Session 1 : From scratch
Cette page présente la mise en œuvre d’un entraînement complet d’un réseau CNN de petite taille sur le dataset CIFAR10. Nous allons partir d’un modèle fonctionnel qui obtient un score de 72% d’accuracy et montrer comment, étape après étape nous allons améliorer ses performances pour atteindre un très bon score.
L’objectif ici est d’utiliser un petit réseau CNN pour avoir des temps d’apprentissage très faibles.
TinyCNN
Présentation
L’objectif est de proposer un réseau simple, entraînable from scratch, adapté à des images de petite taille. L’architecture que nous proposons est fondée sur l’empilement progressif de plusieurs couches ConvBlock :
class ConvBlock(nn.Sequential):
def __init__(self, c_in, c_out):
super().__init__(
nn.Conv2d(c_in, c_out, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
)
Comment fonctionne un tel bloc ? Supposons que nous ayons un tenseur en entrée de taille : [N,c_in,W,W]. La couche Conv2D avec son padding fixé à 1 augmente la résolution à W+2xW+2, ce qui après l’application de la convolution 2D amène à la résolution de départ : WxW. C’est la couche MaxPool2d qui va réduire la résolution par 2 produisant un tenseur en sortie de taille : [N,c_out,W/2,W/2]. Ainsi, à chaque bloc, la résolution est divisée par deux. Voici le modèle complet:
class TinyCNN(nn.Module):
def __init__(self, num_classes=10):
super().__init__()
# L -> L/2 -> L/4 -> L/8
self.features = nn.Sequential(
ConvBlock(3, 64), # 64 x L/2 x L/2
ConvBlock(64, 128), # 128 x L/4 x L/4
ConvBlock(128, 256), # 256 x L/8 x L/8
)
self.classifier = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)), # 256 x 1 x 1
nn.Flatten(), # 256
nn.Linear(256, num_classes) # 10
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return x
La couche AdaptiveAvgPool2d((1,1)) permet de réduire la résolution des deux dernières dimensions à (1,1). Ainsi, quelle que soit la résolution en entrée du classifieur, la couche Flatten produit toujours un tenseur de 256 valeurs.
Test
Effectuons un test pour voir si tout fonctionne correctement :
model = TinyCNN(num_classes=10)
x = torch.randn(8, 3, 32, 32)
print( model(x).shape )
>> torch.Size([8, 10])
x = torch.randn(8, 3, 256, 256)
print( model(x).shape )
>> torch.Size([8, 10])
Classifieur GAP
Si l’on traite, par exemple, des images de taille 64×64, on obtient en sortie des blocs CNN un tenseur de dimensions 256×8×8. Dans les architectures CNN des années 1990–2010, on appliquait alors une opération de Flatten, suivie d’une couche entièrement connectée. On injectait ainsi 16 384 valeurs en entrée de la couche FC, ce qui conduisait à un très grand nombre de paramètres dans le classifieur, constituant une source importante de surapprentissage.
Entre 2010 et 2015, une période transitoire a vu l’utilisation de classifieurs utilisant 2 couches FC empilées (MLP bicouche). Cette approche permettait d’augmenter la capacité d’apprentissage du modèle grâce à une plus grande non-linéarité, mais le problème du surapprentissage n’était pas résolu, car l’opération de Flatten était toujours utilisée et le nombre de neurones — et donc de paramètres — restait très élevé. Pour compenser, il était alors nécessaire de disposer de jeux de données beaucoup plus volumineux, ainsi que de techniques de régularisation telles que le dropout.
À partir de 2015, une autre approche s’est imposée pour contourner ce problème : le Global Average Pooling (GAP). Cette technique consiste à sélectionner pour chaque feature de la dernière couche Conv une seule valeur. La couche AdaptiveAvgPool2d permet ainsi d’obtenir un vecteur de taille fixe (ici 256), indépendamment de la résolution des images en entrée. Cette approche limite fortement le surapprentissage en réduisant drastiquement la quantité d’informations injectées dans la couche de classification.
