DataSet
Torchvision
Contexte
PyTorch est une librairie de calcul tensoriel (autograd, layer, optimiseurs…), elle reste une librairie généraliste et n’est pas spécifiquement orientée vers une thématique particulière comme l’images, le texte, l’audio ou la finance…
La librairie torchvision est une librairie dédiée à la vision par ordinateur. Elle repose sur PyTorch, mais ajoute tout ce qui est spécifique aux images :
des datasets standards (MNIST, CIFAR, Oxford Pets, etc.)
des transformations : redimensionnement, normalisation, data augmentation
des modèles pré-entraînés (ResNet, VGG, MobileNet, etc)
des outils d’entrée/sortie pour les images (via PIL)
Datasets
Le module datasets de la librairie torchvision contient de nombreux jeux de données. Chaque jeu de données fournit sa propre fonction d’accès décrite dans la documentation . Nous nous intéressons à Oxford-IIIT Pets qui propose 37 classes en couleur de chats et de chiens.
import torch
from torchvision import datasets
train = datasets.OxfordIIITPet(root="data", split="trainval", download=True)
print(len(train)) # 3680
image, label = train[0] # accès à la première image du set
print(type(image)) # PIL.Image
Les bases d’images provenant de torchvision.Datasets fournissent tous les mêmes facilités :
Une fonction len qui indique le nombre d’images
L’indexation : la syntaxe train[0] retourne une image avec son label
L’image retournée est de type PIL.Image, PIL étant une librairie Python très répandue pour la manipulation d’images
Ainsi, l’objet train sert d’interface entre les données brutes stockées sur disque et l’algorithme d’apprentissage. Pour information :
print(image.size) # (394, 500)
print(image.mode) # RGB
print(type(label)) # int
Les images disponibles ont une résolution bien plus élevée que celles de MNIST (28×28), elles sont en couleur (trois canaux RGB) et leurs labels sont représentés sous la forme d’entiers.
Note
Pourquoi partir de données raw, les convertir en PIL.Image, puis les reconvertir ensuite en données raw pour les injecter dans le réseau ? Ce détour permet d’utiliser la librairie PIL afin d’appliquer des transformations (rotation, recadrage, miroir, etc.) sur les images. En ajoutant des variations aléatoires, on peut ainsi réaliser de la data augmentation (voir chap. avancé).
Exemples
On ne peut pas s’en priver, voici quelques images choisies au hasard.
import random
import matplotlib.pyplot as plt
def randomShow(DS,classNames):
nx,ny = 7,4
indices = random.sample(range(len(DS)), nx*ny)
plt.figure(figsize=(2*nx, 2*ny))
for i, idx in enumerate(indices):
img, label = DS[idx]
plt.subplot(ny, nx, i + 1)
plt.imshow(img)
plt.title(classNames[label], fontsize=12)
plt.axis("off")
plt.tight_layout()
plt.show()
classes = ["Abyssinian","american_bulldog","american_pit_bull_terrier","basset_hound","beagle","Bengal","Birman","Bombay",
"boxer","British_Shorthair","chihuahua","Egyptian_Mau","english_cocker_spaniel","english_setter","german_shorthaired","great_pyrenees","havanese",
"japanese_chin","keeshond","leonberger","Maine_Coon","miniature_pinscher","newfoundland","Persian","pomeranian","pug","Ragdoll","Russian_Blue",
"saint_bernard","samoyed","scottish_terrier","shiba_inu","Siamese","Sphynx","staffordshire_bull_terrier","wheaten_terrier","yorkshire_terrier"]
import torch
from torchvision import datasets
train = datasets.OxfordIIITPet(root="data", split="trainval", download=True)
randomShow(train,classes)
On remarque que les noms des classes ne sont pas fournis, il faut donc les donner explicitement. Par ailleurs, les images présentent des formats variés : certaines sont en mode paysage, d’autres en mode portrait.

