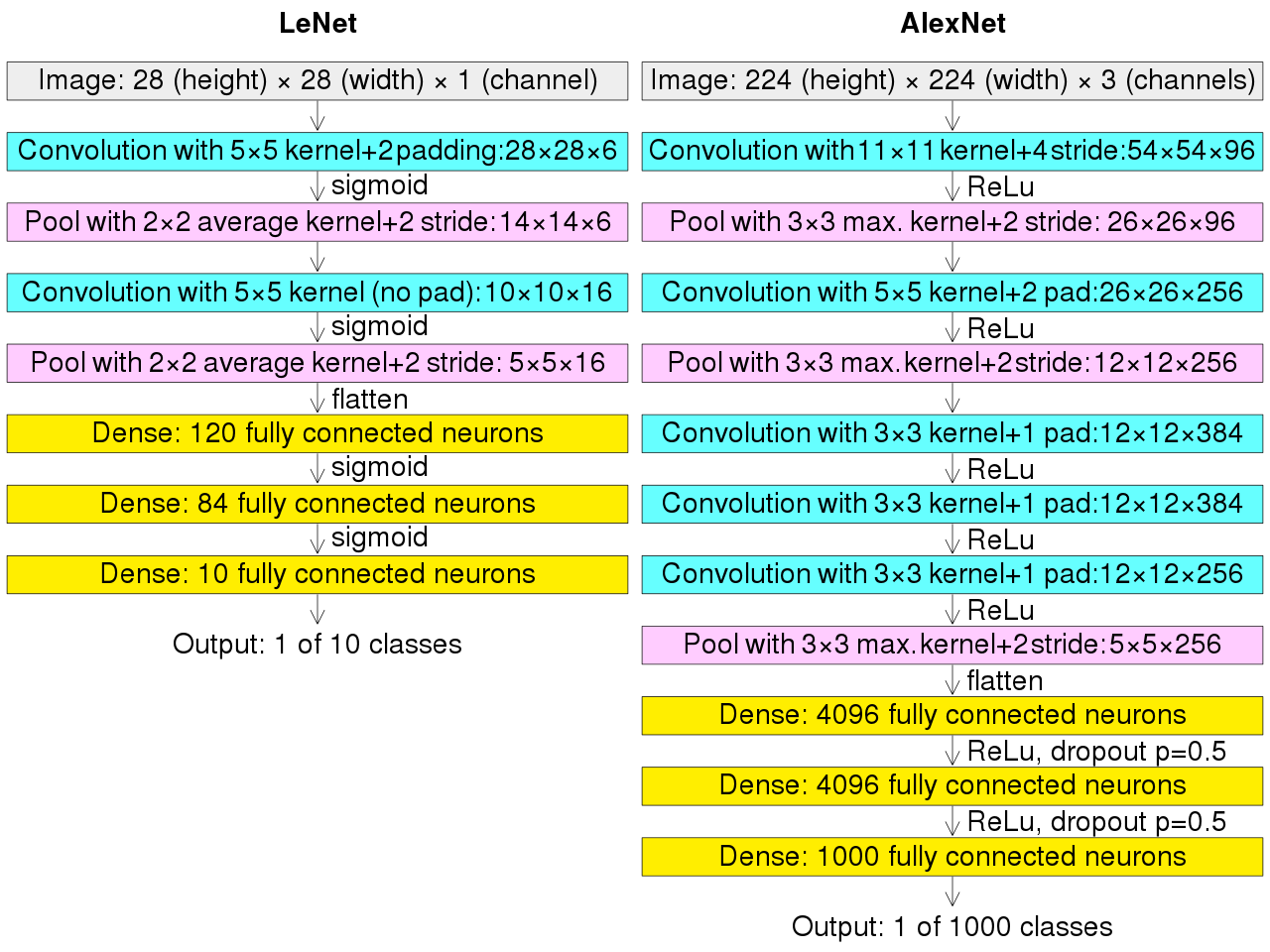
# create alexnet model in Keras with stride
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten, BatchNormalization, Conv2D, MaxPool2D
from keras.layers import Convolution2D, MaxPooling2D
# create model
model = Sequential()
model.add( Conv2D(filters=96, kernel_size=(11,11), strides=(4,4), activation='relu', input_shape=(227,227,3)) )
model.add( BatchNormalization() )
model.add( MaxPool2D(pool_size=(3,3), strides=(2,2)) )
model.add( Conv2D(filters=256, kernel_size=(5,5), strides=(1,1), activation='relu', padding="same") )
model.add( BatchNormalization() )
model.add( MaxPool2D(pool_size=(3,3), strides=(2,2)) )
model.add( Conv2D(filters=384, kernel_size=(3,3), strides=(1,1), activation='relu', padding="same") )
model.add( BatchNormalization() )
model.add( Conv2D(filters=384, kernel_size=(3,3), strides=(1,1), activation='relu', padding="same") )
model.add( BatchNormalization() )
model.add( Conv2D(filters=256, kernel_size=(3,3), strides=(1,1), activation='relu', padding="same") )
model.add( BatchNormalization() )
model.add( MaxPool2D(pool_size=(3,3), strides=(2,2)) )
model.add( Flatten() )
model.add( Dense(units=4096, activation='relu') )
model.add( Dropout(0.5) )
model.add( Dense(units=4096, activation='relu') )
model.add( Dropout(0.5) )
model.add( Dense(units=1000, activation='softmax') )
model.summary()
