Siamese Network#
A Siamese Network is a special type of neural network architecture designed to compare two inputs. The general workflow of a Siamese Network is as follows.
A pair of images is presented to the network as input.
The network processes each input separately to produce embeddings (feature vectors).
These embeddings are then compared using a similarity function or a distance metric.
A Siamese network is trained to minimize the distance between embeddings of similar inputs and maximize the distance between embeddings of dissimilar inputs. This makes the network learn the essential characteristics of the inputs that are important for the comparison. Siamese Networks are particularly useful when the amount of labeled data is limited, as they focus on relative comparisons rather than absolute classifications. Once trained, they can generalize to unseen classes without the need for retraining.
In this tutorial, we will implement a Siamese Network to compare images of handwritten digits from the MNIST dataset. We will train the network using the contrastive loss function originally proposed by Chopra, Hadsell, and LeCun in 2005.
Show code cell source
import torch
import torch.nn.functional as F
from torch import nn, optim
from torch.utils.data import DataLoader, Dataset
from torchvision.transforms import v2
from torchvision.datasets import MNIST
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
from sklearn.manifold import TSNE
Creating the network#
The first step is to define a neural network that processes the input images and produces embeddings. Generally, this network is composed of three parts.
Backbone: A series of convolutional and pooling layers to extract features from the input image.
Neck: A small number of layers to further process the extracted features into a compact representation. This typically involves a flattening layer followed by one or more fully-connected layers, nonlinear activations, and possibly batch normalization.
Head: A final set of layers to prepare the embeddings for comparison with the chosen loss function. This usually involves a normalization layer, and depending on the loss function, a fully-connected layer. As the head is only used during training, it may be included in the loss function, rather than the model itself.
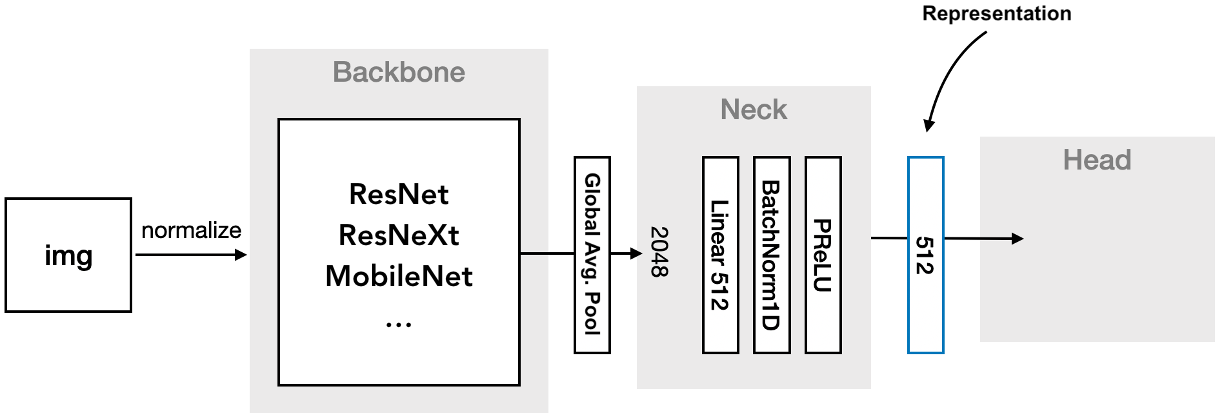
Backbone#
The backbone of the network is responsible for extracting features from the input images. It is best practice to use a pre-trained model as the backbone, since this usually improves performance and reduces the amount of training data required. For the present tutorial, however, we will build a simple backbone from scratch, made up of convolutional and pooling layers with ReLU activations.
class Backbone(nn.Sequential):
def __init__(self):
super().__init__(
nn.Conv2d(1, 64, 5, padding=2),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(64, 128, 5, padding=2),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(128, 256, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
)
Neck#
The neck of the network takes the features extracted by the backbone and processes them into a more compact representation. In this tutorial, the neck is implemented using a few fully-connected layers with ReLU activations. Before passing the data to these layers, a flatten operation is applied to convert the 3D tensor output from the backbone into a 1D tensor suitable for fully-connected processing.