Pipeline de validation
Les modèles nécessitant des entrées de taille fixe, nous devons appliquer des transformations aux images pour obtenir une résolution finale de 128×128 pixels. Pour le set de validation, les transformations suivantes sont appliquées :
Resize + CenterCrop
Cette approche consiste à redimensionner l’image telle que la longueur du petit coté corresponde à la taille désirée. L’image étant rectangulaire, elle est ensuite cropée (découpée) en son centre pour obtenir un carré, les bords étant perdus. L’avantage de cette approche est qu’elle maintient les proportions et qu’une grande partie du sujet est conservée.
import torch
from torchvision import datasets, transforms
s = 128
T = transforms.Compose([ transforms.Resize(s), transforms.CenterCrop(s) ])
train = datasets.OxfordIIITPet(root="data", split="trainval", download=True, transform= T )
randomShow(train,classes)

Vous remarquerez que, sur certaines images, des sujets ont le haut de la tête tronqué ou la queue coupée.
Note
Vous pourrez croiser une approche plus basique qui consiste à étirer l’image originale vers un format carré : transforms.Resize((128, 128)). Cette approche, qui modifie les proportions, reste possible dans certains cas :
prototypage rapide
besoin de rapidité
images déjà carrées ou de même ratio
Cette approche est aujourd’hui moins utilisée en classification moderne.
ToTensor
Les données correspondant à des images PIL, il faut maintenant les convertir en tenseur PyTorch avec la transformation :
transforms.ToTensor() |
Les images PIL étant 8 bits, ToTensor applique une division par 255, pour ramener les valeurs dans l’intervalle [0,1].
Examions le résultat :
from torchvision import datasets, transforms
toDo = transforms.Compose( [ transforms.Resize(128), transforms.CenterCrop(128), transforms.ToTensor() ] )
train = datasets.OxfordIIITPet( root="data", split="trainval", download=True, transform = toDo )
data,cat = train[0]
print(type(data)) # <class 'torch.Tensor'>
print(data.shape) # torch.Size([3, 128, 128])
Normalisation
Principe
Prenons l’exemple d’une image de faune marine, on obtient typiquement un histogramme de cette forme :
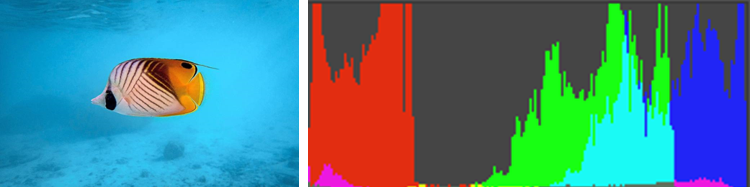
Sur cet histogramme, les rouges sont dans la zone 0% à 20% ce qui est normal car ils sont peu présents. Les bleus sont évidemment très présents et lumineux, ils sont donc placés dans les hautes valeurs entre 70% et 100%. La présence de vert dans les hautes valeurs peut surprendre, mais la couleur du fond marin tire sur un bleu cyan RGB(38, 196, 236) ce qui correspond au profil de l’histogramme ci-dessus.
La normalisation consiste à ramener les valeurs des données sur une échelle commune, généralement en centrant chaque canal R,V,B autour de zéro et en ajustant son écart-type à 1. Cette préparation permet au réseau d’apprendre plus efficacement, sans perdre de temps à compenser des échelles mal adaptées.
Calcul
Pour pouvoir appliquer cette normalisation, il faut connaître la couleur moyenne des images du dataset. Soit vous utilisez un dataset officiel et vous pourrez trouver ces valeurs sur le net, soit il faudra le calculer vous-mêmes. Pour éviter de donner plus de poids aux images haute-résolution, il faut effectuer cette estimation sur les images fournies par la DataLoader standard (images au format carré).
Avertissement
Il est recommandé de faire ce calcul une seule fois car il prend du temps. Ensuite, les valeurs trouvées sont recopiées en dur dans le programme.
import torch
from torchvision import datasets, transforms
# Dataset
transform = transforms.Compose([transforms.Resize(128), transforms.CenterCrop(128), transforms.ToTensor()])
ds = datasets.OxfordIIITPet(root="data",split="trainval",download=True,transform=transform)
# Calcul du mean et du std par canal
mean = torch.zeros(3)
std = torch.zeros(3)
for img, _ in ds:
img = img.view(3, -1) # (3, 128, 128) => (3, 16384)
mean += img.mean(dim=1)
std += img.std(dim=1) # approx : moyenne des std
n = len(ds)
print("Mean :", mean / n)
print("Std :", std / n)
>> Mean : tensor([0.4827, 0.4472, 0.3974])
>> Std : tensor([0.2238, 0.2210, 0.2222])
Les puristes remarqueront que nous avons pris une moyenne des écarts-types, ce qui constitue une bonne estimation de l’écart-type global.
Conclusion
Toute image du set de validation injectée dans le réseau, doit suivre le pipeline suivant :
Resize + crop : format carré |
ToTensor : Image PIL => tenseur |
Normalize : recentre les valeurs |
Ainsi, nous avons :
Astuce
Snippet de code pour les transformations du pipeline de validation
mean = [0.4827, 0.4472, 0.3974]
std = [0.2238, 0.2210, 0.2222]
T_validation = transforms.Compose([transforms.Resize(128),
transforms.CenterCrop(128),
transforms.ToTensor(),
transforms.Normalize(mean=mean,std=std) ])
Pipeline de train : Data Augmentation
Pour l’apprentissage, la data augmentation est utilisée pour enrichir artificiellement un jeu de données en appliquant des transformations aux images existantes (rotations, translations, bruit, etc.), notamment lorsque le nombre d’échantillons disponibles est limité. Elle permet ainsi de réduire le surapprentissage et d’améliorer la capacité de généralisation du modèle sans avoir à collecter de nouvelles données. Cette technique est appliquée uniquement sur le set de train, pas sur celui de validation.
Redimensionnement
Resize + pad
Cette approche consiste à réduire l’image afin que son plus grand côté corresponde à la longueur désirée. L’espace manquant pour obtenir une image carrée est ajouté en créant des bords noirs (padding). Cette technique n’est généralement pas utilisée en classification mais très présente en détection d’objets (YOLO), en OCR, ou encore dans le médical ; car elle évite de couper les bounding boxes ou le texte. Nous la présentons ici à titre de culture générale.