NB: le paramètre de stride 4x4 permet d’effectuer la convolution tous les 4 pixels et non à chaque pixel. Ainsi sur une image de 227 pixels de large et un kernel de 11 pixels, on obtient 1 + (227 - 11 )/4 = 55 convolutions en largeur.
Couche |
Shape |
Nb paramètres |
|---|---|---|
input_shape |
(227,227,3) |
|
conv2d 11x11 96 filters |
(55, 55, 96) |
34 944 |
max_pooling2d 3x3 |
(27, 27, 96) |
|
conv2d 5x5 |
(27, 27, 256) |
614 656 |
max_pooling2d 3x3 |
(13, 13, 256) |
|
conv2d 3x3 |
(13, 13, 384) |
885 120 |
conv2d 3x3 |
(13, 13, 384) |
1 327 488 |
conv2d 3x3 |
(13, 13, 256) |
884 992 |
max_pooling2d 3x3 |
(6, 6, 256) |
|
flatten |
( 9216 ) |
|
dense |
( 4096 ) |
37 752 832 |
dense |
( 4096 ) |
16 781 312 |
dense |
( 1000 ) |
4 097 000 |
TOTAL |
62 383 848 |
VGG16
VGG16 est un modèle de réseau CNN conçu par K. Simonyan et al. dans l’équipe Visual Geometry Group de l’Université d’Oxford. En 2014, ce modèle remporta la première place avec une précision de 92,7% sur ImageNet (critère top5). Le nom VGG16 provient des 16 couches qu’il contient dont 13 couches Conv suivies de 3 couches FC. Par rapport au réseau AlexNet, VGG16 a réduit la taille des noyaux assez larges 11x11 des premières couches Conv2D en les remplaçant par plusieurs couches Conv2D de noyaux 3×3 empilés. L’entraînement de VGG16 a pris plusieurs semaines et a nécessité l’utilisation de cartes NVIDIA Titan. VGG16 comporte 140 millions de paramètres.