class Neck(nn.Sequential):
def __init__(self, out_dim):
super().__init__(
nn.Flatten(),
nn.Linear(256 * 3 * 3, 1024),
nn.ReLU(),
nn.Linear(1024, 256),
nn.ReLU(),
nn.Linear(256, out_dim),
)
Embedding model#
The embedding model combines the backbone and the neck into a single network. Its role is to transform input images into compact vector representations commonly referred to as embeddings. These embeddings can then be compared using similarity functions or distance metrics to measure how alike two images are.
class EmbeddingNet(nn.Module):
def __init__(self, out_dim):
super().__init__()
self.backbone = Backbone()
self.neck = Neck(out_dim)
def forward(self, x):
x = self.backbone(x)
x = self.neck(x)
return x
Let’s summarize the architecture of the embedding model using the torchinfo package. We will set (1, 28, 28) as the input shape, as this is the size of the MNIST images. We will also set 50 as the output dimension of the embeddings, a somewhat arbitrary choice for this tutorial.
model = EmbeddingNet(50)
Show code cell source
from torchinfo import summary
summary(model, input_size=(1, 1, 28, 28), col_names=("input_size", "output_size"))
==========================================================================================
Layer (type:depth-idx) Input Shape Output Shape
==========================================================================================
EmbeddingNet [1, 1, 28, 28] [1, 50]
├─Backbone: 1-1 [1, 1, 28, 28] [1, 256, 3, 3]
│ └─Conv2d: 2-1 [1, 1, 28, 28] [1, 64, 28, 28]
│ └─ReLU: 2-2 [1, 64, 28, 28] [1, 64, 28, 28]
│ └─MaxPool2d: 2-3 [1, 64, 28, 28] [1, 64, 14, 14]
│ └─Conv2d: 2-4 [1, 64, 14, 14] [1, 128, 14, 14]
│ └─ReLU: 2-5 [1, 128, 14, 14] [1, 128, 14, 14]
│ └─MaxPool2d: 2-6 [1, 128, 14, 14] [1, 128, 7, 7]
│ └─Conv2d: 2-7 [1, 128, 7, 7] [1, 256, 7, 7]
│ └─ReLU: 2-8 [1, 256, 7, 7] [1, 256, 7, 7]
│ └─MaxPool2d: 2-9 [1, 256, 7, 7] [1, 256, 3, 3]
├─Neck: 1-2 [1, 256, 3, 3] [1, 50]
│ └─Flatten: 2-10 [1, 256, 3, 3] [1, 2304]
│ └─Linear: 2-11 [1, 2304] [1, 1024]
│ └─ReLU: 2-12 [1, 1024] [1, 1024]
│ └─Linear: 2-13 [1, 1024] [1, 256]
│ └─ReLU: 2-14 [1, 256] [1, 256]
│ └─Linear: 2-15 [1, 256] [1, 50]
==========================================================================================
Total params: 3,137,330
Trainable params: 3,137,330
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 58.57
==========================================================================================
Input size (MB): 0.00
Forward/backward pass size (MB): 0.71
Params size (MB): 12.55
Estimated Total Size (MB): 13.27
==========================================================================================
Contrastive loss#
Given a pair of embeddings and a binary label indicating whether the embeddings originate from similar or dissimilar inputs, the contrastive loss function is defined by the following formula.
Where:
\(z_1\) and \(z_2\) are the embeddings of a pair of inputs.
\(y\) is the binary label indicating whether the inputs are similar (\(y=1\)) or dissimilar (\(y=0\)).
\(m\) is the margin that controls how far apart the embeddings of dissimilar inputs should be.
Intuition#
The contrastive loss function is composed of two terms. Only one of these terms is active for each pair of embeddings, depending on the binary label.
Positive term. If the inputs are similar (\(y=1\)), the loss is the squared Euclidean distance between their embeddings. This term encourages the network to bring the embeddings as close together as possible.
Negative term. If the inputs are dissimilar (\(y=0\)), the loss is the squared hinge distance between their embeddings. This term encourages the network to push the embeddings apart by at least a margin \(m\). If the distance between the embeddings is already greater than the margin, the loss is zero.
The role of the margin is that, when the embeddings produced for a negative pair are distant enough, no efforts are wasted on enlarging that distance, so further training can focus on more difficult pairs.
