Evaluation#
After training the localization model, the next step is to evaluate its performance on unseen data. This involves two complementary processes: generating predictions from new images (inference) and quantitatively assessing these predictions against ground-truth annotations (evaluation).

Inference#
Inference is the process of applying the trained model to new images to detect and localize objects. The network produces predictions for every grid cell, yielding a dense set of bounding box proposals. Many of these predictions, however, are low-confidence or overlapping, which can result in multiple detections for the same object or spurious false positives. To address this, postprocessing is applied to filter unlikely predictions and resolve conflicts between overlapping boxes, producing a refined set of bounding boxes.
The overall inference process can be divided into three main stages.
Preprocessing
The input image is resized, cropped, and normalized as expected by the pretrained backbone.
Forward Pass
The preprocessed image is passed through the pretrained backbone, producing a feature map.
The feature map is then processed by the localization head, which outputs a grid of predictions consisting of objectness scores and bounding box encodings.
The bounding box encodings are decoded into absolute coordinates in the image space.
Postprocessing
Thresholding: Predictions with objectness scores below a chosen threshold are discarded to remove low-confidence detections.
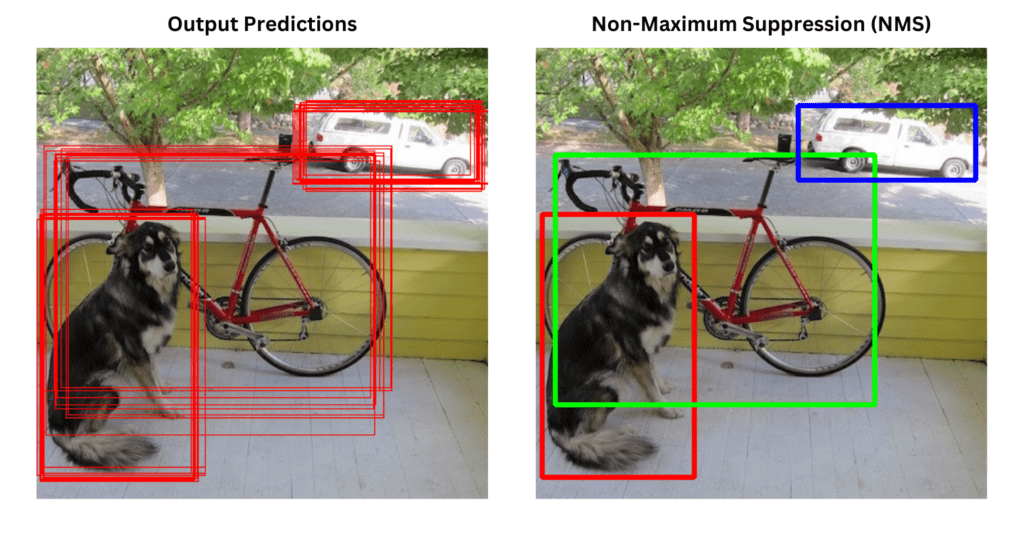
Non-Maximum Suppression: Overlapping bounding boxes are filtered by retaining the one with the highest confidence score, ensuring a single detection per object.
Rescaling (optional): The remaining bounding boxes are mapped back to the original image dimensions to produce interpretable detections.
The result of this pipeline is a set of bounding boxes for all detected objects in the image, each with an associated confidence score. Visual inspection of these outputs often provides an intuitive first impression of the model’s performance.
Note
Torchvision provides a built-in function for non-maximum suppression.
Evaluation metrics#
After performing inference on the test set, the accuracy of the detected bounding boxes needs to be quantitatively assessed through several standard metrics.
Intersection over Union (IoU)
IoU measures the overlap between predicted and ground-truth bounding boxes.
A detection is considered correct if the IoU exceeds a chosen threshold (commonly 0.5).
Precision and Recall
Precision: Fraction of predicted boxes that correctly correspond to actual objects. High precision indicates few false positives.
Recall: Fraction of ground-truth objects that are successfully detected. High recall indicates few missed detections.
Average Precision (AP)
AP summarizes the trade-off between precision and recall across different confidence thresholds.
It is computed as the area under the precision–recall curve for each class.
Mean Average Precision (mAP)
mAP is the mean of AP scores across all object classes.
Benchmarks may report mAP at a single IoU threshold (e.g., 0.5) or over a range (e.g., 0.5:0.95) to provide a comprehensive measure of accuracy.
Together, these metrics provide a complete picture of the model’s effectiveness, highlighting both its detection quality and computational efficiency.
Note
TorchEval is a library that provides standardized implementations of evaluation metrics for machine learning models, including those for object detection tasks.