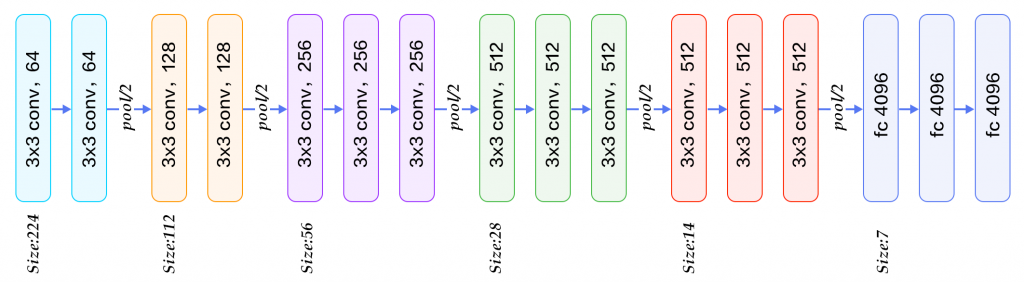
On le trouve souvent représenté sous ce format graphique :
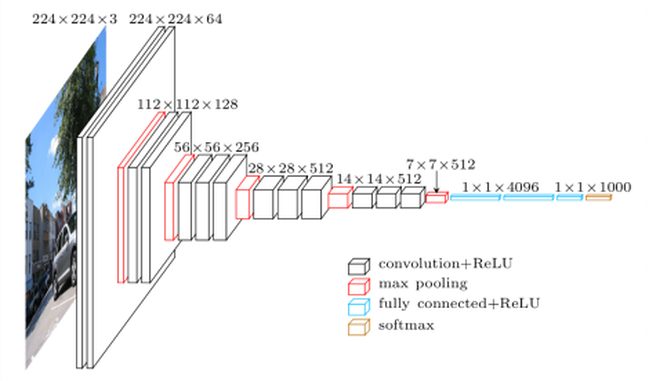
VGG16 est fourni pré-entraîné dans la librairie Keras :
# load pretrained VGG16 model from keras
from keras.applications.vgg16 import VGG16
model = VGG16()
model.summary()
Couche |
Shape |
Nb paramètres |
|---|---|---|
InputLayer |
(224, 224, 3) |
|
Conv2D 3x3 |
(224, 224, 64) |
1 792 |
Conv2D 3x3 |
(224, 224, 64) |
36 928 |
MaxPooling 2x2 |
(112, 112, 64) |
|
Conv2D 3x3 |
(112, 112, 128) |
73 856 |
Conv2D 3x3 |
(112, 112, 128) |
147 584 |
MaxPooling 2x2 |
(56, 56, 128) |
|
Conv2D 3x3 |
(56, 56, 256) |
295 168 |
Conv2D 3x3 |
(56, 56, 256) |
590 080 |
Conv2D 3x3 |
(56, 56, 256) |
590 080 |
MaxPooling 2x2 |
(28, 28, 256) |
|
Conv2D 3x3 |
(28, 28, 512) |
1 180 160 |
Conv2D 3x3 |
(28, 28, 512) |
2 359 808 |
Conv2D 3x3 |
(28, 28, 512) |
2 359 808 |
MaxPooling 2x2 |
(14, 14, 512) |
|
Conv2D 3x3 |
(14, 14, 512) |
2 359 808 |
Conv2D 3x3 |
(14, 14, 512) |
2 359 808 |
Conv2D 3x3 |
(14, 14, 512) |
2 359 808 |
MaxPooling 2x2 |
(7, 7, 512) |
|
Flatten |
( 25088 ) |
|
Dense |
( 4096 ) |
102 764 544 |
Dense |
( 4096 ) |
16 781 312 |
Dense |
( 1000 ) |
4 097 000 |
TOTAL |
138 357 544 |
GoogLeNet