Setup
Nous travaillons ici sur une base de données bien établie, utilisée depuis plusieurs décennies et largement maîtrisée. Dans ce contexte, il n’y a guère de suspense : tant que les hyperparamètres restent dans des plages raisonnables, le modèle apprend de manière stable. La convergence ne pose pas de difficulté particulière et les performances sont généralement au rendez-vous. Nous n’aurons donc pas à faire face à des situations problématiques telles qu’un sous-apprentissage (underfitting) ou une divergence incontrôlée de l’entraînement.
Data
La base CIFAR10 offre une grande quantité d’images par classe : 4000 ce qui limite les problèmes d’overfitting. Nous choisissons donc comme setup de départ de ne pas activer la data augmentation. Nous activons uniquement la normalisation des données d’entrée :
mean= (0.4914, 0.4822, 0.4465)
std = (0.2023, 0.1994, 0.2010)
T_train = transforms.Compose([ transforms.ToTensor(), transforms.Normalize(mean=mean,std=std) ])
T_valid = transforms.Compose([ transforms.ToTensor(), transforms.Normalize(mean=mean,std=std) ])
Hyperparamètres
Batch size : 32
Répartition train/val : 80/20
Réseau : TinyCNN 3 couches
Nombre epochs : 100
Loss fonction : CrossEntropyLoss
Optimiseur Adam
Source
Vous pouvez télécharger le code source associé à ce projet.
Les problèmes
La grande majorité des problèmes trouve son origine dans la phase de préparation des données. Il est donc essentiel de vérifier rigoureusement les points suivants :
Labels corrects : des labels incorrects ne provoquent aucune erreur dans le programme !
Set de train et de validation séparés : si des images du set de validation se retrouvent dans le set de train… les performances vont décoller !
Normalisation : l’oubli de cette étape ralentit la convergence
Peu d’images par classe : il faut obligatoirement utiliser de la Data Augmentation
