Convolutional Networks (CNN)#
Traditional neural networks made of fully-connected layers are not well suited for processing structured grid data such as audio, images, or videos, because they treat the input as a one-dimensional vector. This leads to several problems: the number of inputs to the network can be very large (e.g., 1 million pixels for a 1000x1000 image), and the network does not take advantage of the patterns (edges, textures, etc.) that are naturally present in the input data.
Convolutional Neural Networks (ConvNet, CNN) are a type of neural network designed under the assumption that the inputs are images. They make use of the convolution operation to break down an image into smaller patches on which a set of trainable filters is applied. This allows the network to learn the local patterns of the input images using fewer parameters than a fully-connected network, making the forward propagation more efficient to implement and the training process less prone to overfitting.
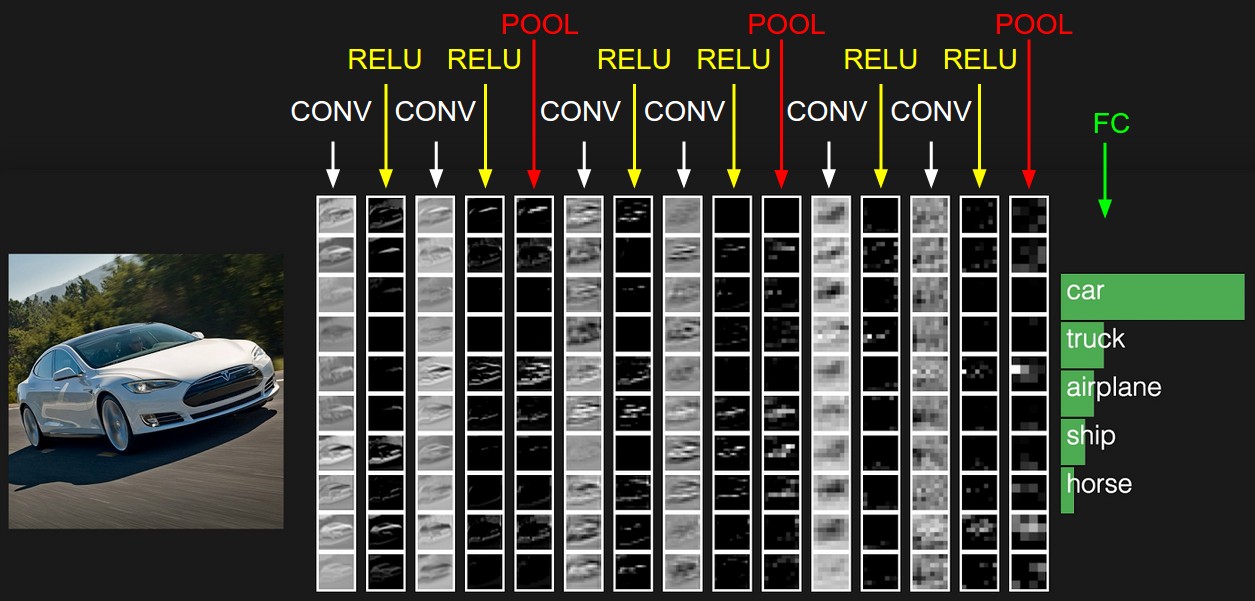
Convolutional networks mainly use three types of layers: convolutional (CONV), pooling (POOL), and fully-connected (FC). The figure below shows a concrete example of ConvNet architecture. The first layer (left) receives the raw image pixels, whereas the last layer (right) produces the class probabilities. The activation of each hidden layer along the processing path is shown as a column.
In this chapter, we will implement a simple ConvNet to classify images of handwritten digits. We will show that ConvNets can achieve better performance than fully-connected networks on this type of data.