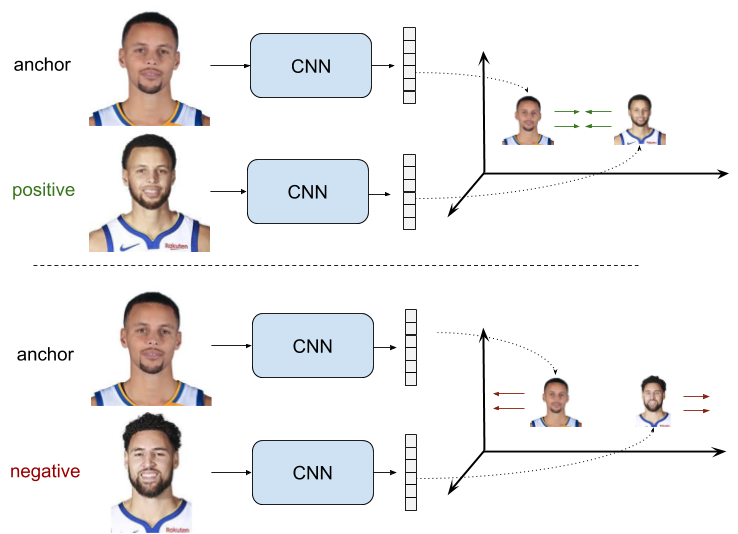
Implementation#
Let’s implement the contrastive loss function in PyTorch. The approach can vary depending on the type of labels available. In this tutorial, we assume that we have a classification dataset. Hence, we create a custom loss function that takes a batch of embeddings and their corresponding class labels as input. The loss function computes pairwise distances between embeddings, determines whether pairs belong to the same class, and applies the contrastive loss accordingly.
Helper function#
Now that we have outlined the goal of our implementation, let’s proceed with the actual coding. We start by defining an helper function that determines the positive and negative pairs in a batch. Using the masks returned by this function, we can efficiently select the relevant pairs when computing the loss.
def get_similarity_masks(labels: torch.IntTensor) -> tuple[torch.BoolTensor, torch.BoolTensor]:
"""
Args
- labels: 1D tensor containing labels
Returns
- pos_mask: 2D tensor where pos_mask[i, j] = True if labels[i] == labels[j] and i < j
- neg_mask: 2D tensor where neg_mask[i, j] = True if labels[i] != labels[j] and i < j
"""
# Matrix of pairwise comparisons
labels_equal = labels.unsqueeze(0) == labels.unsqueeze(1)
# Negative pairs
neg_mask = torch.triu(~labels_equal, diagonal=1) # Remove duplicates
# Positive pairs
pos_mask = torch.triu(labels_equal, diagonal=1) # Remove duplicates and self-comparisons
return pos_mask, neg_mask
Let’s test this function with a batch of class labels to get an idea of how it works.
labels = torch.tensor([0, 0, 1, 2, 1, 2, 2, 0, 1, 2])
pos_mask, neg_mask = get_similarity_masks(labels)
Show code cell source
def mask2pairs(mask):
return [[(i, j) for i in range(len(labels)) for j in range(len(labels)) if mask[i,j] and labels[i]==c] for c in range(max(labels)+1)]
print('Positive pairs:', *mask2pairs(pos_mask), sep='\n')
print()
print('Negative pairs:', *mask2pairs(neg_mask), sep='\n')
Positive pairs:
[(0, 1), (0, 7), (1, 7)]
[(2, 4), (2, 8), (4, 8)]
[(3, 5), (3, 6), (3, 9), (5, 6), (5, 9), (6, 9)]
Negative pairs:
[(0, 2), (0, 3), (0, 4), (0, 5), (0, 6), (0, 8), (0, 9), (1, 2), (1, 3), (1, 4), (1, 5), (1, 6), (1, 8), (1, 9), (7, 8), (7, 9)]
[(2, 3), (2, 5), (2, 6), (2, 7), (2, 9), (4, 5), (4, 6), (4, 7), (4, 9), (8, 9)]
[(3, 4), (3, 7), (3, 8), (5, 7), (5, 8), (6, 7), (6, 8)]
Loss module#
Next, we define the custom loss module that computes the contrastive loss for a batch of embeddings and class labels. The forward method executes the following steps.
Compute the pairwise distances between embeddings.
Determine the positive and negative pairs using the class labels.
Apply the contrastive loss function to the positive and negative pairs.