Data augmentation sur le set de train uniquement : la Data Augmentation n’est pas activée sur le set de validation car elle génère du bruit
Phase 1 - Adam
Nous modifions la fonction CreateScenario pour qu’elle accepte une valeur de LR en argument. Ainsi, nous testons différentes valeurs pour le LR afin de déterminer la plus adaptée :
L = [ 1e-5, 1e-4, 1e-3, 1e-2, 1e-1 ]
for lr in L :
S = createScenario(lr = lr)
train(S,"__" + str(lr))
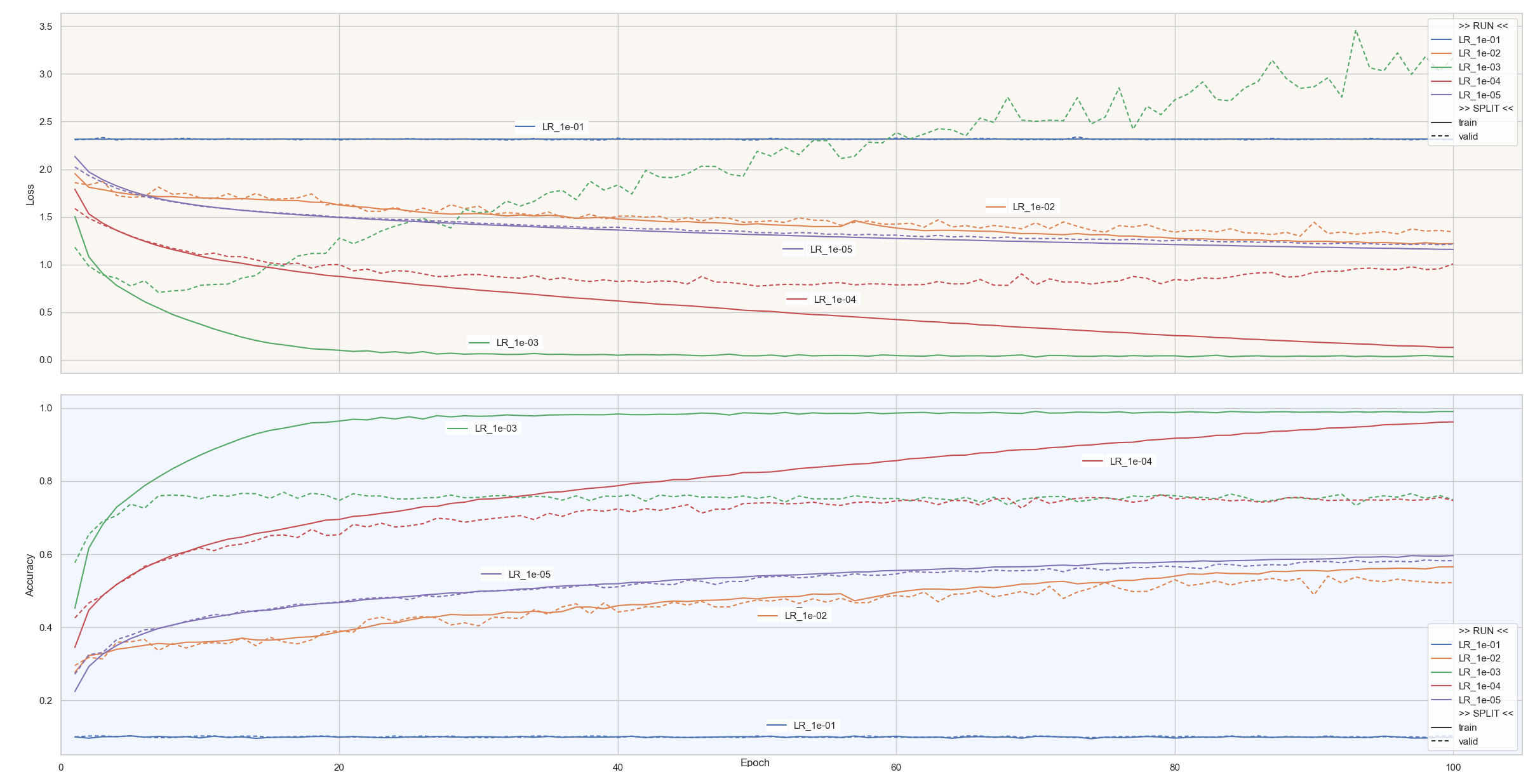
Click to enlarge.
Lecture des courbes
Le LR de 10⁻¹ semble manifestement trop élevé car aucun apprentissage n’a lieu
Le LR de 10⁻⁵ et de 10⁻² fonctionnent, mais, leur convergence reste lente
Le LR de 10⁻³ est optimal, il atteint en moins de 10 epochs son Accuracy/validation maximale aux alentours de 78%. Puis n’arrivant plus à progresser, l’overfitting s’installe.
Le LR de 10⁻⁴ est une version ralentie du 10⁻³. Il atteint la même Accuracy/validation mais il lui faudra 40 epochs.
Attention
Il ne faut pas conclure que le LR de 10⁻³ engendre davantage d’overfitting. Il est essentiel de replacer ces courbes dans leur contexte. La courbe du LR 10⁻⁴ constitue simplement une version ralentie du 10⁻³ : elle atteint la même performance plus tardivement, et présente ensuite le même comportement d’overfitting. Les courbes associées aux LR 10⁻⁵ et 10⁻² ne montrent pas d’overfitting, mais uniquement parce que l’apprentissage est encore plus lent sur ces courbes. En prolongeant l’entraînement (500 à 1000 epochs), on observerait vraisemblablement sur ces deux courbes le même scénario : une Accuracy/validation plafonnant autour de 76 %, suivie d’un surapprentissage. Il est donc essentiel de garder ce point en tête lors de l’interprétation :
La différence de dynamique entre les courbes rend leur comparaison délicate. Une convergence plus lente ne permet pas de conclure à l’absence d’overfitting, celui-ci pouvant émerger si l’entraînement était prolongé.
