Transfer Learning#
In a previous tutorial, we trained a CNN from scratch to classify images of cats and dogs. Despite using a relatively small training set of 20’000 images and a test set of 5’000 images, we achieved a reasonable accuracy of 80–84%. In this tutorial, we will take a look at how to improve the accuracy of our classifier by using a pre-trained network. This is a powerful and widely used technique known as transfer learning.
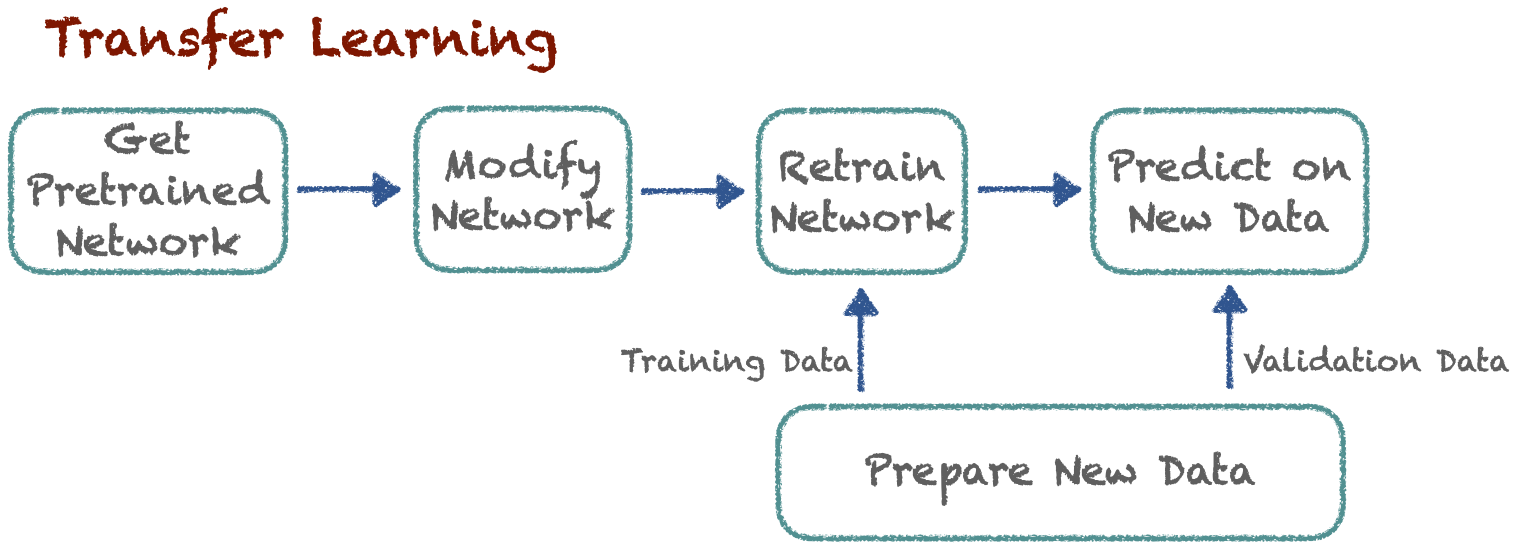
Transfer learning consists of taking a convolutional network trained on a large dataset, such as ImageNet, and reusing its convolutional backbone to extract features from a different dataset. This approach leverages the ability of convolutional networks trained on large datasets to learn generic features that are useful across a wide range of visual tasks. For example, the lower layers of a network trained on ImageNet might detect edges, textures, and simple shapes, while higher layers might capture more complex patterns like object parts or entire objects. By using these pre-trained layers as a starting point, we can significantly reduce the amount of data required to train a model on a new task.
In practice, transfer learning can be implemented in two main ways.
Feature Extraction. In this approach, the pre-trained network is used as a fixed feature extractor. The convolutional backbone of the network is frozen, and only the top layers (typically fully-connected layers) are replaced and trained on the new dataset. This method is effective when the new dataset is relatively small and similar to the dataset used for pre-training.
Fine-Tuning. This involves unfreezing some of the pre-trained layers and retraining them alongside the new layers on the target dataset. Fine-tuning allows the network to adapt its learned features to the specifics of the new task. This method is useful when the new dataset is larger or when it differs significantly from the original dataset.
We will demonstrate both methods in this chapter, using the same dataset of cats and dogs images.