Parallèlement à VVG16, en 2014, a été présenté le réseau GoogLeNet par plusieurs chercheurs de Google qui introduisirent un module spécial appelé Inception. Les chercheurs ont remarqué que construire un réseau consistait à choisir précisément quelle couche empiler et avec quelles caractéristiques. En effet, le corps du réseau est composé d’un mélange de couches Conv ou MaxPool2D et pour chaque couche Conv, il faut déterminer la taille de son noyau : 3x3, 5x5… L’idée derrière le module Inception est de ne plus avoir à gérer cette question et de laisser l’algorithme d’apprentissage choisir lui-même. Pour cela, le module Inception permet d’effectuer plusieurs tâches en parallèle : une convolution 3x3 (en largeur), une convolution 1x1 (en profondeur) et un MaxPooling2D en concaténant les résultats de ces trois fonctions dans un unique tenseur de sortie. Cette idée très intéressante s’avère cependant gourmande en paramètres. Les auteurs ont donc décidé d’associer des convolutions 1x1 à chaque fonction pour limiter la quantité de paramètres par module. Ainsi apparaît la brique de base nommée Inception :
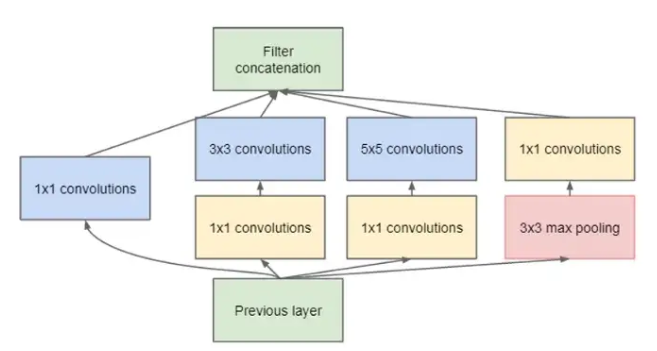
Comme ce module est sensé permettre à l’algorithme d’apprentissage de choisir quelle fonction activer à chaque couche, il reste pour construire le réseau complet à empiler plusieurs fois ce module, ainsi se construit le réseau GoogLeNet par imbrications de 9 modules Inception :
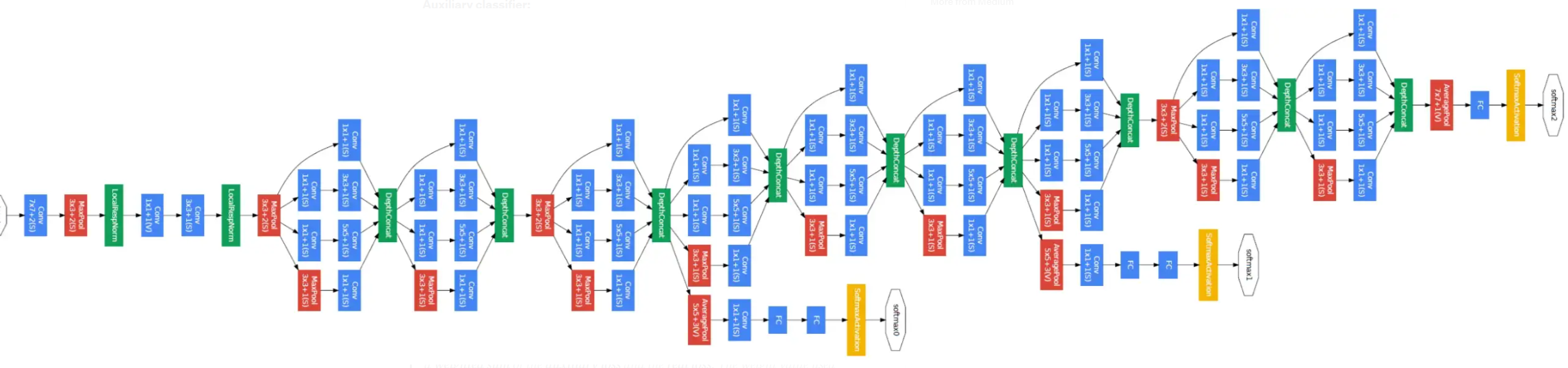
GoogleNet totalise 7 millions de paramètres d’apprentissage ce qui représente une grande économie par rapport à VGG16 qui en contenait 140 millions.