Return the average loss over the batch.
class ContrastiveLoss(torch.nn.Module):
def __init__(self, margin: float):
super().__init__()
self.margin = margin
def forward(self, embeddings: torch.FloatTensor, labels: torch.IntTensor):
# Compute the pairwise distances
distances = torch.cdist(embeddings, embeddings, p=2)
# Get the similarity masks
pos_mask, neg_mask = get_similarity_masks(labels)
# Compute the loss
positive_loss = distances[pos_mask].pow(2).sum()
negative_loss = F.relu(self.margin - distances[neg_mask]).pow(2).sum()
# Compute the number of positive and negative pairs
num_pairs = pos_mask.sum() + neg_mask.sum()
# Return the average loss
return (positive_loss + negative_loss) / num_pairs
Training the network#
Our implementation of the contrastive loss has the same signature of the loss functions for classification. This allows us to use the Trainer class defined in training.py file without any modification.
from training import Trainer
First, we load the MNIST dataset with a minimal preprocessing pipeline that converts images to tensors.
preprocess = v2.Compose([v2.ToImage(), v2.ToDtype(torch.float32, scale=True)])
train_ds = MNIST('.data', train=True, download=True, transform=preprocess)
test_ds = MNIST('.data', train=False, download=True, transform=preprocess)
Then, we define the model, loss function, optimizer, and data loader.
model = EmbeddingNet(50)
optimizer = optim.Adam(model.parameters(), lr=0.001)
loss_fn = ContrastiveLoss(margin=1)
loader = DataLoader(train_ds, batch_size=32, shuffle=True)
Note
The embedding size affects the quality of the embeddings produced by the Siamese network. In this tutorial, we set the embedding size to 50, since MNIST is a relatively simple dataset. A larger embedding size may be necessary for more complex datasets and tasks.
Finally, we train the model for a few epochs.
trainer = Trainer()
history = trainer.fit(model, loader, loss_fn, optimizer, epochs=5)
===== Training on mps device =====
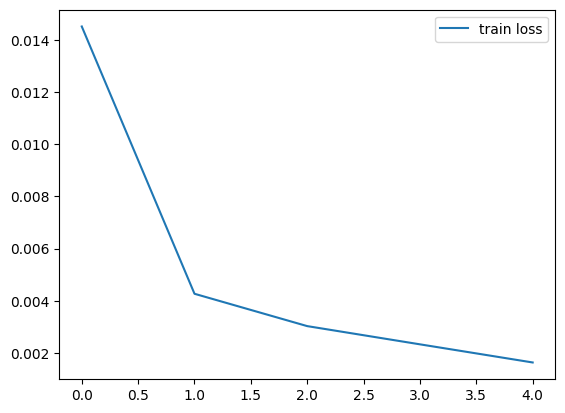
Epoch 1/5: 100%|██████████| 1875/1875 [02:23<00:00, 13.08it/s, train_loss=0.0145]
Epoch 2/5: 100%|██████████| 1875/1875 [02:12<00:00, 14.20it/s, train_loss=0.0043]
Epoch 3/5: 100%|██████████| 1875/1875 [02:09<00:00, 14.47it/s, train_loss=0.0030]
Epoch 4/5: 100%|██████████| 1875/1875 [02:09<00:00, 14.45it/s, train_loss=0.0023]
Epoch 5/5: 100%|██████████| 1875/1875 [02:08<00:00, 14.56it/s, train_loss=0.0016]
We plot the train loss recorded during training.
Show code cell source
plt.plot(history['train_loss'], label='train loss')
plt.legend()
plt.show()
Evaluation#
Since a Siamese Network learns to measure similarity rather than classify individual samples, we need to assess its performance using a different set of metrics. One common approach is to use the embeddings produced by the network to perform a k-nearest neighbors (k-NN) search. We can then evaluate the network’s performance by measuring the accuracy of the k-NN search on a test set. Another approach is to visualize the embeddings in a lower-dimensional space using a dimensionality reduction technique like t-SNE. These evaluations provide insight into how well the model generalizes and whether the learned embeddings are meaningful for downstream tasks.
Embedding generation#
Before we can evaluate the network using k-NN search or t-SNE visualization, we need to generate embeddings for both the training set and the test set. We can do this by passing each dataset through the embedding model and storing the outputs in a separate tensor. The following function generates embeddings for a given dataset using the provided model.
