Model Architecture#
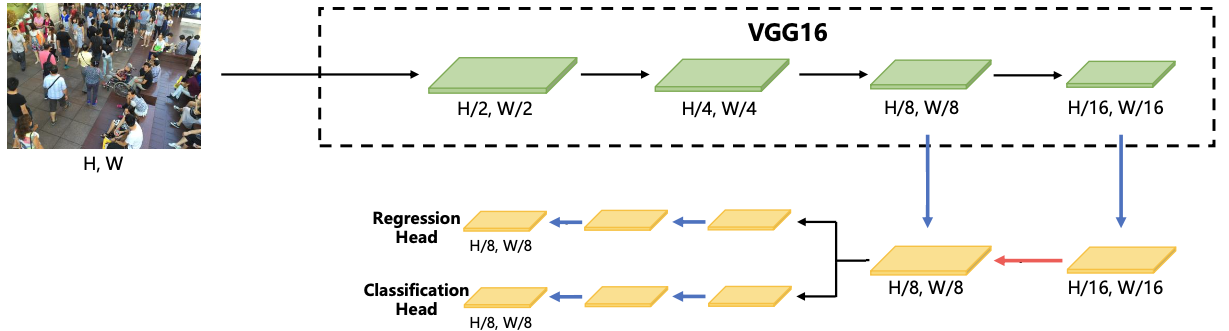
P2PNet is a convolutional neural network designed to localize individuals in crowd scenes. Unlike traditional crowd counting models, P2PNet generates a set of candidate head locations and associated confidence scores for each input image. This is achieved through an architecture composed of a backbone for extracting multi-scale features, a neck for combining these features into a unified representation, and two parallel heads for making predictions. The next sections provide an overview of the network’s architecture and a detailed breakdown of each major component.
Overview#
The P2PNet architecture consists of four main components.
The Backbone is a truncated VGG16 network that processes the input image and produces intermediate feature maps at multiple scales.
The Neck is a small Feature Pyramid Network (FPN) that combines information from different stages of the backbone.
The Head consists of two parallel sub-networks that operate on the feature map produced by the neck.
The Regression Head predicts positions with sub-pixel precision.
The Classification Head predicts the likelihood of each position corresponding to a true person.
At inference time, the model outputs a dense set of candidate points and their confidence scores. These candidates are then filtered based on their confidence scores to produce the final set of head positions, which can be used to estimate crowd counts.
Backbone#
The backbone of P2PNet extracts multi-scale feature maps from the input image by passing it through five convolutional blocks. Each block (except the first) begins with a max-pooling layer, followed by a series of convolutional layers with ReLU activations. The architecture is inherited directly from the original VGG16 network, and all layers are initialized with pretrained VGG16 weights (from ImageNet).
Block 1: Two convolutional layers, each followed by ReLU. (Indices: 0-3)
Block 2: Max-pooling, then two convolutional layers with ReLU. (Indices: 4-8)
Block 3: Max-pooling, three convolutional layers with ReLU. (Indices: 9-15)
Block 4: Max-pooling, three convolutional layers with ReLU. (Indices: 16-22)
Block 5: Max-pooling, three convolutional layers with ReLU. (Indices: 23-29)
The backbone outputs the feature maps produced by the fourth and fifth blocks. Their spatial dimensions are H/8 × W/8 and H/16 × W/16, respectively, where H and W are the height and width of the input image. These feature maps are then passed to the neck for further processing.
Note
The P2PNet backbone corresponds to the layers with indices 0 to 29 (inclusive) in the pretrained VGG-16 model from torchvision.models. The last pooling layer (index 30) is excluded.