Conclusion
Une seule valeur de LR produit de l’underfitting
Les autres valeurs ont des comportements similaires, le LR influe surtout sur la rapidité
Le LR 10⁻³ représente le meilleur choix
Lorsque vous choisissez l’optimiseur Adam, il est recommandé de choisir en premier lieu un LR de 10⁻³.
Phase 2 - Un meilleur LR ?
Nous avons choisi des valeurs de LR espacées d’un facteur 10, ce qui représente une plage de recherche très large. La question que nous nous posons est : existe-t-il un LR pour lequel l'Accuracy/validation est vraiment meilleure ? Par curiosité, nous allons tester différentes valeurs autour de 10⁻³ :
L = [ 5e-3, 3e-3, 2e-3, 1e-3, 7e-4, 5e-4, 3e-4 ]
Voici les résultats obtenus au bout de 40 epochs :
Learning rate |
5.10⁻³ |
3.10⁻³ |
2.10⁻³ |
1.10⁻³ |
7.10⁻⁴ |
5.10⁻⁴ |
3.10⁻⁴ |
2.10⁻⁴ |
|---|---|---|---|---|---|---|---|---|
Accuracy/val |
0.613 |
0.633 |
0.696 |
0.750 |
0.753 |
0.762 |
0.766 |
0.751 |
Conclusion : Un ajustement fin du LR n’entraîne pas de gain significatif sur l'Accuracy/validation qui est le facteur de qualité permettant de classer les modèles. Il semble que la performance dépende maintenant d’autres paramètres.
Remarque : ce test confirme notre précédente règle : lorsque vous travaillez avec Adam, un LR de 10⁻³ est souvent un bon choix par défaut.
Phase 3 - SGD
Malgré la popularité d’Adam, nous allons tester l’optimiseur SGD pour voir ce que cela donne. Afin de gagner du temps, nous utilisons les valeurs des paramètres réputées comme souvent fonctionnant bien :
Lorsque vous choisissez l’optimiseur SGD, il est recommandé de choisir en premier lieu un LR de 1e-2, un momentum de 0.9 et un weight_decay de 1e-4.
Au niveau de notre programme, il nous suffit donc de changer une seule ligne :
S.optimizer = torch.optim.SGD(S.model.parameters(), lr=1e-2, momentum=0.9, weight_decay=1e-4 )
On compare les performances en Accuracy sur le graphique suivant :
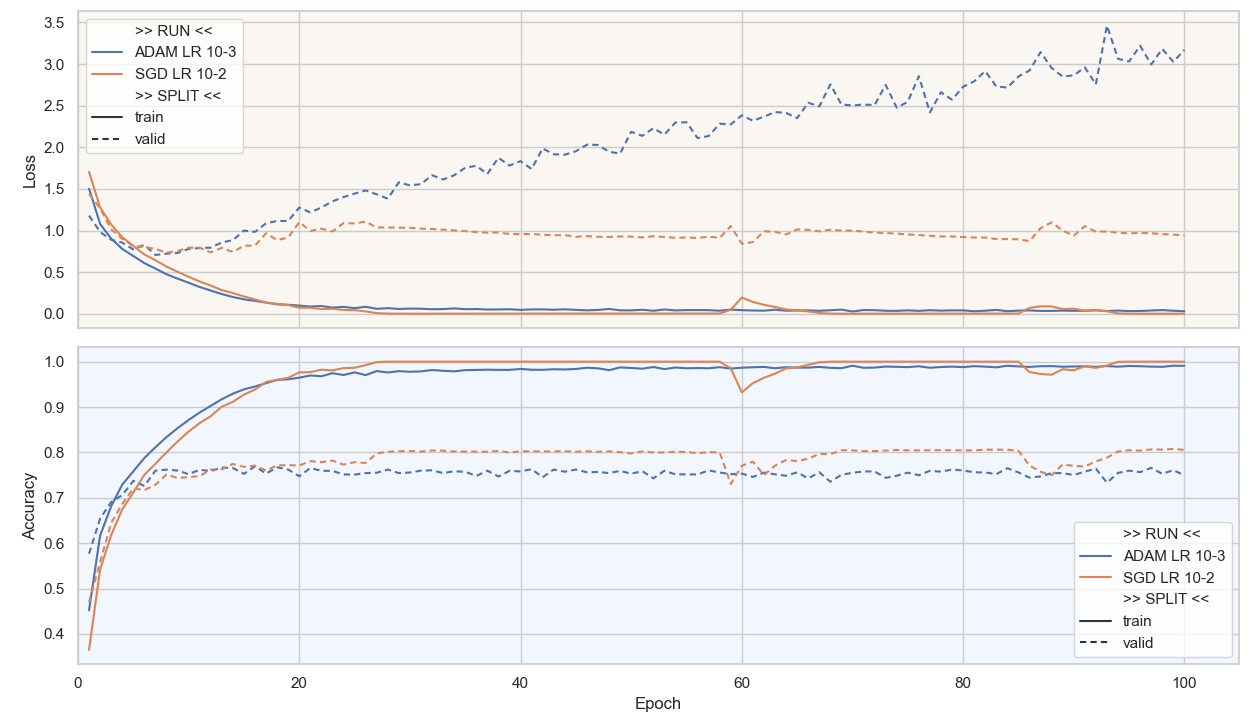
Commentaires :
Etonnamment, SGD atteint des performances bien plus hautes avec une Accuracy/validation de 80% soit 4 points de plus qu’Adam !
Adam converge vers son optimum en seulement 8 epochs contre 25 pour SGD ; on dit qu’il est « plus rapide ».
