Session 2 : Transfer Learning
Objectif : Mettre en œuvre le transfer learning en réutilisant un backbone pré-entraîné dans le cadre d’un problème de classification d’images.
Choix du dataset
Nous ne retenons pas CIFAR-10 pour cette étude.
En effet :
La résolution des images (32×32) est très faible
La complexité du problème reste limitée
Des architectures légères, comme nos TinyCNN correctement optimisés, atteignent déjà des performances élevées
L’apport du transfer learning y est donc peu significatif.
Nous nous orientons vers le dataset Oxford-IIIT Pet, plus adapté pour mettre en évidence l’intérêt du transfer learning. Ce choix se justifie par plusieurs caractéristiques :
Résolution d’image plus élevée : images naturelles de grande taille
Nombre d’exemples limité par classe : ~200 images
Classes visuellement proches : races de chiens et de chats similaires
Variabilité importante : pose, éclairage, arrière-plan
Terminologie
Le backbone est la partie du réseau qui extrait les caractéristiques (apprentissage des features)
Le head est la partie finale du réseau qui transforme les features en décision (classiquement du FC)
Nous appelons Transfer learning (TL), le fait de réutiliser un modèle pré-entraîné pour une nouvelle tâche. Cette approche peut prendre deux formes :
Feature extractor : backbone complètement gelé, on entraîne uniquement la tête
Fine-tuning : on débloque certaines couches du backbone pour adapter les features à la nouvelle tâche
Deux contextes :
Feature extractor : plus simple, plus stable, plus rapide
Fine-tuning : plus puissant mais plus complexe à régler
En transfer learning, on commence toujours par l’étape de feature extraction. Le fine-tuning vient ensuite, c’est une amélioration, pas un point de départ.
Choix du modèle
Le terrain
En vision par ordinateur, le choix du modèle dépend fortement des ressources disponibles et du niveau de performance attendu. Nous allons nous concentrer sur des réseaux allant du léger au milieu de gamme, offrant un bon compromis entre performance et coût de calcul.
Par ordre croissant du nombre de paramètres :
MobileNetV2, conçu pour être léger et efficace, particulièrement adapté aux environnements contraints
ResNet18, qui reste relativement compact tout en étant discriminant
ResNet34, plus profond et donc plus riche en paramètres, offrant un meilleur compromis entre capacité et coût de calcul
ResNet50 avec une architecture plus complexe, mais nécessitant des ressources matérielles plus conséquentes
MobileNetV2 ou ResNet18
Ces deux modèles sont bien adaptés aux datasets de petite taille et offrent des performances globalement comparables en transfer learning.
Cependant, leurs propriétés diffèrent légèrement :
MobileNetV2 est une architecture légère, optimisée pour la rapidité et l’efficacité, mais avec une capacité d’analyse plus limitée
ResNet18 capture mieux les détails visuels fins
Dans le cadre de notre problématique — classification de races de chiens et de chats aux caractéristiques parfois très proches — la capacité à discriminer des différences subtiles est essentielle.
Nous retenons donc ResNet18.
Pour réduire encore la quantité de calculs, nous allons injecter des images 160x160 dans le réseau au lieu des 224x224 attendu, cela diminuant par 2 la quantité de pixels à traiter !
Phase 1 - Mise en place
Head
La tête du modèle ResNet18 a été créé ainsi :
...
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, 1000)
Nous avons déju vu avec le TinyCNN l’utilité de la couche AdaptiveAvgPool2d. Elle permet, quelle que soit la résolution des images à traiter, d’avoir un tenseur en entrée de la couche FC de taille fixe. Nous n’avons donc pas à utiliser une technique particulière pour injecter nos images 160x160 dans le réseau.