RandomResizedCrop
Cette approche consiste à choisir aléatoirement une zone dans l’image et à la redimensionner vers la taille voulue. Il est possible de préciser 2 paramètres :
scale : spécifie le % min/max de la surface de l’échantillon relativement à la surface de l’image originale
ratio : spécifie le ratio min/max pour le ratio H/L de l’échantillon
Pour bien comprendre cette approche, nous l’appliquons plusieurs fois à la même image :

Cette approche est LA transformation d’entraînement de ResNet, VGG, EfficientNet, MobileNet, ConvNeXt. L’objectif est d’apprendre à reconnaître un objet, même partiellement visible, ceci à différentes échelles.
HorizontalFlip
Cette approche consiste à faire une symétrie gauche/droite de l’image avec une probabilité d’une chance sur deux. Voici la syntaxe utilisée :
transforms.RandomHorizontalFlip(p=0.5) |
Dans Oxford Pets III, on classe des chiens et des chats photographiés dans des conditions réelles : debout, assis, couchés… mais toujours “à l’endroit”. Ainsi, on ne cherche pas à appliquer une symétrique verticale car cela créerait des images qui n’existent pas dans le monde réel.
RandomRotation
Il peut être utile de faire légèrement tourner l’image pour introduire un peu de variation en utilisant la transformation :
transforms.RandomRotation(10, interpolation=transforms.InterpolationMode.BICUBIC) |
Le paramètre donné correspond à l’angle maximum exprimé en degrés.
Voici quelques exemples :

ColorJitter
ColorJitter améliore la robustesse du modèle en modifiant aléatoirement la luminosité, le contraste, la saturation et la teinte afin de simuler des conditions d’éclairage variées. Voici ses paramètres :
brightness : variation aléatoire de la luminosité, facteur multiplicatif autour de 1 (ex. 0.2 → luminosité dans [0.8, 1.2])
contrast : variation aléatoire du contraste, idem
saturation : variation aléatoire de l’intensité des couleurs, idem
hue : léger décalage aléatoire de la teinte (couleur dominante), valeur dans [−0.5,0.5] correspondant à une fraction du cercle des couleurs
transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0) |
Voici quelques exemples :

Avertissement
Attention aux valeurs données, si elles sont grandes, les images générées peuvent devenir psychédéliques !

Conclusion
Astuce
Snippet de code pour les transformations du pipeline de validation avec Data Augmentation
mean = [0.4827, 0.4472, 0.3974]
std = [0.2238, 0.2210, 0.2222]
T_train = transforms.Compose([
transforms.RandomResizedCrop(128, scale=(0.8, 1.0)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomRotation(10),
transforms.ColorJitter(0.1, 0.1, 0.1, 0.05),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std),
])
Datasets : Train & Valid
Pour rappel, on doit mettre en place deux datasets distincts pour l’entraînement :
Un dataset de train : utilisée pour faire évoluer les poids du réseau
Un dataset de validation : utilisée uniquement pour évaluer les performances du réseau sur des données qu’il n’a jamais utilisées pour calculer son gradient.