La Loss/validation d’Adam remonte progressivement et devient même franchement mauvaise ; Adam apprend vite, mais sur-apprend tout aussi vite !
La Loss/validation de SGD remonte aussi, mais reste stable, SGD contrôle mieux son surapprentissage.
Continuez au-delà de 40 epochs n’a pas d’intérêt.
Conclusion :
Adam converge souvent plus vite, mais l'Accuracy/validation peut être moindre
SGD généralise souvent mieux, obtient une meilleure Accuracy/validation, mais nécessite plus d’epochs
Nous choisissons de travailler dans la suite avec l’optimiseur SGD.
Phase 4 - BatchNorm
Arrivés à ce stade, les quelques tentatives mises en place pour améliorer les performances du réseau n’ont rien donné. Il faut être clair : nous sommes dans une impasse. Il est possible que nous ayons atteint la limite de ce que ce modèle peut offrir.
Jusqu’ici, nous n’avons pourtant rien de très original :
l’optimiseur est standard, avec un learning rate classique
le batch size est tout autant classique
la fonction d’erreur aussi
En revanche, l’architecture du réseau reste un levier important. On pourrait la modifier, par exemple en ajoutant des couches ou des mécanismes de régularisation supplémentaires. Il est probable que nous ayons atteint les limites d’un TinyCNN. Dans ce contexte, il est pertinent de demander de l’aide à un assistant IA type ChatGPT. Ces outils, entraînés sur des milliers d’articles de recherche ont une bonne vision des pratiques éprouvées.
Ici par exemple, après analyse, l’assistant suggère d’ajouter des couches de BatchNorm. D’une part, elles peuvent améliorer les performances directement, mais surtout elles permettent à d’autres mécanismes de mieux fonctionner. Nous allons donc intégrer ces couches dans le réseau. Pour cela il suffit de modifier la définition de ConvBlock :
class ConvBlock(nn.Sequential):
def __init__(self, c_in, c_out):
super().__init__(
nn.Conv2d(c_in, c_out, 3, padding=1),
nn.BatchNorm2d(c_out), ## <<<<<<<<
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
)
Résultat :
Sans BatchNorm |
Avec BatchNorm |
|
|---|---|---|
Performance |
76 % |
81 % |
Parfois l’utilisation de couches BatchNorm permet d’atteindre de meilleures performances et d’utiliser des LR plus élevés.