Il suffit donc de remplacer la couche FC existante par une nouvelle couche FC vierge dimensionnée pour notre nombre de classes :
import torch.nn as nn
from torchvision import models
# Chargement du modèle pré-entraîné
model = models.resnet18(weights=models.ResNet18_Weights.DEFAULT)
# Nombre de classes (Oxford Pet)
num_classes = 37
# Remplacement de la dernière couche
in_features = model.fc.in_features
model.fc = nn.Linear(in_features, num_classes)
On aurait pu écrire Linear(512, num_classes). Cependant, l’utilisation de model.fc.in_features permet de conserver un code générique, compatible avec les différentes architectures ResNet (18,34,50,101…)
Feature extraction
On conserve les features apprises et on n’entraîne uniquement le classifier FC. Ainsi, on désactive l’utilisation du gradient dans tout le modèle sauf pour le head :
# on gele toutes les couches
for param in model.parameters():
param.requires_grad = False
# on réactive uniquement la tête
for param in model.fc.parameters():
param.requires_grad = True
Dropout et BatchNorm
Il existe un point qui va s’avérer important. L’idée de l’étape de Feature Extraction est de figer le backbone. Or ce backbone contient des couches Dropout et BatchNorm qui ne sont pas désactivées par la simple application de requires_grad = False :
Les couches BatchNorm mettent à jour leurs valeurs internes à chaque batch en mode train
Les couches Dropout désactivent aléatoirement des neurones en mode train
Pour que ces couches spécifiques n’évoluent pas durant l’apprentissage, on va les forcer en mode eval.
Cependant, durant l’apprentissage, le modèle passe successivement du mode Train au mode eval. Il va donc falloir réécrire ces fonctions pour que le backbone reste tout le temps en mode eval.
Dans la libraire PyTorch, l’appel de model.eval() étant en fait redirigé vers model.train(False), nous devons donc uniquement reprogrammer la fonction train de notre modèle :
def train(self, mode: bool = True):
super().train(mode)
if mode: # mode train
self.model.eval() # fige backbone + head
self.model.fc.train(True) # on réactive head
else: # mode eval
self.model.eval() # en validation, tout est en eval
Classe
Nous regroupons toutes ces modifications au sein d’une classe pour faciliter l’utilisation de modèle :
from torchvision import models
class ResNet18FTransfer(nn.Module):
def __init__(self, num_classes: int = 37):
super().__init__()
weights = models.ResNet18_Weights.DEFAULT
self.model = models.resnet18(weights=weights)
in_features = self.model.fc.in_features
self.model.fc = nn.Linear(in_features, num_classes)
self.freeze_backbone()
def freeze_backbone(self):
for param in self.model.parameters():
param.requires_grad = False
for param in self.model.fc.parameters():
param.requires_grad = True
def train(self, mode: bool = True):
super().train(mode)
if mode: # mode train
self.model.eval() # fige backbone + head
self.model.fc.train(True) # on réactive head
else: # mode eval
self.model.eval() # en validation, tout est en eval
def forward(self, x):
return self.model(x)
Hyperparamètres
Batch size : 32
Optimiseur : Adam - LR : 10⁻³
Train / Val : train et test d’Oxford pets
Nombre epochs : 20
Loss fonction : CrossEntropyLoss
Premier run
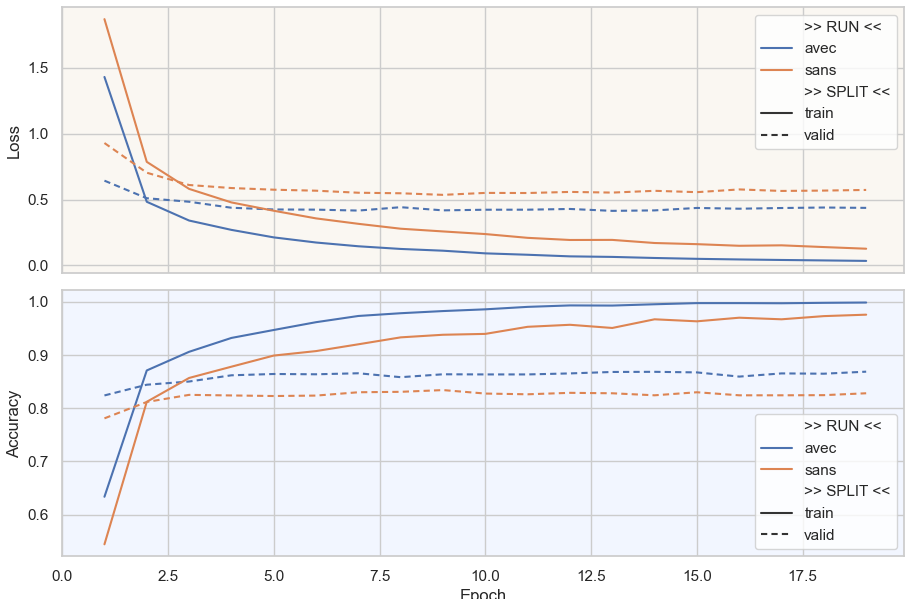
Commentaires :
La convergence est ultra rapide, quelques epochs seulement
Evidemment, le surapprentissage est au rdv
AVEC le gel des couches DropOut et BatchNorm, on atteint une performance de 87%
SANS le gel de ces couches, les performances sont moindres de 4 points
Résultats |
Métrique |
Valeur |
|---|---|---|
Transfer Learning - FC basique |
Accuracy |
0.8670 |
En conclusion, la couche FC exploite très bien et très rapidement les features de ResNet18 atteignant 87% de Accuracy/validation en seulement une douzaine d’epochs.