La base d’images OxfordIIITPet met à disposition un seul lot d’images pour le train et le valid. Il faut donc mettre en place une astuce pour gérer deux pipelines distincts construits sur un même lot d’images.
L’astuce consiste à :
Créer une liste d’index pour l’ensemble des images
Créer une partition de ces index ce qui équivaut à créer une partition train/valid des images
Créer une classe dérivée de la classe Dataset pour gérer chaque partition
Ainsi, chaque image va apparaître une seule fois : soit dans le set de train, soit dans le set de validation.
class SubDataset(torch.utils.data.Dataset):
def __init__(self, base_dataset, indices, transform=None):
self.base_dataset = base_dataset
self.indices = indices
self.transform = transform
def __len__(self):
return len(self.indices)
def __getitem__(self, i):
x, y = self.base_dataset[self.indices[i]]
if self.transform:
x = self.transform(x)
return x, y
Note
Avec cette méthode le jeu de données d’origine est chargée une seule fois en mémoire.
Code
Voici la fonction générique permettant de charger les datasets PyTorch que nous utilisons par la suite.
Astuce
Snippet de code pour la création des datasets de train et de valid
import torch
from torchvision import datasets, transforms
from torch.utils.data import random_split
from torch.utils.data import Subset
class SubDataset(torch.utils.data.Dataset):
def __init__(self, base_dataset, indices, transform=None):
self.base_dataset = base_dataset
self.indices = indices
self.transform = transform
def __len__(self):
return len(self.indices)
def __getitem__(self, i):
x, y = self.base_dataset[self.indices[i]]
if self.transform:
x = self.transform(x)
return x, y
def LoadDS(dataset, transform_train, transform_valid, split=0.8) :
nb = len(dataset)
n_train = int(split * nb)
g = torch.Generator().manual_seed(0)
idx = torch.randperm(nb, generator=g).tolist()
train_idx = idx[:n_train]
val_idx = idx[n_train:]
train_ds = SubDataset(dataset, train_idx, transform_train) # 80% des images
val_ds = SubDataset(dataset, val_idx, transform_valid) # 20% des images
print("Dataset LOADED")
return train_ds, val_ds
Pour des raisons pédagogiques, nous fixons le seed à 0 pour obtenir la même partition d’un run à l’autre. Ainsi vous obtiendrez des résultats similaires entre deux sessions.
Test
Vous pouvez charger la pluspart des datasets du cours en lançant le code suivant :
T = transforms.Compose([transforms.ToTensor() ])
DS = [ datasets.MNIST, # 11 Mo
datasets.FashionMNIST, # 29 Mo
datasets.EuroSAT, # 92 Mo
datasets.CIFAR10, # 177 Mo
datasets.CIFAR100, # 181 Mo
datasets.OxfordIIITPet # 774 Mo
]
for current_dataset in DS :
dataset = current_dataset("\.data",download=True, transform=None)
train_ds, val_ds = LoadDS(dataset,T,T)
print(f"{current_dataset.__name__:<16}{len(train_ds):>8}{len(val_ds):>8}")
>> MNIST 48000 12000
>> FashionMNIST 48000 12000
>> EuroSAT 21600 5400
>> CIFAR10 40000 10000
>> CIFAR100 40000 10000
>> OxfordIIITPet 2944 736
Base d’images
Si vous avez un répertoire avec tous vos fichiers images, il est possible de créer une classe dataset à partir de ces fichiers grâce à la fonction suivante :
Astuce
Snippet de code pour la création d’un dataset relatif à un répertoire d’images
from pathlib import Path
from PIL import Image
from torch.utils.data import Dataset
from torchvision import transforms
class ImageOnlyDataset(Dataset):
def __init__(self, root, transform=None):
self.files = sorted(Path(root).glob("*.jpg"))
self.transform = transform
def __len__(self):
return len(self.files)
def __getitem__(self, idx):
img = Image.open(self.files[idx]).convert("RGB")
if self.transform:
img = self.transform(img)
return img
Dataset : Test
Dans les librairies Torchvision, il existe aussi une base de Test qui permet de comparer différents réseaux pour un concours. Elle permet ainsi d’évaluer les réseaux sur cette base constituée d’images jamais utilisées dans le processus d’apprentissage.
Pourquoi cela ? En fait, lorsque l’on entraîne plusieurs fois le réseau, on examine ses performances sur la base de validation. Le problème est que l’on finit par sur-tester car indirectement, on modifie à chaque fois les hyperparamètres afin d’améliorer l’accuracy sur la base de validation. Ce geste n’est pas anodin et il représente un surapprentissage manuel.
La base de test permet donc une vérification finale, sur des données que ni le modèle ni les développeurs n’ont utilisées, afin d’estimer la performance réelle des réseaux.
L’utilisation de cette base est HORS PROGRAMME.