Phase 5 - Scheduler
Approche
Nous allons effectuer un test. Que se passe-t-il si nous choisissons durant l’apprentissage différentes valeurs de LR ? Par exemple :
Epochs |
1 à 40 |
41 à 70 |
71 à 100 |
|---|---|---|---|
Scénario 1 - LR : |
10⁻² |
10⁻³ |
10⁻⁴ |
Scénario 2 - LR : |
10⁻¹ |
10⁻² |
10⁻³ |
Mise en place
Pour mettre ce test en place, nous utilisons un scheduler qui permet de faire évoluer le LR durant l’apprentissage. Comme nos besoins sont simples, un scheduler basique comme le MultiStepLR est suffisant :
S.optimizer = torch.optim.SGD(S.model.parameters(), lr=lr, momentum=0.9, weight_decay=1e-4 )
S.scheduler = torch.optim.lr_scheduler.MultiStepLR(S.optimizer, milestones=[41, 71], gamma=0.1)
A noter que le scheduler s’applique sur l’optimiseur car il contrôle le LR de ce dernier. Le paramètre gamma est le facteur multiplicatif appliqué au LR chaque fois que l’on franchit un milestone. Il faut ensuite indiquer au scheduler que l’epoch est terminé et qu’il doit modifier le LR courant :
for epoch in range(S.epochs):
# TRAIN
S.model.train()
for x, y in S.train_batch:
...
# VALIDATION
S.model.eval()
with torch.no_grad():
...
S.scheduler.step()
Attention, il ne faut pas mettre le scheduler.step() à la suite de optimizer.step() car il serait appliqué pour chaque batch. Il faut le positionner à la fin de la boucle des epochs.
Résultats
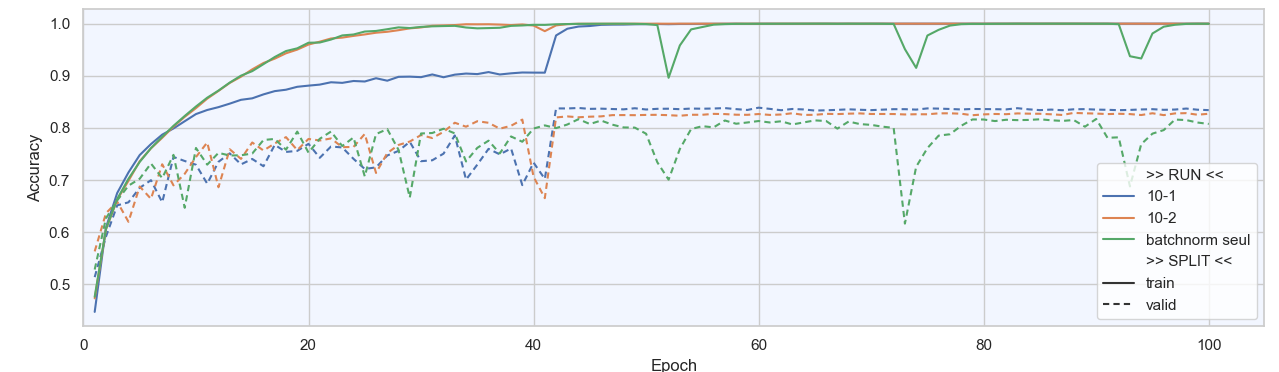
Commentaires :
Comme nous l’avons vu précédemment, l’ajout de la couche BatchNorm permet de dépasser les 80 %.
Bonne nouvelle : les entraînements avec un LR variable atteignent désormais 82 % et 84 % de performance.
Le scénario 1, basé sur les LR 10⁻², 10⁻³ et 10⁻⁴, plafonne à 82 %. L’accuracy/train ayant déjà atteint 100 %, le surapprentissage est installé, et la réduction du LR ne permet pas vraiment de corriger la situation.
Le scénario 2 est plus surprenant. Il démarre avec un LR élevé (10⁻¹), ce qui devrait en principe dégrader les performances en rendant l’entraînement plus instable. Pourtant, on observe ici un effet contre-intuitif : ce LR élevé ralentit le surapprentissage. On peut y voir une forme de régularisation. Ainsi, lorsque le LR est réduit à l’epoch 41, le modèle est encore capable d’apprendre et atteint finalement 84 % de performance.