Note
En conclusion, pour la phase de Feature Extraction, il semble préférable de geler entièrement le backbone y compris les couches DropOut et BatchNorm.
Résolution
Est-ce qu’utiliser la résolution de 224×224 avec laquelle a été entraîné ResNet18 permet d’améliorer les performances ?
Résultats |
Métrique |
Valeur |
|---|---|---|
Transfer Learning - FC - res 224x224 |
Accuracy |
0.895 |
Utiliser la résolution d’origine apporte un gain d’environ 3 points de performance. Nous allons donc finalement travailler en 224×224.
Source
Vous pouvez télécharger le code source associé à ce projet.
Ordre habituel de progression
Comme pour le projet TinyCNN, nous conseillons — sans que cela soit obligatoire — d’effectuer les tests dans un certain ordre :
En premier lieu, optimiser le LR
Ensuite, optimiser la convergence : Scheduler,…
Puis Data Augmentation
Ensuite : Fine Tuning
Eventuellement : une longue liste de méthodes avancées
Phase 2 - Optimisation du LR
Nous testons différentes valeurs :
Learning Rate |
0.01 |
0.003 |
0.001 |
0.0003 |
0.0001 |
|---|---|---|---|---|---|
Best Accuracy |
0.866 |
0.892 |
0.893 |
0.899 |
0.900 |
Les performances restent similaires sur une grande plage de valeurs : de 3.10⁻³ à 10⁻⁴.
Note
Cette étape est optionnelle. Pour votre projet, vous pouvez utiliser directement sans justification la valeur par défaut d’Adam : LR=10⁻³ qui fonctionne très bien pour l’étape de Feature Extraction.
Amélioration
Nous faisons trois tentatives pour essayer d’améliorer les performances actuelles :
Data Augmentation
Nous utilisons les transformations déjà présentées dans la section DataSet :
T_train = transforms.Compose([
transforms.RandomResizedCrop(160, scale=(0.8, 1.0)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1, hue=0.02 ),
transforms.ToTensor(),
transforms.Normalize(mean=imagenet_mean, std=imagenet_std),
])
Amélioration de la tête
On se propose d’utiliser deux couches FC en sortie afin d’augmenter la capacité d’apprentissage de la tête
self.model.fc = nn.Sequential(
nn.Linear(in_features, 256),
nn.ReLU(),
nn.Linear(256, num_classes)
)
Scheduler
Nous choisissons un scheduler StepLR qui permet de générer 3 niveaux de LR :
Epoch 1 à 10 : 10-3
Epoch 11 à 20 : 10-4
Epoch 21 à 30 : 10-5
S.scheduler = torch.optim.lr_scheduler.StepLR(S.optimizer, step_size=10, gamma=0.1 )
Bilan
Dans les trois cas, nous obtenons des performances similaires :
Méthode |
Data Augmentation |
Scheduler |
Double FC |
|---|---|---|---|
Best Accuracy |
0.893 |
0.899 |
0.895 |
Étonnamment, l’ajout de ces trois techniques n’apporte aucun gain significatif. Les performances sont similaires, comme si ces modifications n’avaient eu aucun effet. Que peut-on supposer ?
Réponse
Dans la configuration Feature extractor, le backbone est entièrement figé. Hors, les features issues d’ImageNet ne sont pas parfaitement adaptées à notre dataset, en particulier pour des classes d’animaux visuellement proches.