==========================================================================================
Layer (type (var_name)) Output Shape Param #
==========================================================================================
VGG (VGG) [1, 1000] --
├─Sequential (features) [1, 512, 7, 7] --
│ └─Conv2d (0) [1, 64, 224, 224] 1,792
│ └─ReLU (1) [1, 64, 224, 224] --
│ └─Conv2d (2) [1, 64, 224, 224] 36,928
│ └─ReLU (3) [1, 64, 224, 224] --
│ └─MaxPool2d (4) [1, 64, 112, 112] --
│ └─Conv2d (5) [1, 128, 112, 112] 73,856
│ └─ReLU (6) [1, 128, 112, 112] --
│ └─Conv2d (7) [1, 128, 112, 112] 147,584
│ └─ReLU (8) [1, 128, 112, 112] --
│ └─MaxPool2d (9) [1, 128, 56, 56] --
│ └─Conv2d (10) [1, 256, 56, 56] 295,168
│ └─ReLU (11) [1, 256, 56, 56] --
│ └─Conv2d (12) [1, 256, 56, 56] 590,080
│ └─ReLU (13) [1, 256, 56, 56] --
│ └─Conv2d (14) [1, 256, 56, 56] 590,080
│ └─ReLU (15) [1, 256, 56, 56] --
│ └─MaxPool2d (16) [1, 256, 28, 28] --
│ └─Conv2d (17) [1, 512, 28, 28] 1,180,160
│ └─ReLU (18) [1, 512, 28, 28] --
│ └─Conv2d (19) [1, 512, 28, 28] 2,359,808
│ └─ReLU (20) [1, 512, 28, 28] --
│ └─Conv2d (21) [1, 512, 28, 28] 2,359,808
│ └─ReLU (22) [1, 512, 28, 28] --
│ └─MaxPool2d (23) [1, 512, 14, 14] --
│ └─Conv2d (24) [1, 512, 14, 14] 2,359,808
│ └─ReLU (25) [1, 512, 14, 14] --
│ └─Conv2d (26) [1, 512, 14, 14] 2,359,808
│ └─ReLU (27) [1, 512, 14, 14] --
│ └─Conv2d (28) [1, 512, 14, 14] 2,359,808
│ └─ReLU (29) [1, 512, 14, 14] --
│ └─MaxPool2d (30) [1, 512, 7, 7] --
├─AdaptiveAvgPool2d (avgpool) [1, 512, 7, 7] --
├─Sequential (classifier) [1, 1000] --
│ └─Linear (0) [1, 4096] 102,764,544
│ └─ReLU (1) [1, 4096] --
│ └─Dropout (2) [1, 4096] --
│ └─Linear (3) [1, 4096] 16,781,312
│ └─ReLU (4) [1, 4096] --
│ └─Dropout (5) [1, 4096] --
│ └─Linear (6) [1, 1000] 4,097,000
==========================================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
Total mult-adds (Units.GIGABYTES): 15.48
==========================================================================================
Input size (MB): 0.60
Forward/backward pass size (MB): 108.45
Params size (MB): 553.43
Estimated Total Size (MB): 662.49
==========================================================================================
Tip
In PyTorch, to select specific layers from a pretrained VGG16 model, you can proceed as follows.
Import the necessary modules.
from torchvision.models import vgg16, VGG16_Weights
Initialize the VGG16 model with pretrained weights.
model = vgg16(weights=VGG16_Weights.DEFAULT)
Extract the layers in the desired index range from the VGG16 feature extractor.
block1 = model.features[0:4] # This includes layers from index 0 to 3 block2 = ... block3 = ... block4 = ... block5 = ...
You can print the blocks to visualize the architecture and confirm the layer indices.
print(block1) ...