Show code cell source
def get_embeddings(model: nn.Module,
data: Dataset | DataLoader,
batch_size: int = 64
) -> tuple[torch.FloatTensor, torch.IntTensor]:
if isinstance(data, Dataset):
data = DataLoader(data, batch_size)
elif not isinstance(data, DataLoader):
raise ValueError('data must be a Dataset or a DataLoader')
model_device = next(model.parameters()).device
device = torch.device('cuda' if torch.cuda.is_available() else 'mps' if torch.mps.is_available() else 'cpu')
model = model.to(device)
model.eval()
embeddings = []
labels = []
with torch.inference_mode():
for x, l in data:
x = x.to(device)
y = model(x)
embeddings.append(y.cpu())
labels.append(l)
model = model.to(model_device)
return torch.cat(embeddings), torch.cat(labels)
train_embeddings, train_labels = get_embeddings(model, train_ds)
test_embeddings, test_labels = get_embeddings(model, test_ds)
k-NN search#
The k-NN search is a simple yet effective way to evaluate the quality of embeddings produced by a Siamese Network. We can use the embeddings generated for the test set to find the k-nearest neighbors of each sample in the embedding space. By comparing the predicted labels of the nearest neighbors with the true labels, we can calculate the accuracy of the k-NN search.
# Train a simple k-NN classifier
knn = KNeighborsClassifier(n_neighbors=5, metric="euclidean")
knn.fit(train_embeddings.numpy(), train_labels.numpy())
# Evaluate
preds = knn.predict(test_embeddings.numpy())
knn_accuracy = accuracy_score(test_labels.numpy(), preds)
print(f"k-NN Accuracy: {knn_accuracy:.2%}")
k-NN Accuracy: 99.26%
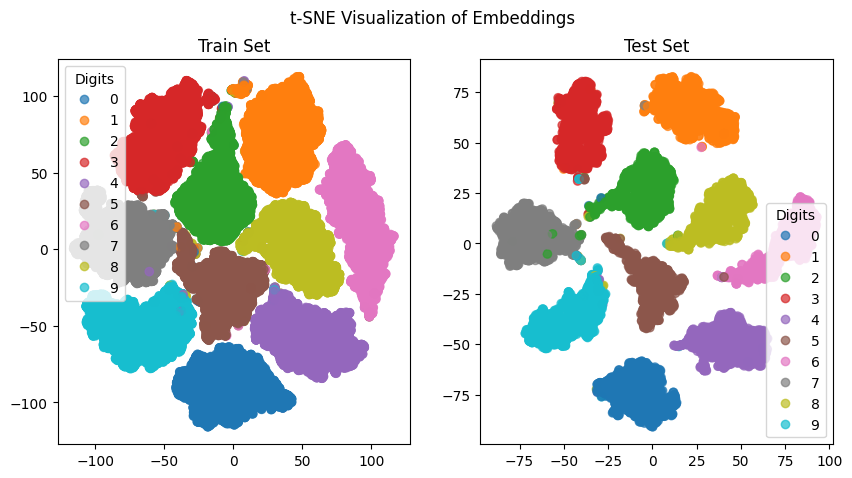
Visualization#
We will use t-SNE to visualize the embeddings produced by the network. t-SNE is a popular technique for visualizing high-dimensional data in a lower-dimensional space. It works by modeling the similarity between data points in the high-dimensional space and the low-dimensional space, then minimizing the difference between these similarities using gradient descent. This results in a 2D or 3D representation of the data that preserves the local structure of the high-dimensional space.
tsne = TSNE(n_components=2, random_state=42)
train_tsne = tsne.fit_transform(train_embeddings)
test_tsne = tsne.fit_transform(test_embeddings)
Show code cell source
plt.figure(figsize=(10, 5))
plt.suptitle("t-SNE Visualization of Embeddings")
plt.subplot(1, 2, 1)
scatter = plt.scatter(train_tsne[:, 0], train_tsne[:, 1], c=train_labels.numpy(), cmap="tab10", alpha=0.7)
plt.legend(*scatter.legend_elements(), title="Digits")
plt.title("Train Set")
plt.subplot(1, 2, 2)
scatter = plt.scatter(test_tsne[:, 0], test_tsne[:, 1], c=test_labels.numpy(), cmap="tab10", alpha=0.7)
plt.legend(*scatter.legend_elements(), title="Digits")
plt.title("Test Set")
plt.show()
Summary#
In this tutorial, we implemented a Siamese Network to compare images of handwritten digits from MNIST dataset. We defined the network architecture and the contrastive loss function. We then trained the network and evaluated it using k-NN search and t-SNE visualization to assess the quality of the learned embeddings. The results showed that the network was able to learn meaningful representations of the images, as evidenced by the high accuracy of k-NN search and the clear separation of classes in t-SNE visualization.