Part 2: Multiple Objects#
In the first part of the project, you trained a model that detects whether an object of a chosen class is present in an image and, if so, predicts a bounding box around it. While this is a useful starting point, real-world images often contain several objects, sometimes overlapping or appearing at different scales. The goal of this second part is to extend the model to predict a variable number of boxes per image, requiring changes to data preparation, model architecture, loss function, and inference. To simplify the task, you will still assume that all objects belong to the same class.
Overview#
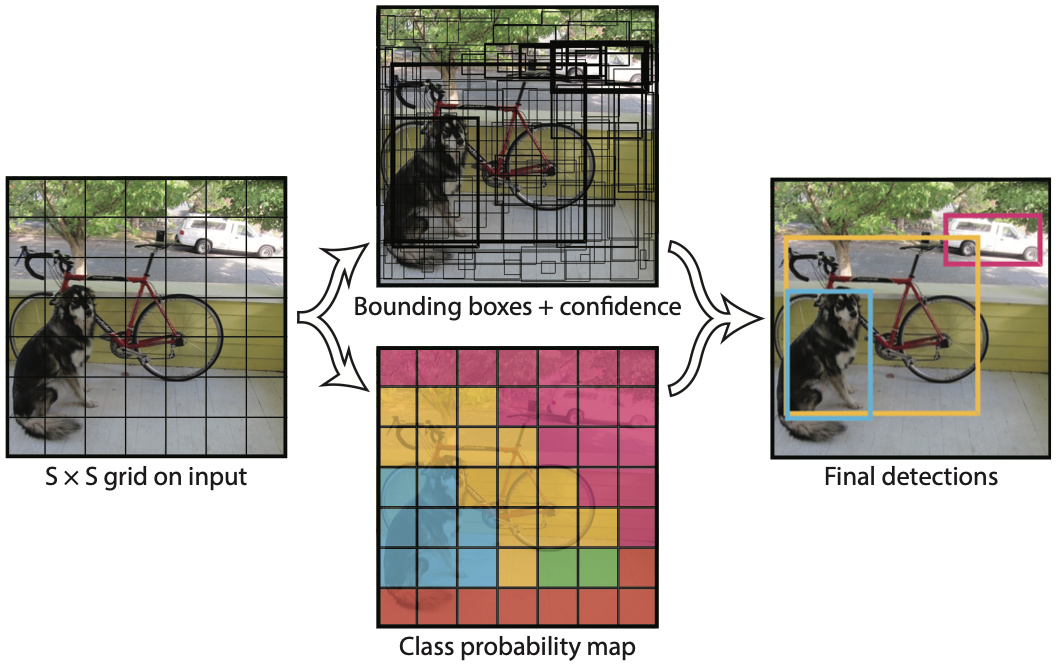
For multi-object localization, you will follow the general approach of modern one-stage detectors such as YOLO (You Only Look Once). Instead of predicting only one bounding box, the model divides the image into a grid of candidate regions and outputs predictions for each region simultaneously. Concretely, the model processes the input image through a purely convolutional network, producing a feature map where each spatial location corresponds to a grid cell in the original image. For every grid cell, the model predicts a logit score indicating the likelihood that an object is present in that cell, along with the coordinates of a bounding box relative to that cell. This dense prediction strategy allows the model to detect multiple objects within a single image, without needing to know in advance how many objects are present.
Following YOLO approach, your implementation will include the following components.
A backbone network (e.g., MobileNetV3, SSDLite) that extracts a feature map from the input image.
A detection head that operates on the feature map and outputs predictions for each cell.
A loss function that supervises both objectness and bounding box regression.
Later in the project, this design can be naturally extended to support multiple classes, making it a general-purpose detection framework, as shown in the next figure.