Ainsi, améliorer la tête ou ajouter de la data augmentation n’apporte que peu d’effet : le modèle exploite déjà au maximum les informations disponibles. La couche de classification atteint rapidement la limite de ce qui est possible avec les informations sortant du backbone. Autrement dit, lorsque nous atteingons les 90% avec la configuration de base, nous avons déjà atteint le plafond de performance permis par ces features.
Pour aller plus loin, il est nécessaire d’adapter les représentations elles-mêmes via du fine-tuning. Sans cette étape, toute amélioration supplémentaire reste très limitée.
Resnet18
Examinons les blocs présents dans ce réseau :
for name, module in model.model.named_children():
print(name)
>> conv1
>> bn1
>> relu
>> maxpool
>> layer1
>> layer2
>> layer3
>> layer4
>> avgpool
>> fc
Entrée
On trouve ainsi une première série de couches que nous avons déjà rencontrée dans le TinyCNN :
conv1 → bn1 → relu → maxpool
Cette séquence correspond à une étape classique de traitement initial : une première convolution suivie d’une normalisation, d’une fonction d’activation, puis d’une réduction de la résolution. On retrouve ici des opérations similaires à celles utilisées dans le TinyCNN, bien que leur rôle soit ici de préparer les données avant leur traitement par les blocs résiduels.
Sortie
De la même manière, on trouve en sortie du réseau, les mêmes couches que pour le TinyCNN : avgpool → fc
Blocs intermédiaires
Dans Resnet18, on trouve ensuite quatre blocs de même structure : layer1, layer2, layer3 et layer4.
Ces blocs sont appelés blocs résiduels et reposent sur l’utilisation de skip connections. Pour comprendre ce principe, voici le code définissant ces blocs :
def forward(self, input):
out = self.conv1(input)
out = self.bn1(out)
out = F.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = out + input # skip connection
out = F.relu(out)
return out
La technique des skip connections consiste à ajouter l’entrée du bloc à sa sortie, juste avant l’application de la fonction d’activation. La couche suivante reçoit ainsi une correction des features plutôt qu’une transformation complète.
Phase 2 - Fine tuning partiel
Principe
Pour faire simple, les 4 blocs résiduels stockent des features de plus en plus haut niveau :
conv1 + layer1 : bords, textures
layer2 + layer3 : formes
layer4 : concepts spécifiques, ex: tête du chien
Pourquoi ne pas dégeler toutes les couches ? Voici les risques :
Instabilité
Surapprentissage rapide
Perte des features ImageNet
Temps de calcul ↑
Pourquoi ne dégeler que layer4 ?
Layer4 contient les features les plus spécifiques
Layer4 est proche de la sortie
Layer4 a peu de paramètres comparé au réseau entier
Le nouveau modèle
class ResNet18FTransfer(nn.Module):
def __init__(self, num_classes: int = 37):
super().__init__()
weights = models.ResNet18_Weights.DEFAULT
self.model = models.resnet18(weights=weights)
in_features = self.model.fc.in_features
self.model.fc = nn.Linear(in_features, num_classes)
self.setup_finetuning()
def setup_finetuning(self):
for param in self.model.parameters(): # Gèle tout le réseau
param.requires_grad = False
for param in self.model.fc.parameters(): # Réactive la tête de classification
param.requires_grad = True
for param in self.model.layer4.parameters(): # Réactive le dernier bloc résiduel
param.requires_grad = True
'''
def train(self, mode: bool = True):
super().train(mode)
if mode:
self.model.eval() # tout en eval par défaut
self.model.layer4.train(True) # layer4 en entraînement
self.model.fc.train(True) # tête en entraînement
else:
self.model.eval() # validation : tout en eval
return self
'''
def forward(self, x):
return self.model(x)
Deux approches existent pour le fine-tuning : soit laisser actives les couches DropOut et BatchNorm des couches inférieures, soit ne dégeler que celles de layer4. Il n’y a pas de méthode universellement meilleure : l’une peut bien fonctionner dans un cas, et moins bien dans un autre.
Note
L’approche la plus courante consiste à laisser actives toutes les couches DropOut et BatchNorm du backbone. Cet usage est effectivement à l’opposé de celui considéré dans l’étape de Feature Extraction.
