Training#
The P2PNet architecture produces, for each input image, a set of candidate head locations and associated confidence scores. Training the network therefore requires more than a simple pixel-wise loss. We need a way to decide which prediction should be responsible for which ground-truth head, and penalize both localization errors and classification errors in a consistent way. This is typically done using a matching algorithm, which assigns each ground-truth head to a predicted location based on some criteria. Once the assignments are made, we can evaluate the localization and classification errors over the matched pairs, and use these errors to compute the overall loss function for training.
Point matching#
For a given training image, suppose there are \(N\) annotated heads (targets), represented as points
After passing the image through P2PNet, we obtain:
a tensor of predicted offsets of shape \((2, A, H_f, W_f)\), where \(A\) is the number of anchors per grid cell, and \(H_f, W_f\) are are the spatial dimensions of the prediction grid;
a tensor of logits (classification scores before sigmoid) of shape \((A, H_f, W_f)\).
Decoding the offsets yields a set of \(M = A \times H_f \times W_f\) predicted points
together with their associated confidence scores \(\hat{c}_j\).
Both the targets and the predictions are unordered sets of points. The network does not predict an explicit ordering, and the number of predictions is typically larger than the number of heads (\(M > N\)). This makes training fundamentally different from standard regression: we cannot simply line up predictions and targets by index and apply a mean squared error. Instead, we must first decide which prediction should be matched to which ground-truth point.
Linear assignment#
P2PNet uses a one-to-one assignment between predicted points and ground-truth points. Each ground-truth point is matched to at most one prediction, and each prediction is matched to at most one ground truth. This is known as a linear assignment problem. To solve this problem optimally, we need to define a matrix where each entry represents the cost of matching a prediction \(\hat{p}_j\) with a target \(p_i\).
The simplest choice to build such a cost matrix would be to consider only the Euclidean distance between each pair of predicted and target points. However, we also care about the confidence score: a good positive match should not only be close to the ground truth, but also have a high predicted confidence. P2PNet combines both aspects in a single matching cost of the form
where \(\tau > 0\) is a hyperparameter that balances the influence of distance and score. A lower cost is better, meaning that points closer to the ground truth and with higher scores are preferred.
Note
Make sure to use the sigmoid of the logits when computing the cost, not the raw logits.
Implementation#
The assignment problem can be solved with the scipy.optimize.linear_sum_assignment function. The code snippet below illustrates how to use this function, given the cost matrix computed as above. In practice, it is common to ensure that \(M \ge N\), so that each target can be matched to some prediction.
import torch
from scipy.optimize import linear_sum_assignment
def hungarian_matching(cost: torch.Tensor):
"""
Given a cost matrix, compute the optimal one-to-one matching.
Parameters
----------
cost: torch.Tensor
A 2D tensor where each element represents the cost of assigning each target to each prediction.
Returns
-------
row_ind: torch.Tensor
Indices of the matched points representing the rows of the cost matrix.
col_ind: torch.Tensor
Indices of the matched points representing the columns of the cost matrix.
"""
# Compute the optimal assignment
cost_np = cost.cpu().detach().numpy()
row_ind, col_ind = linear_sum_assignment(cost_np)
# Convert the matched indices to torch tensors
row_ind = torch.tensor(row_ind, dtype=torch.int64, device=cost.device)
col_ind = torch.tensor(col_ind, dtype=torch.int64, device=cost.device)
return row_ind, col_ind
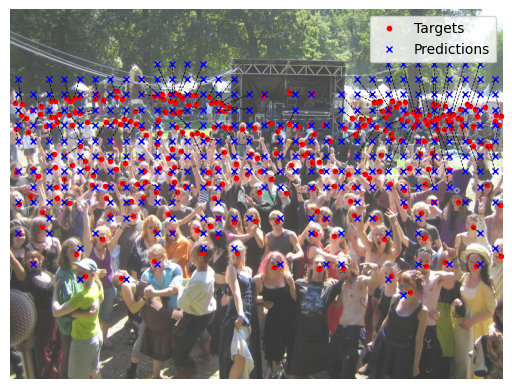
The figure below illustrates the matching process. The red circles are the targets, while the blue crosses are the matched predictions. Dashed lines connect each target to its assigned prediction.