La version InceptionV3 de 2017 est disponible préentrainée sous Keras. Pour information, elle contient 26 millions de paramètres.
from tensorflow.keras.applications.inception_v3 import InceptionV3
model = InceptionV3(weights='imagenet')
Resnet
En 2015, Kaiming He et al. de Microsoft Research ont atteint d’excellentes performances sur ImageNet avec les réseaux résiduels (Residual Network or ResNet). Les réseaux profonds sont confrontés à deux problèmes importants :
Vanishing gradient : dans certains cas, notamment lorsque plus de couches sont présentes, le gradient des couches inférieures se compose de valeurs infimes qui empêchent les paramètres de ces couches d’évoluer de manière significatives.
Accuracy saturation : ajouter plus de couches à un modèle fonctionnel produit un réseau avec une erreur plus importante.
Pour contrecarrer ces problèmes, ResNet met en place entre les couches des raccourcis qui permettent à l’information de l’étage n-2 d’atteindre directement l’étage n en se recombinant avec la sortie de l’étage n-1 :
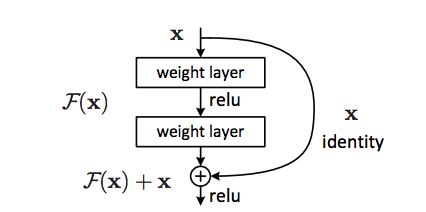
Les défauts induits par l’utilisation de trop nombreuses couches ayant diminué, on peut maintenant se permettre d’augmenter le nombre de couches dans le réseau. Voici une comparaison entre VGG16 et l’architecture ResNet34 avec les raccourcis symbolisés par des flèches :
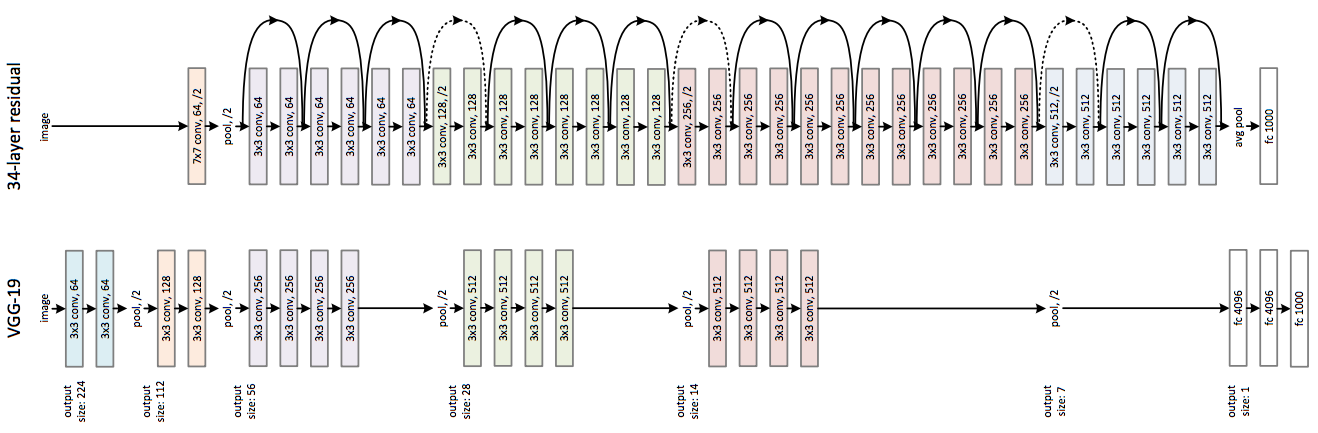
Suite à cette découverte, la profondeur des réseaux a dépassé rapidement une centaine de couches pour atteindre aujourd’hui jusqu’à 500 couches.
Dans Keras, le modèle ResNet50 est disponible et préentrainé :
from tensorflow.keras.applications.resnet50 import ResNet50
model = ResNet50(weights='imagenet')
Pour information, ResNet50 contient 25 millions de paramètres ce qui représente une économie par rapport aux 140 millions de paramètres de VGG16.
Keras pretrained models
La documentation de Keras présente la liste complète des modèles disponibles sous Keras ainsi que leurs performances relatives, leurs nombres de paramètres ou encore leurs nombres de couches.