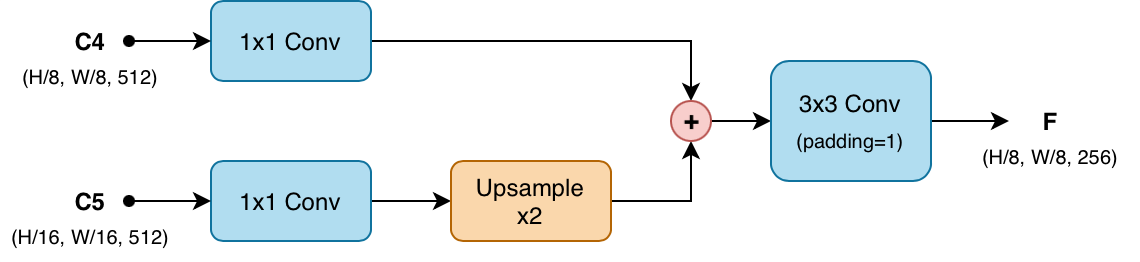
Neck#
The neck of P2PNet is a lightweight module that combines the two backbone outputs into a single refined feature map. It follows a simplified Feature Pyramid Network (FPN) design, where higher-level features are merged with lower-level features via upsampling. As mentioned earlier, the neck takes as input the feature maps from the fourth and fifth blocks of the backbone, denoted as C4 and C5, with spatial dimensions H/8 × W/8 and H/16 × W/16, respectively. The fusion proceeds in three steps.
Channel Reduction.
The input feature map
C4is passed through a 1x1 convolutional layer to reduce its channel dimension from 512 to 256.The input feature map
C5is passed through a 1x1 convolutional layer to reduce its channel dimension from 512 to 256.
Upsampling and Merging.
The reduced
C5is upsampled by a factor of 2 using nearest-neighbor interpolation to match the spatial dimensions ofC4.The upsampled
C5is element-wise added to the reducedC4to produce a merged feature map.
Refinement.
The merged feature map is further processed by a 3x3 convolutional layer with padding=1.
This produces a H/8 × W/8 feature map with 256 channels.
Head#
The head of P2PNet consists of two parallel sub-networks that operate on the feature map produced by the neck. Both sub-networks share a similar architecture, consisting of a series of convolutional layers with ReLU activations. The key difference lies in their output: the regression head predicts two-dimensional vectors that indicate where people are located in the image, while the classification head predicts confidence scores indicating the likelihood of a true person being present at those location.
Note
The head produces two prediction maps with a stride of 8 relative to the input image. Each spatial location in these prediction maps corresponds to an 8x8 patch in the original image.
Regression Head#
The regression head takes a feature map as input and outputs a prediction map with the same height and width, but with 2 × N channels, where N is the number of candidate points per spatial location. For an input image of size W × H, the regression head effectively predicts a dense set of W/8 × H/8 × N candidate points. Each candidate is a two-dimensional offset (Δx, Δy) that indicates the predicted location of a person relative to the center of the corresponding 8x8 patch in the original image. (More details on how these offsets are used during inference will be provided later.)
Internally, the regression head consists of three convolutional layers:
The first layer is a 3×3 convolution with padding 1 that maps the input channels to an intermediate number of channels (usually 256), followed by a ReLU activation.
The second layer is another 3×3 convolution with padding 1 that keeps the same number of channels, again followed by a ReLU.
The third layer is a 3×3 convolution with padding 1 that reduces the channels to 2 × N.
Classification Head#
The classification head takes a feature map as input and outputs a prediction map with the same height and width, but with N channels. For an input image of size W × H, the classification head effectively predicts a dense set of W/8 × H/8 × N confidence scores. Each score indicates how likely it is that the corresponding candidate location predicted by the regression head represents a true person in the image.
Internally, the classification head consists of three convolutional layers:
The first layer is a 3×3 convolution with padding 1 that maps the input channels to an intermediate number of channels (usually 256), followed by a ReLU activation.
The second layer is another 3×3 convolution with padding 1 that keeps the same number of channels, again followed by a ReLU.
The third layer is a 3×3 convolution with padding 1 that reduces the channels to N.
Summary#
The P2PNet architecture consists of a backbone, neck, and head that work together to produce dense predictions of candidate locations and their confidence scores. Rather than directly regressing (x, y) coordinates for each person, P2PNet predicts offsets from a grid of anchor points. In the next chapter, you will see how these predicted offsets are decoded into head locations in the original image space, matched with ground-truth annotations, and used to define the training loss.