Loss function#
The loss function for one image is computed as the sum of the localization error over the matched pairs and the classification error over all predictions. Mathematically, this can be expressed as
where \(\lambda\) is a small coefficient that controls the relative importance of localization compared to classification. This coefficient is chosen so that both terms have comparable numerical scale during training.
Localization loss#
The localization loss encourages the network to adjust the offsets of matched predictions such that they align closely with the ground-truth head locations. This is done by penalizing the mean squared distance between each ground-truth point \(p_i\) and its matched prediction \(\hat{p}_{\xi(i)}\), where \(\xi(i)\) is the index of the prediction assigned to target \(i\).
Here, \(K\) is the number of matched pairs, which is typically the number of ground-truth heads (\(K=N\)). The following code snippet shows how to compute the localization loss in PyTorch.
cost = compute_cost_matrix(targets, preds, logits, tau) # shape (N, M)
true_idx, pred_idx = hungarian_matching(cost)
matched_targets = targets[true_idx] # shape (N, 2)
matched_preds = preds[pred_idx] # shape (N, 2)
loc_loss = torch.nn.functional.mse_loss(matched_preds, matched_targets)
Note
This loss only penalizes matched predictions. Unmatched proposals are not used.
Classification loss#
The classification loss encourages the network to assign high confidence scores to matched predictions, and low scores to unmatched predictions. This is implemented as a binary classification problem, where each prediction is classified as either positive or negative based on whether it has been assigned to a ground-truth point in the matching process. Let \(\hat{c}_j\) be the raw logit output for prediction \(j\), and let \(y_j \in \{0, 1\}\) be its label. That is, \(y_j = 1\) if the index \(j\) is in the set of matched prediction indices, and \(y_j = 0\) otherwise. The binary cross-entropy with logits averaged over all predictions reads as follows.
Here, \(\lambda_{\rm neg}\) is a hyperparameter that controls the contribution of negative samples in the loss. This is useful to address class imbalance, since most predictions are expected to be negatives (i.e., not matched to any ground-truth point). The following code snippet shows how to compute the classification loss in PyTorch.
labels = torch.zeros_like(logits)
labels[pred_idx] = 1.0 # set positive labels for matched predictions
weights = torch.full_like(logits, lambda_neg)
weights[pred_idx] = 1.0
cls_loss = torch.nn.functional.binary_cross_entropy_with_logits(logits, labels, weight=weights)
Note
This loss takes into account all predictions, both matched and unmatched.
Summary#
Putting all pieces together, a single training iteration for one batch proceeds as follows:
Forward pass. Feed a batch of images through P2PNet to obtain offsets and logits. Decode the offsets into predicted coordinates in image space.
Point matching. For each image in the batch, build the cost matrix between its predicted points and ground-truth points; run the Hungarian algorithm to obtain the one-to-one matching; collect the matched and unmatched prediction indices.
Loss function. For each image, compute the localization loss on matched pairs and the classification loss on all predictions, using the labels derived from the matching. Average losses over the batch.
Backward pass. Combine the two losses with the chosen weighting, backpropagate, and update the network parameters using your optimizer of choice.
With this training objective, P2PNet learns to produce a set of point proposals such that, after optimal matching, each ground-truth head is explained by exactly one confident, well-localized prediction, and spurious proposals are assigned low confidence and treated as background.
Tip
Follow a training strategy similar to fine-tuning to improve stability.
Start from a P2PNet model initialized with pretrained VGG-16 weights, and initially freeze the backbone so that only the neck and prediction heads are updated. Train this configuration until the loss stabilizes and the model begins to produce reasonable matches.
Then unfreeze the backbone and continue training the entire network end-to-end, typically with a smaller learning rate.