Conclusion
L’objectif d’un scheduler est de moduler le learning rate entre le début et la fin de l’apprentissage. L’utilisation d’un scheduler permet souvent de gagner quelques points de performance. Attention, un scheduler ne corrige pas un mauvais LR initial : celui-ci doit être correctement réglé au préalable.
En contrepartie, l’entraînement est généralement plus long, car le nombre d’epochs doit être augmenté afin de tirer pleinement parti de la décroissance du learning rate.
Phase 6 - Data Augmentation
Présentation
Nous avons maintenant un modèle assez bon, mais nous devons lutter encore contre l’overfitting. Nous pouvons utiliser la Data Augmentation comme méthode de régularisation.
Nous allons tester une version utilisant uniquement le RandomHorizontalFlip puis une autre version ajoutant du RandomCrop en plus :
T_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std)
])
Résultat
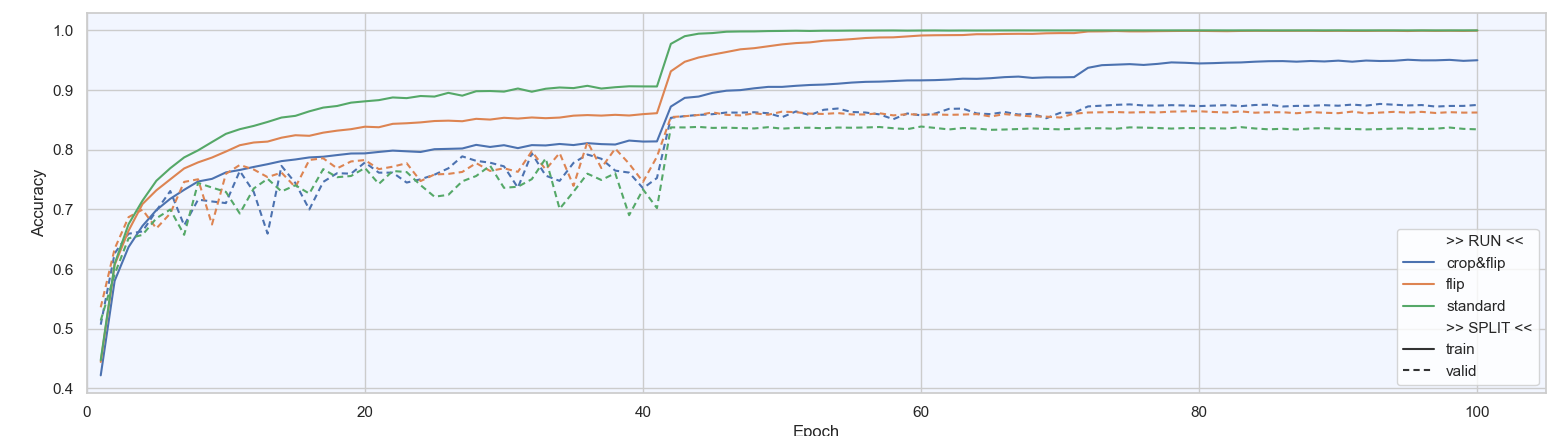
Data Augmentation |
Sans |
Flip |
RandomCrop+Flip |
|---|---|---|---|
Accuracy/validation |
83.7% |
86.3% |
87.5% |
Commentaires
Nous constatons les pics de gain de performance lorsque le LR change, à l’époch 41 et 71.
