5.4.3. Simplex#
For a given scalar \(\xi\ge0\), the simplex is a linear constraint defined as
where \({\bf 1}=[1\;\dots\;1]^\top \in \mathbb{R}^N\) is the vector with all elements to 1. The condition \(\xi \ge 0\) allows this subset to be nonempty. The figure below shows how this constraint looks like in \(\mathbb{R}^{2}\) or in \(\mathbb{R}^{3}\).
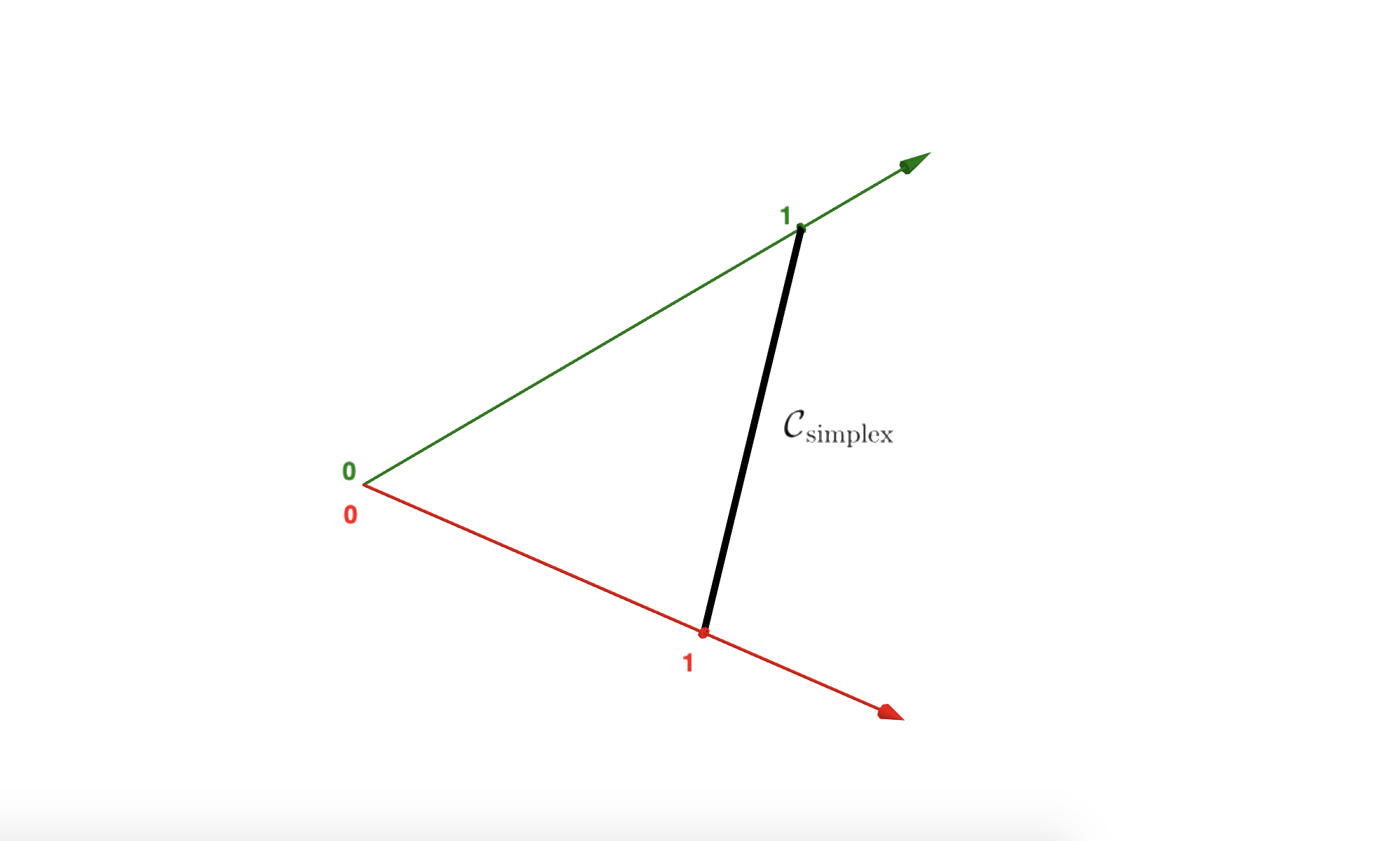
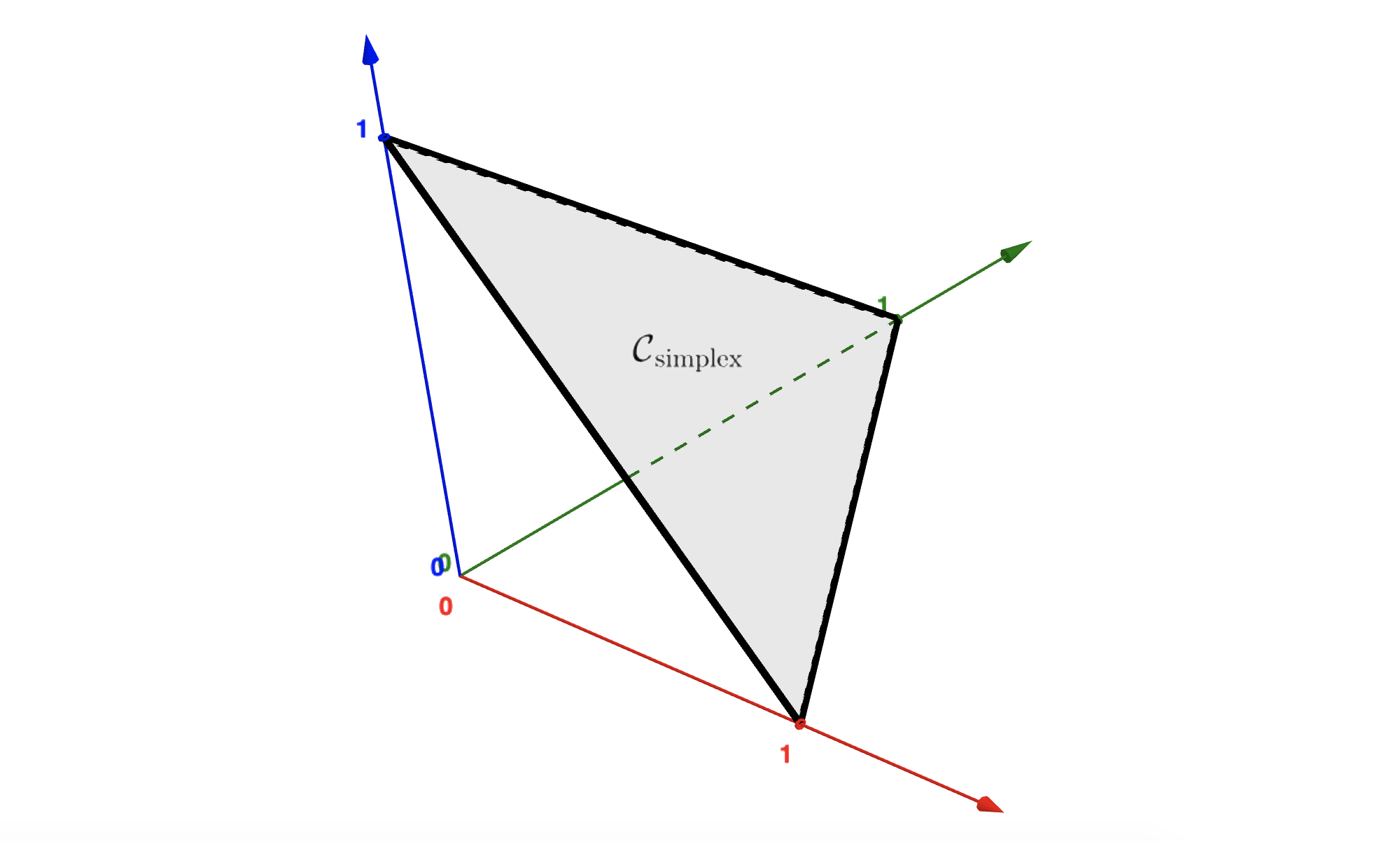
5.4.3.1. Constrained optimization#
Optimizing a function \(J({\bf w})\) subject to the simplex can be expressed as
The figure below visualizes such an optimization problem in \(\mathbb{R}^{2}\).