Optimisation du LR
Un dilemme apparaît :
la tête du réseau (couche FC), initialisée aléatoirement, nécessite un learning rate relativement élevé pour apprendre efficacement
la couche layer4, déjà pré-entraînée, doit être ajustée avec un learning rate plus faible afin de ne pas dégrader les features acquises
Il est donc nécessaire de rechercher un LR compatible avec ces deux contraintes :
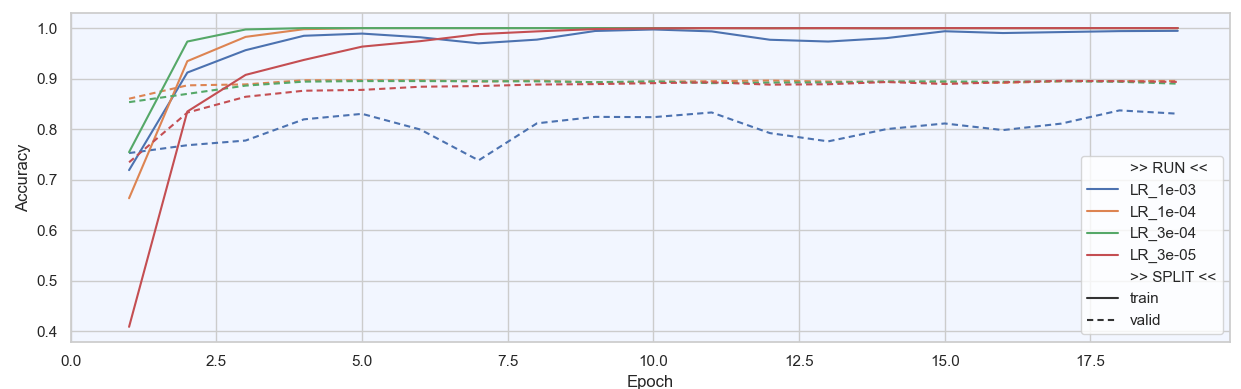
Commentaires :
On constate que le LR habituel de 10⁻³ fonctionne mal, il est trop élevé pour la couche layer4 ce qui crée de fortes oscillations et une baisse de performance.
Nous choisissons donc un LR de 10⁻⁴ qui semble convenir, ni trop haut, ni trop base
La valeur de Best Acc stagne à 90%, pas d’amélioration à ce niveau
Amélioration
L’histoire se répète, en testant plusieurs améliorations (Data Augmentation, scheduler), la Best Accuracy plafonne à 90%. Impossible de franchir ce mur, nous devons peut être accepté que nous avons atteint les performances maximales que peut offrir le modèle ResNet18. L’étape suivante va donc consister à migrer vers un modèle plus puissant.
Resnet34/50
Mise en place
Notre code étant suffisament générique, la migration se fait en changeant seulement quelques lignes :
class ResNetTransfer(nn.Module):
def __init__(self, num_classes: int = 37):
super().__init__()
weights = models.ResNet34_Weights.DEFAULT
self.model = models.resnet34(weights=weights)
in_features = self.model.fc.in_features
self.model.fc = nn.Linear(in_features, num_classes)
Modèle |
ResNet34 |
ResNet50 |
|---|---|---|
Best Accuracy |
0.915 |
0.929 |
Fine-tuning
Une fois de plus le fine tuning s’avère très difficile à mettre en place dans ce contexte.
Le problème principal reste la gestion de la couche FC et du bloc layer4 qui ne démarrent pas du même état.
Plusieurs stratégies peuvent être testées :
Optimiseur à double LR
La librairie PyTorch permet de choisir un learning rate différent pour la tête et le layer4 :
optimizer = torch.optim.Adam([
{"params": model.model.fc.parameters(), "lr": 1e-3},
{"params": model.model.layer4.parameters(), "lr": 1e-4},
], lr=1e-4)
Apprentissage en 2 phases
Cette méthode consiste à :
d’abord faire apprendre la tête comme dans l’étape de Feature Extraction
activer l’apprentissage de layer4, les deux zones apprennent maintenant avec le même LR
Conclusion
L’approche de feature extraction permet d’obtenir rapidement d’excellentes performances. Elle constitue un choix particulièrement intéressant, car elle offre des résultats bien plus rapides et bien plus simples à mettre en œuvre qu’un entraînement from scratch.
En revanche, le fine-tuning reste une étape délicate : les réglages y sont plus sensibles et souvent difficiles à mettre en place.