L'Accuracy/validation obtenue dans Data Augmentation était de 83.7%
L’ajout du RandomHorizontalFlip fait gagner 2.6%
L’ajout du RandomCrop + RandomHorizontalFlip fait gagner 1.2% supplémentaire
Conclusion
L’ajout de deux méthodes de Data Augmentation, même basiques, a permis de gagner quelques % de performance
Phase 7 - Better CNN
Présentation
Nous allons mettre en place un modèle avec une meilleure capacité d’apprentissage. Nous espérons qu’il atteigne de meilleures performances, au prix d’une complexité légèrement accrue. Pour cela, on améliore le ConvBlock du TinyCNN pour le rendre plus performant en empilant deux convolutions successives, chacune suivie d’une normalisation (BatchNorm). Cette architecture permet d’extraire des caractéristiques plus riches tout en stabilisant l’entraînement.
class ConvBlock(nn.Sequential):
def __init__(self, c_in, c_out):
super().__init__(
nn.Conv2d(c_in, c_out, 3, padding=1, bias=False),
nn.BatchNorm2d(c_out),
nn.ReLU(inplace=True),
nn.Conv2d(c_out, c_out, 3, padding=1, bias=False),
nn.BatchNorm2d(c_out),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
)
Résultat
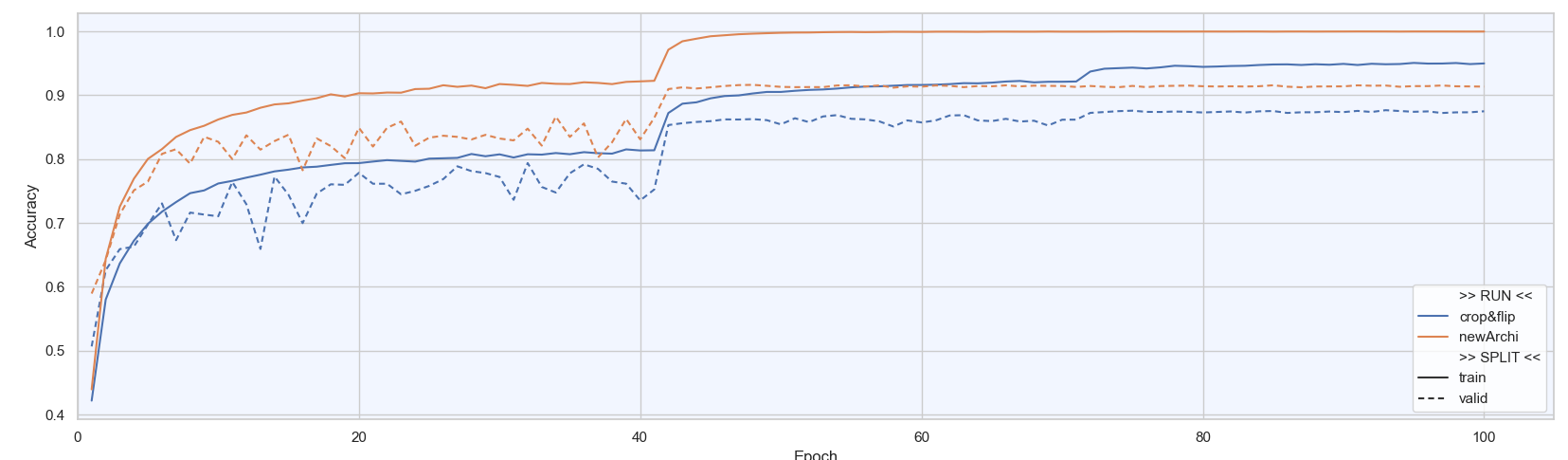
Conclusion
La nouvelle architecture de réseau a permis de gagner 4% de performance afin d’atteindre une Accuracy/validation de 91.5%.
Conclusion finale
Optimiser l’apprentissage d’un réseau de neurones est difficile :
Il n’existe pas de méthode universelle
Il faut expérimenter et comparer
L’évolution des performances peut être contre-intuitive
Modifier un paramètre peut impacter les autres
Ce que nous avons compris :
Certains schémas se répètent (par exemple, des LR typiques selon l’optimiseur)
Il est préférable d’avancer pas à pas, en modifiant un seul paramètre à la fois
Chaque amélioration apporte souvent un gain modeste
L’accumulation de plusieurs améliorations permet d’atteindre de très bonnes performances
Seule l'Accuracy/validation permet d’évaluer un modèle