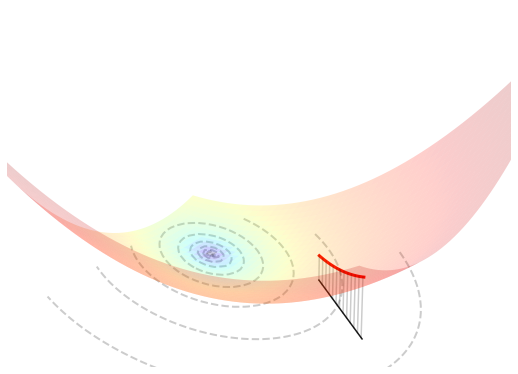
5.4.3.2. Orthogonal projection#
The projection of a point \({\bf u}\in\mathbb{R}^{N}\) onto the simplex is the (unique) solution to the following problem
The solution can be computed as follows.
Projection onto the simplex
The value \(\lambda \in \mathbb{R}\) is the unique solution of the equation
which can be easily determined in two steps:
Sort \({\bf u}\) into \({\bf \tilde{u}}\) so that \(\tilde{u}_1 \ge \dots \ge \tilde{u}_N\),
Set \(\lambda = \max_n\big\{(\tilde{u}_1+\dots+\tilde{u}_n - \xi) \,/\, n\big\}\).
Knapsack
A more general version of the simplex is called the knapsack:
The projection onto this convex set is known as the continuous quadratic knapsack problem. If you ever need it, there exist numerical methods to efficiently compute this projection.
5.4.3.3. Implementation#
The python implementation is given below.
def project_simplex(u, bound):
assert bound >= 0, "The bound must be non-negative"
s = np.sort(u.flat)[::-1]
c = (np.cumsum(s) - bound) / np.arange(1, np.size(u)+1)
# i = np.count_nonzero(c < s)
# l = c[i-1]
l = np.max(c)
p = np.maximum(0, u - l)
return p
Here is an example of use.
u = np.array([5, 4, 1, 3, 2, 6])
p = project_simplex(u, bound=8)
5.4.3.4. Proof#
By using the Lagrange multipliers to remove the equality constraint, the projection onto the simplex is the (unique) solution to the following problem
Strong duality holds, because this is a convex problem with linear constraints. Hence, it can be equivalently rewritten as
Taking advantage of the element-wise separability, the inner minimization is solved by projecting \({\bf u} - \lambda {\bf 1}\) onto the non-negative orthant:
Setting to zero the gradient w.r.t. \(\lambda\), the outer maximization is attained by the scalar \(\lambda\) that solves the equation
Without loss of generality, assume that \({\bf u}\) is sorted into \({\bf \tilde{u}}\) in descending order \(\tilde{u}_1 \ge \dots \ge \tilde{u}_N\), and define the solution \({\bf \tilde{w}}=\max\{{\bf 0}, {\bf \tilde{u}} - \lambda {\bf 1}\}\) using the same ordering as \({\bf \tilde{u}}\). Moreover, denote by \(\rho\in\{1,\dots,N\}\) the number of positive components in the solution, so that \(\tilde{w}_1 \ge \dots \ge \tilde{w}_\rho > 0\) and \(\tilde{w}_{\rho+i} = 0\) for every \(i\ge1\). The reordered solution is such that
from which we deduce
Hence, the index \(\rho\) is the key to the solution, and luckly there are only \(N\) possible candidates
To evaluate such candidates, consider the function
which is equal to \(\xi\) at the optimal \(\lambda\). Evaluating this function on \(\lambda_k\) yields
where \(\rho_k = \max\{n \,|\, \tilde{u}_n > \lambda_k\}\) is the number of times an element \(\tilde{u}_n\) is greater than \(\lambda_k\). A simple calculation shows that \(h(\lambda_k) = \xi\) if and only if \(\rho_k = k\), which is exactly how the optimal \(\lambda\) was defined. Hence, the sought index \(\rho\) can be determined as
TODO: prove that \(\rho = \arg\max_k \lambda_k\).