Example 1#
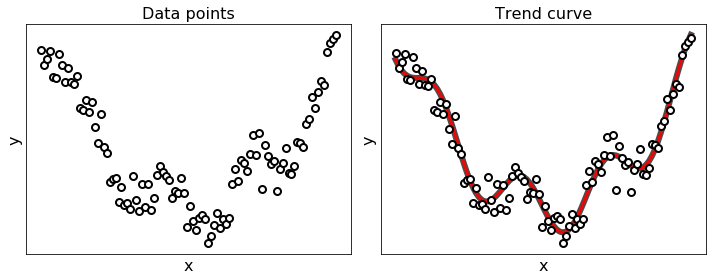
Let’s consider the problem of regression, that is the fitting of a representative curve to a given set of data points, as shown in the figure below. Regression in general may be performed for a variety of reasons: to produce a so-called trend curve that can be used to help visually summarize, drive home a particular point about the data under study, or to learn a model so that precise predictions can be made regarding output values in the future.
General approach#
The data points for a regression problem come in the form of \(P\) input/output observation pairs
Note that the inputs \({\bf x}^{(p)}\) are vectors of length \(N\), whereas the outputs \(y^{(p)}\) are real numbers
The fundamental assumption is that the output \(y^{(p)}\) depends on the input \({\bf x}^{(p)}\) through an unknown relationship \(f\colon\mathbb{R}^N\to\mathbb{R}\) that is measurable in a noisy environment. Assuming the noise follows a normal distribution with zero mean and \(\sigma^2\) variance, this leads to the stochastic relationship
The idea is to approximate the unknown relationship with a parametric function that depends on some weights \({\bf w}\). Several models exist for this purpose, and they will be discussed in more detail later. Regardless of the chosen model, its parameters must be adjusted so that the following approximate equalities hold between the input/output data points
Since the observed outputs are Gaussian distributed, it is statistically sound to minimize the mean square error between the observed outputs and model predictions at the given inputs, leading to the following optimization problem
The cost function only depends on the parameters \({\bf w}\), because the data points are constant for a given regression task.
Linear model#
To solve a regression problem, the parametric model must be precisely defined in mathematical terms. The simplest model imaginable is the hyperplane controlled by an intercept \(w_0\) and several slopes \(w_1,\dots,w_N\) (one for each input coordinate), yielding the linear relationship written as
Solving a linear regression problem consists of finding the \(N+1\) weights \(\mathbf{w}=[w_0,w_1,\dots,w_N]^\top\) that minimize the mean square error between the observed outputs and the predictions of the linear model at the given inputs.
Example: one-dimensional linear model
In the running example, the inputs are scalar values (\(N=1\)), so the linear model boils down to
Cost function
Note that the input vectors and the output scalars of a given dataset can be stacked into a matrix \({\bf X}\) and a vector \({\bf y}\) as follows
The mean square error incurred by the linear moder over all the dataset can be written as
This is a convex function with a unique minimum, provided that the matrix \({\bf X}\) is full column rank. It is also Lipschitz differentiable, because the Hessian matrix is constant, and thus the function curvature is upper bounded by the maximum eigenvalue
The choice of stepsize \(\alpha<2/L\) guarantees the convergence of gradient descent for solving this problem.
The figure below illustrates the process of solving the linear regression problem with gradient descent. The left panel shows how the linear model fits the data using the weights generated at the \(k\)-th iteration of gradient descent, whereas the right panel shows the convergence plot up to the \(k\)-th iteration. Pushing the slider to the right animates gradient descent from start to finish, with the best fit occurring at the end of the run, when the minimum of the cost function is being attained. Note that the linear model is a poor choice for this dataset, because the underlying relationship is clearly nonlinear.
Extended linear model#
There is a simple trick to enhance the prediction capability of a linear model. It consists of taking a linear combination of simple nonlinear functions, whose number \(B\) is arbitrary fixed, yielding
When the functions \(f_b({\bf x})\) do not have internal parameters, this model remains linear with respect to the weights \(\mathbf{w}\). Nonetheless, the model can be made nonlinear with respect to \({\bf x}\) by appropriately choosing the functions \(f_b({\bf x})\). This kind of practice is referred to as feature engineering. An interesting choice is to use polynomial transformations, where each function \(f_b({\bf x})\) raises the input coordinates to the power of some values (possibly zero), such as
Just like before, the goal is to find the \(B+1\) weights \(\mathbf{w}=[w_0,w_1,\dots,w_B]^\top\) that minimize the mean square error between the observed outputs and the predictions of the extended model at the given inputs. Fortunately, this task is equivalent to solving a linear regression problem after a transformation of the input vectors.
Example: one-dimensional quadratic model
In the running example, it looks like the appropriate model is a quadratic polynomial, which can be obtained by setting \(B=2\), \(f_1(x)=x\), and \(f_2(x)=x^2\). This yields
Cost function
Note that the transformed input vectors can be stacked into the matrix
The mean square error incurred by the extended linear moder over all the dataset can be written as
This is a convex function with a unique minimum, provided that the matrix \({\bf X}_{\bf f}\) is full column rank. It is also Lipschitz differentiable with constant
The choice of stepsize \(\alpha<2/L\) guarantees the convergence of gradient descent for solving this problem.
The figure below illustrates the process of solving the polynomial regression problem with gradient descent. The left panel shows how the quadratic model fits the data using the weights generated at the \(k\)-th iteration of gradient descent, whereas the right panel shows the convergence plot up to the \(k\)-th iteration. Pushing the slider to the right animates gradient descent from start to finish, with the best fit occurring at the end of the run, when the minimum of the cost function is being attained. Note that the quadratic model does a good job at capturing the general trend of the data points.
Universal nonlinear model#
The fundamental issue with the extended linear model is the difficulty of feature engineering, because it strongly depends on the level of knowledge regarding the problem under study. This motivates an alternative approach known as feature learning, whose goal is to automate the process of identifying appropriate nonlinear features for arbitrary datasets. Doing so requires a manageable collection of universal approximators, of which three strains are popularly used: fixed-shape approximators, neural networks, or decision trees. As for the neural networks, the universal nonlinear model is defined as a linear combination of nonlinear functions, whose number \(B\) is arbitrary fixed, yielding
The peculiarity of such model is that each term \(g({\bf x}, \mathbf{w}_b)\) depends on its own set of parameters \(\mathbf{w}_b\). In the context of neural networks, a popular nonlinear term is the rectified linear function (relu) defined as
Solving a nonlinear regression problem consists of finding the \((N+2)B+1\) weights \(\mathbf{w}=({\bf w}_0, {\bf w}_1, \dots, {\bf w}_B)\) that minimize the mean square error between the observed outputs and the predictions of the nonlinear model at the given inputs.
Example: one-dimensional nonlinear model
In the running example, the inputs are scalar values (\(N=1\)), so the universal nonlinear model boils down to
Cost function
Note that the internal parameters can be stacked into the matrix
and the intermediate features can be stacked into the matrix
The mean square error incurred by the nonlinear moder over all the dataset can be written as
This is a nonconvex function with multiple local minima, which can be optimized by gradient descent.
The figure below illustrates the process of solving the nonlinear regression problem with gradient descent. The left panel shows how the nonlinear model fits the data using the weights generated at the \(k\)-th iteration of gradient descent, whereas the right panel shows the convergence plot up to the \(k\)-th iteration. Pushing the slider to the right animates gradient descent from start to finish, with the best fit occurring at the end of the run, when the minimum of the cost function is being attained. Note that the nonlinear model does a great job at capturing the relationship underlying the data points.